
Word2vec parameters and computations
[복습]
저번 강의에서 배운 word2vec을 복습한다.
우리는 각 텍스트(문장)에서 중심단어(V : center word) 와 바깥단어(U : outside)를 가진다.
그리고 이들에 대한 확률을 얻기 위해서 dot product를 진행한다.
그런다음 softmax를 사용해서 dot product score를 확률로 바꾼다.

이 모델이 bag of words model이라 불린다. 이는 단어간의 위치나 순서를 고려하지 않는다.
이 점이 굉장한 crude한 언어 모델 처럼 보인다. 그럼에도 불구하고 굉장히 배울점이 좀 있는 모델이다.
Optimization : Gradient Descent
어떻게 좋은 word vector을 learn하는가?
저번 강의에서 보여준 cost fuction을 극대화해야함(이론적으로는 최소화이지만 log값 앞에 마이너스가 달리므로 값을 제일 크게해야함) > Gradient Descent !를 시행함.
random word vector을 골라서 시작함. 이 알고리즘은 반복적인 알고리즘으로, J(\theta) 를 극대화한다 (\theta를 바꿈으로써) 현재의 \theta값의 기울기를 계산하고 작은 step을 기울기가 작아지는 방향으로 움직인다. 최솟값을 찾는다.
step size를 잘 골라야 한다.
💡 Idea : from current value of \theta, calculate gradient of J(\theta),then take small step in the direction of negative gradient. Repeat.하지만 대부분의 학습에서는 Gradient Descent를 사용하지 않는다. GD는 전체의 데이터셋(문장)에 대한 기울기를 구한 뒤에 한번의 step을 움직인다. 이는 very expensive하다.
그래서 대부분 SGD(Stochastic gradient descent)를 이용한다.
전체가 아니라 작은 배치 사이즈 또는 각각에 대해서 기울기를 계산하고 업데이트 하는 것이다.
Word2vec algorithm family : SG,CBOW
왜 두개의 vector를 이용하는가? optimization을 쉽게 하기 위해서
- Skip-Grams(SG) : center word가 주어졌을때 outside word를 예측하는것 (1강에서 설명한것 )
- Continuous Bag of Words(CBOW): bag of context word를 통해서 center word를 예측
- skip-grams negative sampling(SGNS)
SGNS
이것은 softmax대신에 sigmoid를 쓰며, 회귀분석의 cost function식과 유사하다.
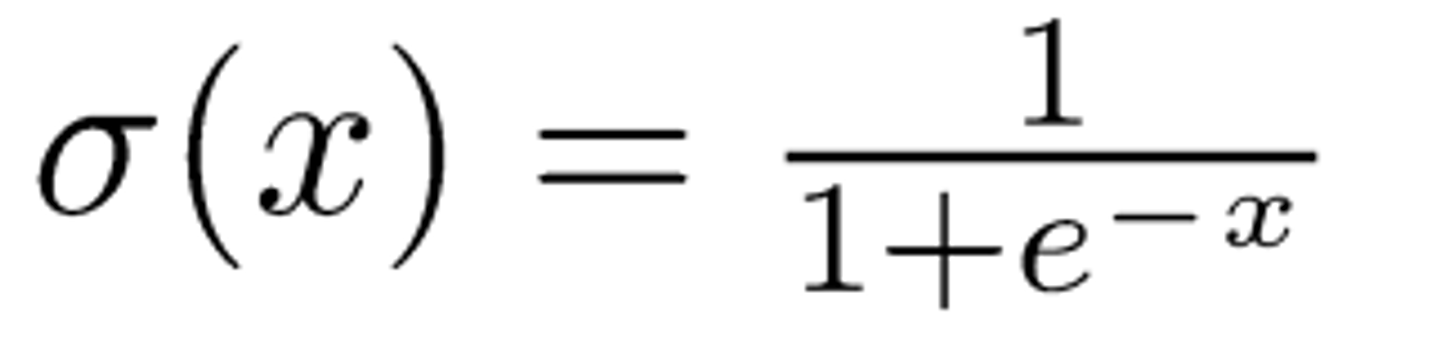
다음과 같이 두 부분으로 나누어져 있고, 시그모이드 함수의 식과 그래프는 다음과 같다.
