⭐️ Train Data & Testing Data
머신 러닝 알고리즘을 학습시킬 때 머신 러닝 모델이 얼마나 잘 학습되어있는지 평가할 기준이 필요하다. 학습 단계에서 미리 평가할 수 있는 방법도 필요하다. 왜냐하면 학습 단계에서 모델의 정확도를 높인다면 실제 시장에 적용했을 때의 성능을 어느 정도 확보할 수 있기 때문이다. 머신러닝의 목적은 일반화가 잘 된 모델을 만드는 것이라는 사실을 잘 기억해두자.
가장 흔하게 사용되는 방법은 수집된 데이터는 Train Dataset(학습 데이터)와 Test Dataset(테스트 데이터)로 나누어 모델을 학습시키는 것이다. 여기에서 더 세분화시켠 Vaildation Datset(검증 데이터)도 활용할 수 있다.
원래 가지고 있던 데이터를 학습 데이터와 테스트 데이터로 나누어 사용하게 된다. 학습 데이터는 학습시킬 가설의 파라미터를 결정하는 데에 쓰이는 데에 사용된다. 학생이 모델이라고 한다면 학생이 시험을 잘 보기 위해서 열심히 공부하는 것과 같다. 모의고사의 답을 외우는 게 아니라 실전에서도 고득점을 받을 수 있도록 연습을 하는 것이다.
테스트 데이터는 실제 학습된 데이터를 평가하는 데 사용하는 데이터로 머신러닝모델이 얼마나 잘 학습되었는지 확인할 수 있는 데이터이다.
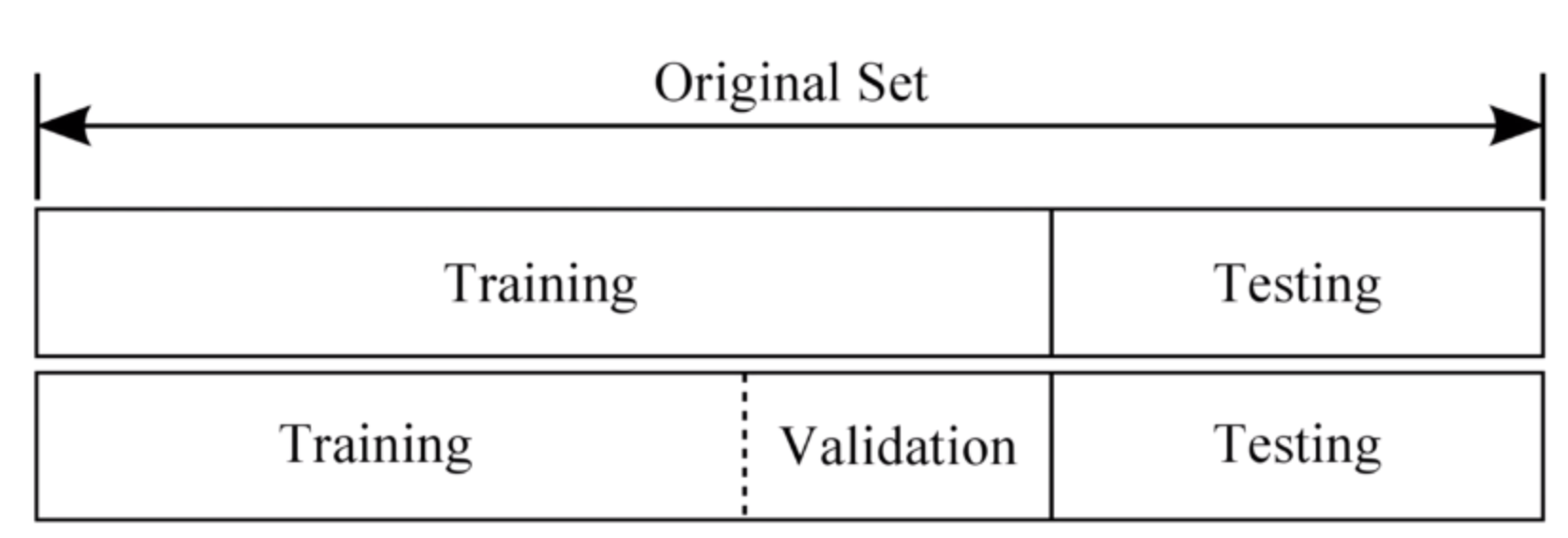
data set에서 30%를 분리시켜 70%는 training data set으로 활용을 하게 되고 나머지 30%는 testing data set으로 활용하는 경우가 많다.
테스트 데이터에 모델이 과대적합(overfitting)될 경우 모델의 편향 에러는 작아지지만 테스트 데이터에서의 성능은 떨어져 분산 에러가 커질 수 있다. 반대로 훈련 데이터에 과소적합(underfitting)될 경우 모델의 편향 에러는 커지지만 테스트 데이터에서의 성능은 유지되어 분산 에러는 작아질 수 있다.
모델의 복잡도를 높일수록 훈련데이터에서 모델 성능은 계속 높아지지만, 검증데이터에서는 일정 수준을 넘으면 모델 성능이 떨어지는 경향을 보이는데 이런 경우를 훈련데이터에 과적합(overfitting)이 일어나고 일반화(generalization)가 덜 진행되었다고 하며 검증데이터의 성능이 떨어지기 직전의 모델을 Best model로 선정한다.
모델을 학습시킬 때 두 가지의 상수가 나타나게 된다. 미분 기울기의 변화하는 step의 크기를 의미하는 알파 값과 overfitting을 줄이기 위해 사용하는 일반화 기술에서 그 값의 크기를 조절하는 람다 값이 바로 그것이다.
그런데 데이터를 학습할 때 이 상수 값에 대한 변화가 필요할 때가 있다. 실제로 overshooting이 일어나거나 cost function의 값의 변화가 거의 없을 때는 알파의 값을 변화시켜 step의 간격을 조절해야하고 일반화 과정이 필요하거나 필요 없을 경우 크기의 차이가 더 필요한 경우 등에는 람다의 값을 조절해야한다. 그래서 training data set의 부분에서 또 다시 다른 학습 데이터 부분을 나누게 된다. Validation이라는 부분으로 Training set을 조금 더 보안하는 data set을 가지게 된다.출처
⭐️ 다중선형회귀를 이해하고 사용할 수 있다.
기준 모델(Baseline Model)
기준 모델(Baseline Model): 예측 모델을 만들기 전에 직관적이면서 최소한의 성능을 나타내는 기준이 되는 모델
- 분류 문제: 타겟의 최빈 클래스 (mode)
- 회귀 문제: 타겟의 평균값 (mean)
- 시계열회귀문제: 이전 타임스탬프의 값
기준모델(Baseline)은 모델링에서 최소한 넘어야 할 최저기준으로, 일반적으로 선형모델에서 기준모델은 타겟 데이터의 평균값으로 설정하는 경향이 있다.
예측 모델
회귀분석에서 중요한 개념은 예측값과 잔차(residual)이다.
예측값은 만들어진 모델이 추정한 값이고, 잔차는 예측값과 관측값의 차이이다.
회귀선은 잔차 제곱들의 합인 RSS(residual sum of squares)를 최소화 하는 직선 (RSS = SSE / Sum of Square Error)
