💚 평균제곱오차 (MSE, Mean Squared Error)
💡 머신러닝뿐만 아니라 영상처리 영역에서도 자주 사용되는 추측값에 대한 정확성을 측정하는 방법이다. 추정한 값에 대한 정확도를 측정하는 쉬운 방법이기 때문에 자주 쓰인다. 머신러닝에서는 Cost Function(손실함수 혹은 비용함수)에서, 영상처리에서는 화질 개선을 위해 원본 대비 화질을 측정하는 PSNR에서 주로 쓰인다.
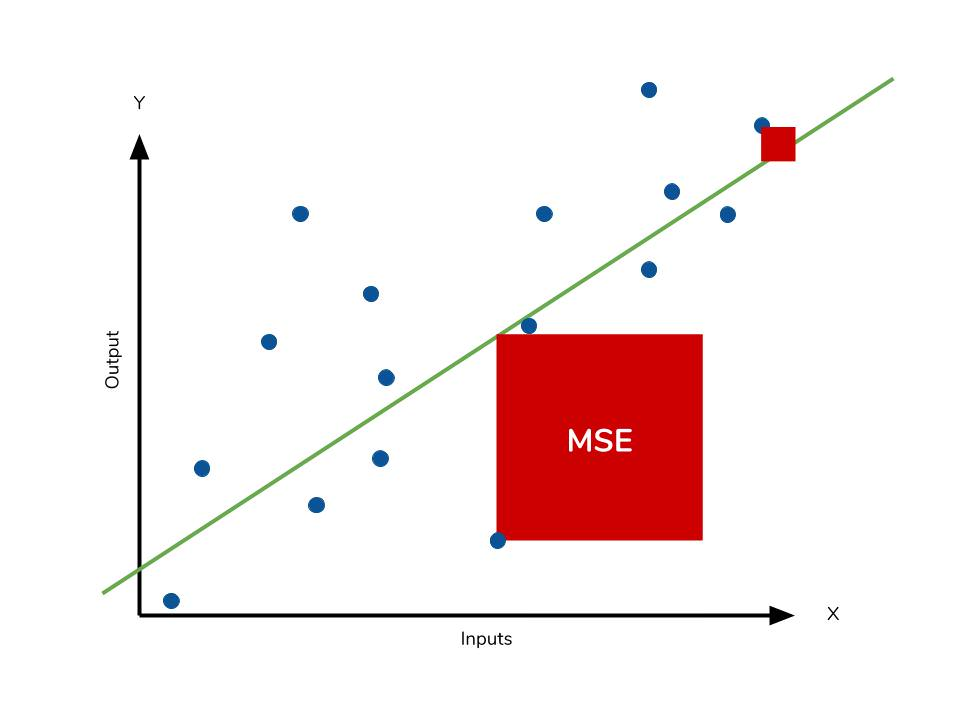
- 실제값과 예측값의 차이를 제곱해 평균화
- 예측값과 실제값 차이의 면적의 평균과 같다.
- 특이값이 존재하면 수치가 많이 늘어난다.
공식
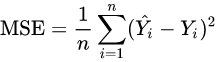
- 오차의 제곱을 평균으로 나눈 것이다.
- MSE가 0에 가까울수록 추측한 값이 원본에 가까운 것이기 때문에 정확도가 높다고 할 수 있다.
- 예측값과 실제값 차이의 면적의 평균이라고 할 수 있다.
python 구현
손으로 직접 풀어서 쓰거나 머신러닝 분석에서 자주 쓰이는 sklearn(사이킷런)이라는 모듈을 불러올 수 있다.
#손으로 풀기
#MSE (Mean Squared Error) = difference between the original and predicted values .
#extracted by **squared** the average difference over the data set.
MSE = (test_value - predicted_value)^2 / len(test_value)
#다른 풀이
MSE = np.square(np.subtract(x, y)).mean()파이썬에서 sklearn의 mean_squared_error로 간단하게 계산하기
from sklearn.metrics import mean_squared_error
mean_squared_error(test_value, predicted_value)💚 평균절대오차(MAE, Mean Absolute Error)
💡 회귀평가를 위한 지표로 주로 쓰인다. 기계 학습 모델의 퀄리티를 요약하고 평가하기 위한 여러 메트릭 중 하나라고 할 수 있다.MSE와 마찬가지로 0에 가까울수록 좋은 모델이라고 할 수 있다.
공식
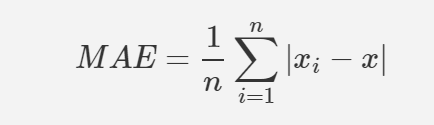
python 구현
손으로 직접 풀어서 쓰거나 머신러닝 분석에서 자주 쓰이는 sklearn(사이킷런)이라는 모듈을 불러올 수 있다.
# MAE (Mean absolute error) = difference between the original and predicted values
# extracted by **averaged** the absolute difference over the data set.
import numpy as np
MAE = np.abs(tested_value - predicted_value) / len(v1)
#다른 풀이
MAE = np.abs(np.subtract(x, y)).mean()파이썬에서 sklearn의 mean_squared_error로 간단하게 계산하기
from sklearn.metrics import mean_absolute_error
mean_absolute_error(tested_value, predicted_value)
💎 데이터분석에서 MSE와 MAE의 쓰임.
평균 제곱 오차(MSE)는 회귀에서 자주 사용되는 손실 함수이다.
정확도 개념은 회귀에 적용되지 않는다.
일반적인 회귀 지표는 평균 절대 오차(MAE)이다.
MSE는 손실함수로써 쓰이고 MAE는 회귀지표로써 사용된다.

