추천 시스템 논문 번역
The YouTube Video Recommendation System

유튜브 추천 시스템: 사용자들이 사이트에서 활동하는 것을 바탕으로 개인맞춤화된 동영상을 추천해주는 것
유튜브 사용자들의 행동패턴
-
외부 사이트(구글 검색, 페이지 내 html 삽입)에서 유튜브로 유입
-
특정한 비디오 검색(유튜브 내 검색)
-
흥미 위주(오락 및 유흥 목적) ->unarticulated wants를 가진 사용자들에게 개별맞춤형 추천하고자 함.
2010년 당시 유튜브 추천 시스템
Top-N recommender > predictor : 협업적 필터링 중 하나로 사용자가 관심을 가질만한 순위가 매겨진 N개의 상품 추천.
직면한 문제: 메타데이터의 부재, 적은데이터(영상 수 == 활성유저 수), 사용자 상호작용이 짧고 잡음이 많음.
-
사용자들이 영상을 올리기 때문에 추천에 필요한 메타데이터가 부족하고 콘텐츠에 대한 피드백도 명확하지 않다.
-
휘발성이 강하고 메타데이터가 부족하며 주기가 매우 짧은 콘텐츠(10분미만)인 유튜브 비디오를 통해 추천을 잘 하기 위해서는 사용자들의 흥미를 파악하는 것이 중요하다. 당시 영화를 대여하는 방식으로 서비스를 운영하던 넷플릭스와 아마존의 경우, 사용자들이 해당 영화를 선호한다는 명확한 지표인 구입여부가 있었지만 유튜브는 명확한 지표가 부재함.
*메타데이터: 데이터에 관한 구조화된 데이터로 대량의 정보 가운데에서 확인하고자 하는 정보를 효율적으로 검색하기 위해 raw data(원시데이터)를 일정한 규칙에 따라 구조화 혹은 표준화한 정보를 의미.
목표: 사용자의 최근 행동에 연관되어 다양하고 최근이고 새로운 영상을 추천하되
사용자들이 왜 이 영상이 자신에게 추천되었는지 이해할 수 있어야 한다.
시스템디자인 : 추천되는 비디오들의 집합은 사용자의 개인 활동(시청한 동영상, 좋아한 동영상, 즐겨찾는 동영상)을 seed로 하고 co-visitation을 기반으로한 동영상 그래프를 traversing하여 동영상 집합(set)을 확장하는 것. 이후 연관성과 다양성을 판단할 수 있는 여러 지표들을 사용하여 비디오를 ranking한다.
Input Data
1) Content Data (시청기록, 비디오 메타데이터(제목, 설명 등) 등)
2) User Activity Data
- Explicit activity data : 비디오 순위 (좋아요, 구독 등)
- Implicit acitivity data: 비디오와 사용자가 상호작용하면서 쌓이는 데이터(보기 시작한 비디오, 오랫동안 본 비디오)
-> 비디오 데이터는 상당히 비정제적일 수 있다. 사용자 데이터는 사용자의 행동의 윤곽을 잡을 뿐이며 사용자의 참여도와 만족도를 비직접적으로 측정할 수 있기 때문이다. (비디오를 다 봤다고해서 사용자가 만족한지 알 수 없음.)
-> implicit activity data의 경우 비동기적으로 생성되고 완결성을 갖추기 어려울 수 있다. (다보기 전에 유튜브 브라우저 종료 등)
Related Video 사용자가 주어진 한 영상(v, seed video)을 보고 난 다음에 볼 가능성이 높은 영상
두 영상을 mapping하기 위해 Association Rule Mining(= co-visitation counts) 적용.
v: seed 영상
R_i : v_i와 유사하거나 관련된 영상들의 set
(v_i,v_j) : 24시간을 주기로 한 세션 내에서 두 비디오가 얼마나 자주 같이 시청되었는지에 따라 비디오 쌍
r(v_i,v_j): v_i에 대한 v_j영상 연관성 점수(relatedness score of video v_j to base video v_i)
c_i, c_j : 각 영상에 대한 모든 세션의 총 시청횟수
c_ij: 24시간을 주기로 한 세션 내에서 두 비디오가 시청된 횟수
f(v_i,v_j): seed video v_i과 후보영상 v_j의 전체적인 인기를 고려한 정규화 함수
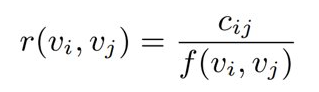
주어진 seed video v_i에 대한 관련 영상 set인 R_i를 r(v_i,v_j)에 의해 랭킹이 매겨진 후보 영상을 상위 N개에 의해 선정한다.