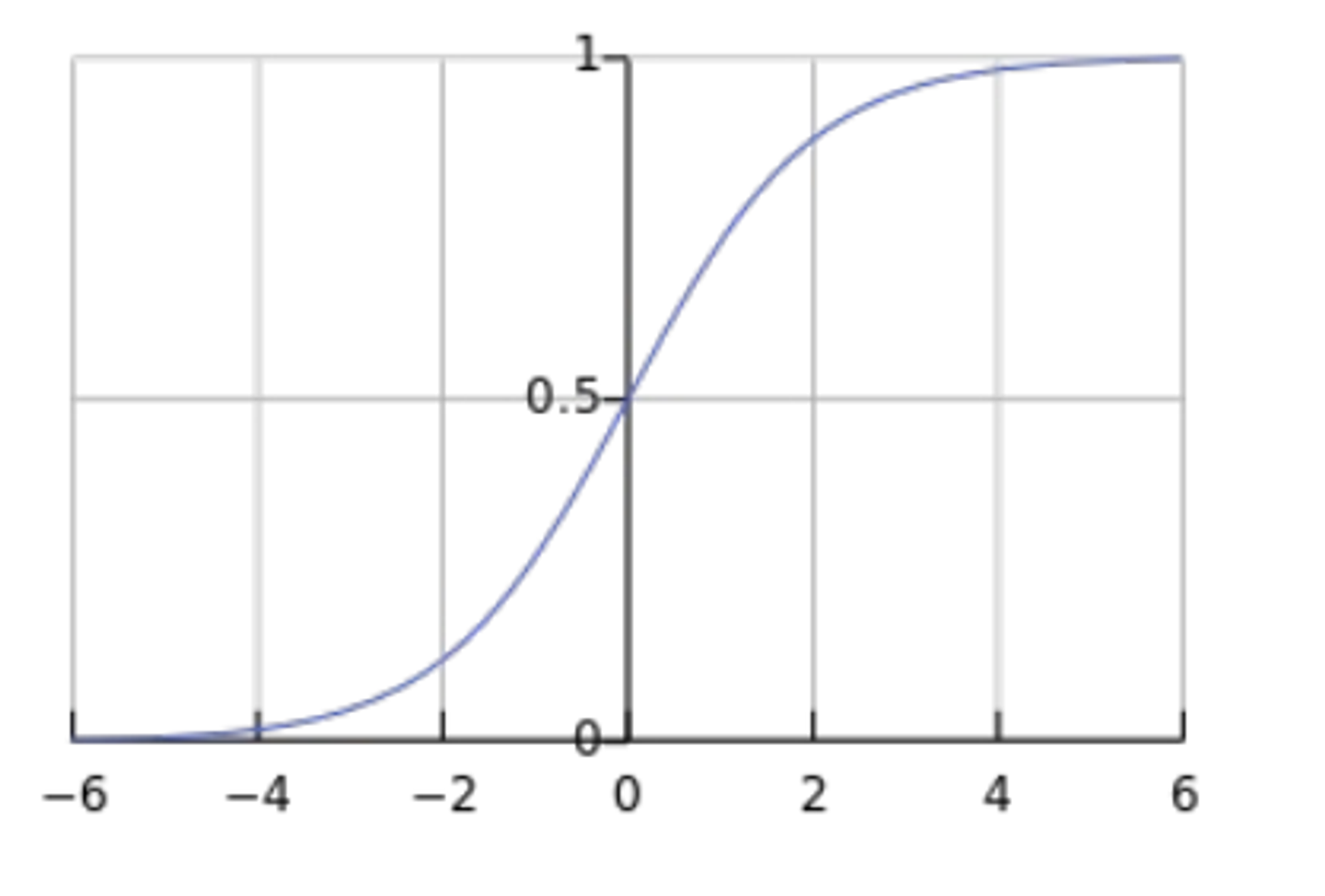

x의 값이 양수일때, 값이 크면 클수록 1에 수렴하고, x의 값이 작으면 작을 수록 0에 수렴한다.
우리는 위의 cost function을 maximize시켜야 한다.
따라서 앞부분의 dot production의 값은 크게 만들어야 하고, 뒤의 식에는 -가 있으므로 최대한 작게 만들어야 전체 cost function의 값을 크게 할 수 있다.
maximize the probability of two words co-occuring in first log and minimize probability of noise words
이를 살짝 변형한 식은 아래와 같다. (두번째 식의 dot product앞에 마이너스가 빠졌다)
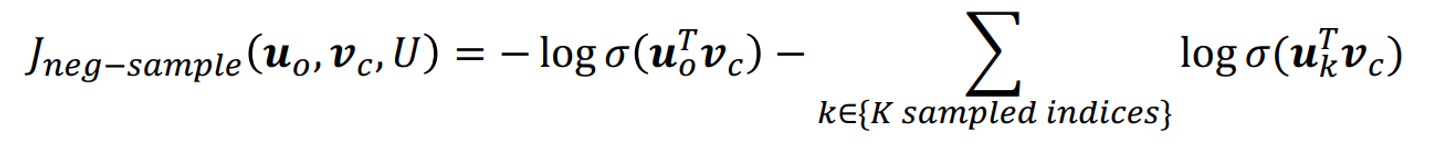
전체에 negative을 씌워주었다. 우리는 위의 식을 minimize하면 된다.
