사실 공식문서만큼 잘 설명된 것이 어디있겠냐만 그 방대한 내용과 내가 풀고 싶은 문제에 잘 적용하고 싶은 것이 사람마음인지라 좀좀따리 복습을 하는 중이다.
실습을 할 때 해당 모듈을 가장 많이 쓸 때는 데이터를 훈련용과 테스트용으로 분리할 때이다.
- 학습 데이터 세트
- 모델학습을 위해 사용
- 데이터의 속성(feature)와 결정값(label,target) 모두 포함
- 테스트 데이터 세트
- 학습된 모델 성능 테스트용
- 결정값 예측
train_test_split(feature_dataset,label_dataset, test_size, train_size, random_state, shuffle, stratify)train_test_split() 반환값
- X_train : 학습용 피처 데이터 세트 (feature)
- X_test : 테스트용 피처 데이터 세트 (feature)
- y_train : 학습용 레이블 데이터 세트 (target)
- y_test : 테스트용 레이블 데이터 세트 (target)
- feature : 대문자 X_
- label(target) : 소문자 y_
데이터의 분포에 따라서 모델의 성능은 상이하다.
또한 학습 데이터를 전체 데이터로 하면 과적합이 일어나는 등 여러 문제점이 있기 대문에 예측은 테스트 데이터로, 그 예측값과 실제값의 차이를 어떻게 줄일 것인지 고민하면서 여러 방법론과 평가지표를 활용할 수 있다.
교차검증(cross validation : cv)

- 여러 세트로 구성된 학습 데이터 세트와 검증 데이터 세트에서 학습과 평가를 수행한다.
- k-fold cross validation
- 전체 데이터 세트를 임의로 K개의 그룹으로 나누고, 그 가운데 하나의 그룹을 돌아가면서 테스트 데이터 세트로, 나머지 k-1개의 그룹은 학습용 데이터 세트로 활용하는 방법이다.
목적
- 데이터에 적합한 모델인지 평가
- 모델에 적절한 하이퍼파라미터 찾아서 모델 튜닝
- 과대적합 예방
- 데이터 편중 방지
교차 검증 방법
- k-fold cross validation
- stratified k-fold cross validation
1) k-fold cross validation
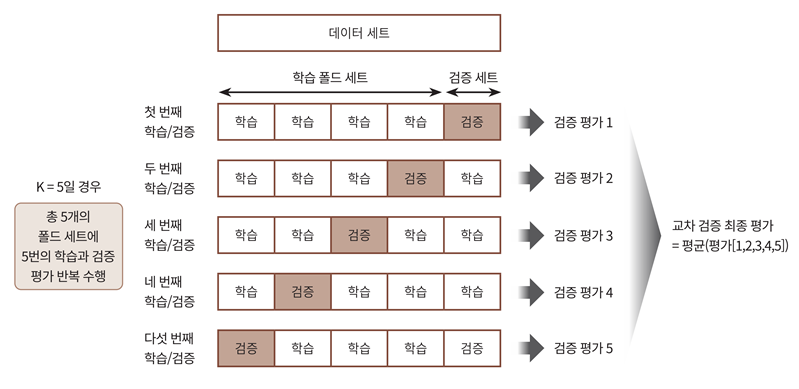
- k개의 데이터 폴드 세트를 만들어서 k번만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행.
- 가장 보편적으로 사용되는 교차 검증 기법
sklearn.model_selection.KFold(n_splits=5, *, shuffle=False, random_state=None)① KFold 클래스 : 폴드 세트로 분리하는 객체 생성
kfold = KFold(n_splits=5)② split() 메소드 : 폴드 데이터 세트로 분리
kfold.split(features)- 각 폴드마다
학습용, 검증용, 테스트 데이터 추출
학습용 및 예측 수행
정확도 측정
③ 최종 평균 정확도 계산
2) stratified k-fold cross validation
불균형한 분포도를 가진 레이블(결정 클래스) 데이터 집합을 위한 k-fold cross validation의 방법이다.
- 원본 데이터의 레이블 분포도 특성을 반영한 학습 및 검증 데이터 세트 생성
- 분류(Classification)에서의 교차 검증은 K 폴드 보다는 Stratified K 폴드 사용하는 것이 효과적
- 회귀(Regression)에서는 Stratified K 폴드 지원되지 않음
- 회귀 모델의 target값은 범주형이 아닌 수치형이므로
불균형한 데이터 문제
- 관심 대상 데이터가 상대적으로 매우 적은 비율로 나타나는 데이터 문제
- 분류 문제인 경우: 클래스들이 균일하게 분포하지 않은 문제를 의미
- 예) 불량률이 1% 정도로 매우 낮은 생산라인에서 양품과 불량품을 예측하는 문제
- 사기탐지(fraud detection), 이상거래감지(anomaly detection), 의료진단(medical diagnosis) 등에서 자주 나타남.
- 회귀문제인 경우: 극단값이 포함되어 있는 치우쳐진 데이터 사례
예) 산불에 의한 피해 면적 예측 (https://www.kaggle.com/aleksandradeis/regression-addressing-extreme-rare-cases)
불균형한 데이터 우회/극복하는 방법
- 방법1. 데이터 추가 확보
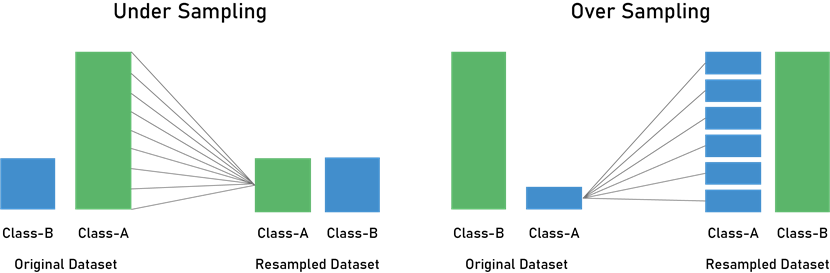
- 방법2. Re-Sampling
- Under-sampling(과소표집)
- 다른 클래스에 비하여 상대적으로 많이 나타나는 클래스의 개수를 줄임
- 균형은 유지할 수 있으나 유용한 정보에 대한 손실이 있을 수 있음
- Over-Sampling(과대표집)
- 상대적으로 적게 나타나는 클래스의 데이터를 복제하여 데이터의 개수를 늘림
- 정보 손실은 없이 학습 성능은 높아지는 반면, 과적합의 위험이 있음
- SMOTE, ADASYN
- Under-sampling(과소표집)

💛 공부 블로그 💛