연관영상은 영상 set들을 방향성이 있는 그래프로 유도하는 것으로 볼 수 있다. (v_i,v_j)에 대해서 위의 연관성을 가중치로 삼는 하나의 엣지 e_ij는 v_i에서 v_j iif v_j ∈ R_i이다.
- 본 논문에서 제시한 정규식은 f(vi,vj)=cij/(ci⋅cj)으로 간단한 정규식임. 즉, vj의 전체적인 인기에 국한하여 정규화되게 되어 인기있는 영상보다 인기없는 영상을 선호하는 현상을 낳음.
*또한 최소임계값(minimum score threshold)를 설정하여 동시시청횟수가 너무 낮은 영상들은 제외한다.
*이렇게 한다고해도 정제되지 않은 데이터이기 때문에 많은 문제들이 발생한다.
Generating Recommendation Candidates(추천 후보 생성)
Related videos association과 사용자의 개인 활동을 결합하여 개별 맞춤을 계산한다.
Generating Recommendation Candidates(추천 후보 생성)
Related videos association과 사용자의 개인 활동을 결합하여 개별 맞춤을 계산한다.
S(Seed set) : 동시시청된 비디오(특정 임계값 이상), 좋아요된 동영상, 플레이리스트에 저장된 동영상, 등급매겨진 동영상 등
R_i : S에 속한 각 영상 v_i에 대하여 연관된 비디오의 set
C_1 : 관련된 동영상의 set(R_i들의 집합)

Ranking
앞의 추천 후보 영상set이 생성되고 나면 크게 세 가지 카테고리로 순위를 매길 수 있다.
1) 영상 퀄리티 : 사용자와 상관없이 동영상이 재생될 가능성 판단에 사용(전체 조회수 등)
2) 사용자 특수성: 사용자 특유의 취향과 선호도가 잘 맞는 동영상에 점수 더 주기(사용자의 시청기록의 seed video 속성 고려)
3) 다양성
위의 요소들을 선형적으로 조합하여 후보 영상들의 순위목록을 생성한다. 4~60개의 적은 수의 추천항목들만 표시하므로 목록의 하위집합(subset)을 선택하지만 관련성과 다양성의 균형을 맞추기 위해 최적화를 한다. 단일 seed video와 관련된 추천의 수를 제한하거나 동일한 채널의 추천수를 제한하여 주제 클러스터링 및 내용 분석을 기반으로 하는 정교한 기술을 사용할 수 있다.
Evaluation
A/B 테스트가 주요한 평가 방법.
두 그룹을 사전정의된 행렬 셋에서 서로 비교하는 것으로 실제 웹사이트의 UI에서 이루어지는 사용자의 행동으로 피드백을 얻을 수 있다. 그러나 모든 실험이 합리적인 통제를 갖고 있는 것은 아니며 통계적으로 유의미한 결과를 얻기 위해서는 충분한 트래픽을 가져야하고 주관적 목표에 대한 평가는 상대적으로 작은 사전 정의된 행렬 집합의 해석으로 제한된다는 점이 단점.
추천의 품질을 평가하기 위해 여러 행렬을 조합하여 사용하는데, 중요하게 고려하는 지표는 CTR(Click through Rate, 클릭수/노출수), long CTR(영상 상당부분을 시청하는 것으로 이어진 클릭수만 계산), 세션 길이, 긴 시청을 하기까지 걸린 시간, 추천쇼ㅏ항 포함 범위(로그인 유저 비율) 등을 포함함.
