Data Wrangling
데이터 랭글링은 분석을 하거나 모델을 만들기 전에 데이터를 사용하기 쉽게 변형하거나 맵핑하는 과정이다. 보통 모델링 과정 중 가장 많은 시간이 소요되는 단계라고 할 수 있다.
- EDA, Feature Engineering과 비슷한 과정을 거치지만, 같은 과정이 아니다.
groupby,merge등의 함수를 사용해 데이터를 통합하거나 의미 있는 특성을 가지는 학습 데이터를 만들어낸다.
EDA vs Data Wrangling
-
EDA
: 머신러닝 전에 이루어지는 과정으로 머신러닝의 모델이 데이터를 학습할 수 있도록 만들어주는 과정이다.ex) 스케일링, 로그변환, 인코딩, 중복값, 이상치, 결측치 처리 등...
-
Data Wrangling
: 데이터 자체의 의미를 도출하는 시각화를 포함하며, 데이터를 분할하지 않고 전체를 사용한다.ex) 마케팅 팀에서 데이터의 패턴, 인사이트, 정보 등을 추출해서 보여줄 때
Example
한 id에 속하는 여러 item을 그룹화 해 한 줄로 나타내고, 특정 item이 포함되어 있는지 T/F로 나타내기
바나나(product_id = 24852)가 포함되어 있는지 True, False로 나타내는 새로운 이진 특성(banana) 만들어보기
# 바나나가 있으면 True, 바나나가 없으면 False인 특성 만들기
id_Banana = 24852
train['banana'] = train['product_id'] == id_Banana
train['banana'].value_counts(normalize=True)주문(order_id)별 바나나 구입 비율 구하기
# 방법 1: apply 함수 사용하기
# apply 함수는 데이터프레임에 축(axis)을 기준으로 특정한 함수를 적용하는 method
#최근 주문 별로 몇 개의 제품을 구입했는지 확인
train.groupby('order_id')['product_id'].count()
#주문 별 구입한 제품들의 product_id를 리스트로 얻기
train.groupby('order_id')['product_id'].apply(list)
#람다함수는 주문에 바나나가 있는 경우 True를 리턴한다.
train.groupby('order_id)['product_id'].apply(lamda x: id_Banana in list(x)).value_counts(normalized = True)
# 방법 2: groupby 함수 사용하기
# any()를 사용하면 banana==Ture인 제품이 하나라도 있으면 True를 리턴한다.
train.groupby('order_id')['banana'].any().value_counts(normalize=True)groupby는 여러 유용한 method들이 많으니 잘 확인해보자.
feature들 간의 상관관계 파악하기
target과 feature의 상관관계 파악하기
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
(pd.get_dummies(df).corr()['Churn']).sort_values(ascending=False).plot(kind='bar');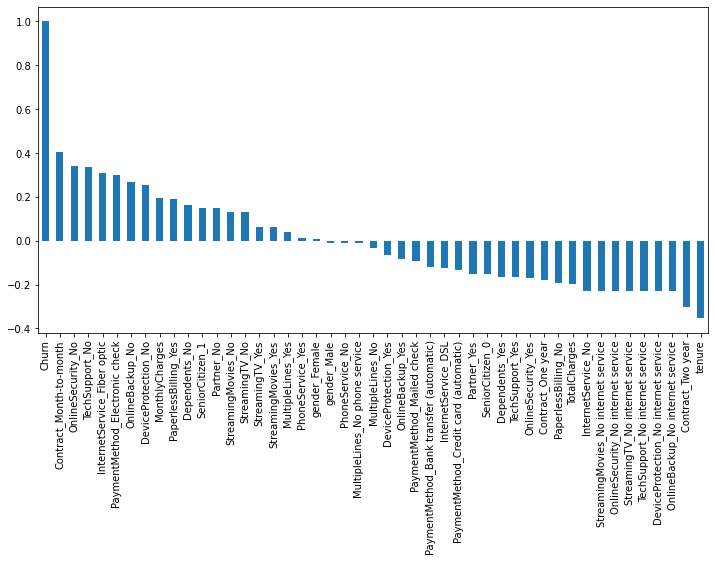
numeric feature간의 상관관계 파악하기
import seaborn as sns
ax = sns.heatmap(df[num_features].corr(), cmap='twilight_shifted', vmin=-1, vmax=1, annot=True)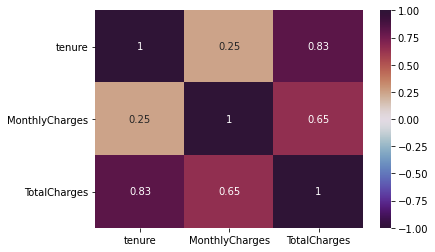

💛 공부 블로그 💛