🍒 손실함수(Loss function = cost function = 비용함수)

위의 그림은 일반적인 통계학의 모델로, 입력값(x)를 함수 (F(w))에 넣었을 때 결과값(y)가 나오는 것을 그림으로 그린 것이다. 그렇다면 예측값으로 나온 y와 실제의 y값(y`)이 유사할수록 모델이 좋다고 할 수 있을 것이다. 이 때, 예측값과 실제값의 차이를 확인하는 함수가 바로 손실함수이다.
손실함수는 측정한 데이터를 토대로 산출한 모델의 예측값과 실제값의 차이를 표현하는 지표이다. 즉, 모델이 데이터를 얼마나 잘 표현하지 못하는가를 나타내는 지표라고 할 수 있다. 따라서 얼마나 잘 표현하지 못하는가를 어떤 방식으로 표현하느냐에 따라 다양한 손실함수가 존재한다.
통계학적 모델은 크게 회귀(regression)모델과 분류(classification)모델로 나뉜다.
회귀모델에 쓰이는 손실함수에는 MSE, MAE, RMES 등이 있으며
분류에 쓰이는 손실함수에는 Binary cross-entropy, Categorical cross-entropy 등이 있다.
📊 손실함수로써 MAE
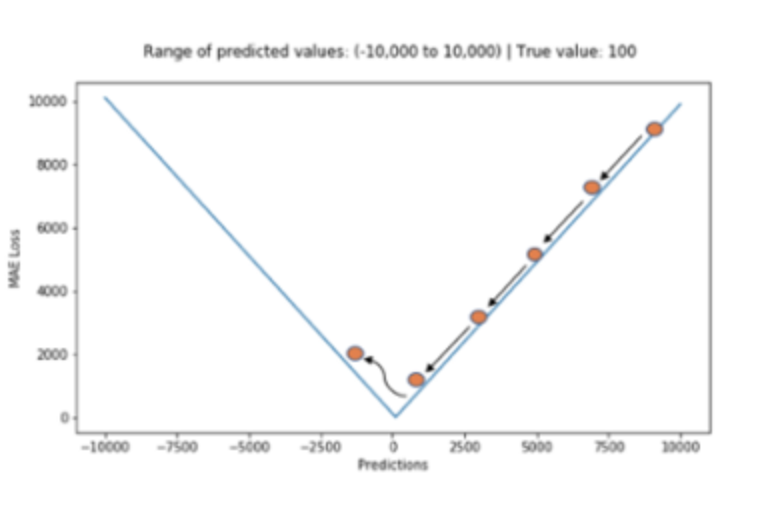
장점:
- 전체 데이터의 학습된 정도를 쉽게 파악할 수 있다.
단점:
- 어떤 식으로 오차가 발생했거나 음수인지 양수인지 알 수 없다.
- ❗️위의 그림에서처럼 최적값에 가까워졌다고 하더라도 이동거리가 일정하기 때문에 최적값에 수렴하기 어렵다.
📊 손실함수로써 MSE
가장 많이 쓰이는 손실함수 중 하나이다.
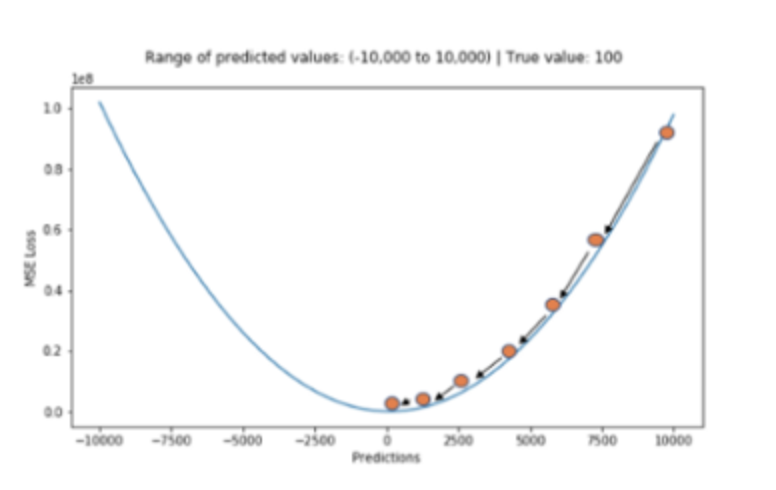
장점:
- 실제 정답에 대한 정답률의 오차뿐만 아니라 다른 오답에 대한 정답률의 오차도 포함하여 계산해준다.
- MAE와 달리 최적값에 가까워질수록 이동값이 다르게 변화하기 때문에 최적값에 수렴하기 용이하다.
단점:
- 값을 제곱하기 때문에 절댓값이 1미만인 값은 더 작아지고, 1보다 큰 값은 더 커지는 왜곡이 발생할 수 있다.
- 제곱하기 때문에 특이값의 영향을 많이 받는다.
❓ 최적값에 수렴하기 용이하다는 말은 최적값에 도달했을 때의 미분이 0이 나온다는 말일까?

안녕하세요 잘 읽었습니다!
MSE는 손실함수로써 쓰이고 MAE는 회귀지표로써 사용된다. 라고 쓰여 있는데 혹시 회귀지표라는 게 무엇을 뜻할까요? 분류에서 accuracy나 f1처럼 성능 척도를 말하는 걸까요?