앞의 식의 dot product는 크게, 뒤의 dot product는 작게 하면 된다.
한개의 트릭이 더 있다면, word을 샘플링할때, 그들은 단지 등장 확률에 기반하지 않는다.
그들은3/4승을 시킨다.? 확률을 renormalized하는 효과가 있다. 덜 등장하는 단어는 더 많이 샘플링 되도록 한다고 한다…
동시 행렬
정한 window사이즈를 기반으로 행렬 표시
여러 문장 또는 문서에 등장하는 단어를 각 행, 열에 놓고 만든다.
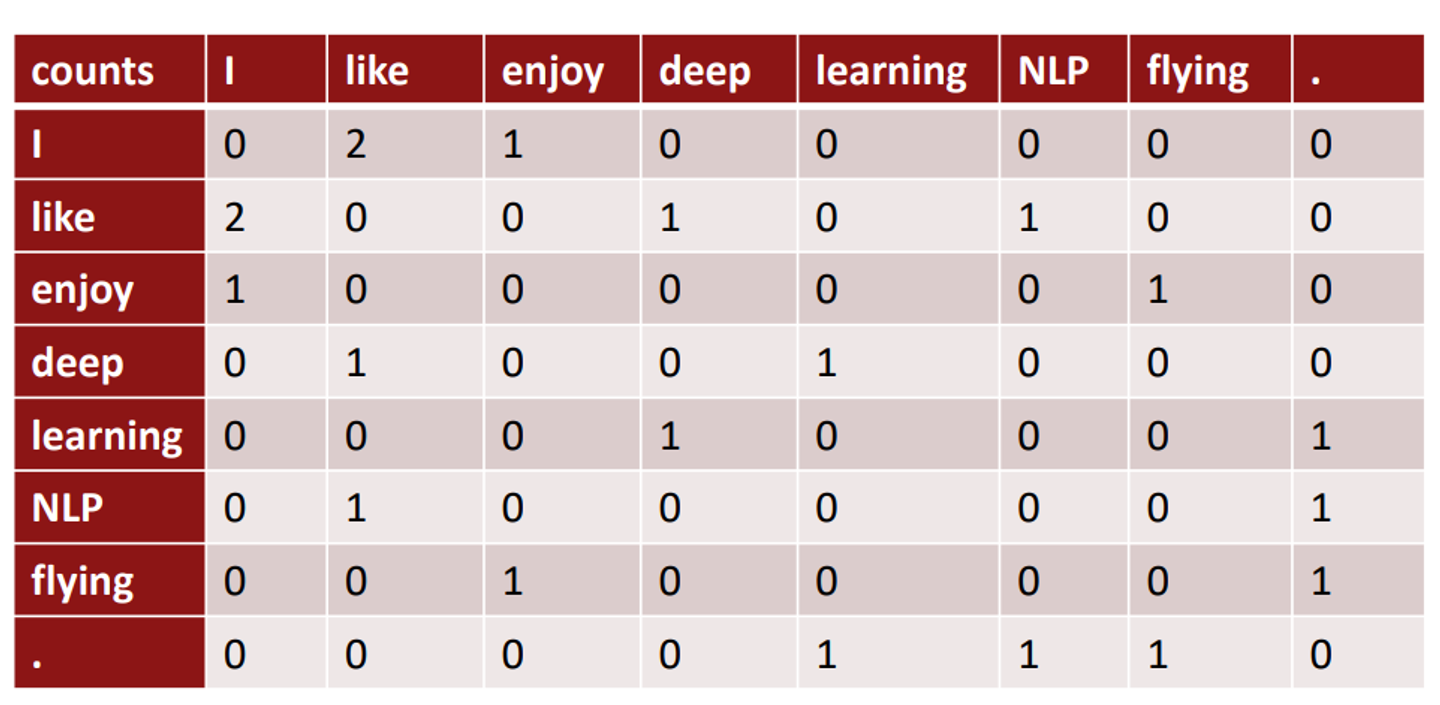
이렇게 만들어진 벡터들을 사용하는게 좋을까? 끔찍하진 않은데 몇가지 문제가 있다.
각 단어들의 벡터 사이즈가 너무 크다는게 제일 심각
문서의 크기가 커질수록 단어의 벡터사이즈도 같이 커진다. (high dimensional) sparsity issue발생.
그래서 벡터의 dimension을 줄이고자 하였다. 가장 중요한 정보만 담아서 밀집성이 있는벡터를 만들자. 대부분 25-1000차원을 사용 .
어떻게 줄이냐?
Singular Vlue Decomposition of co-occurrence matrix X
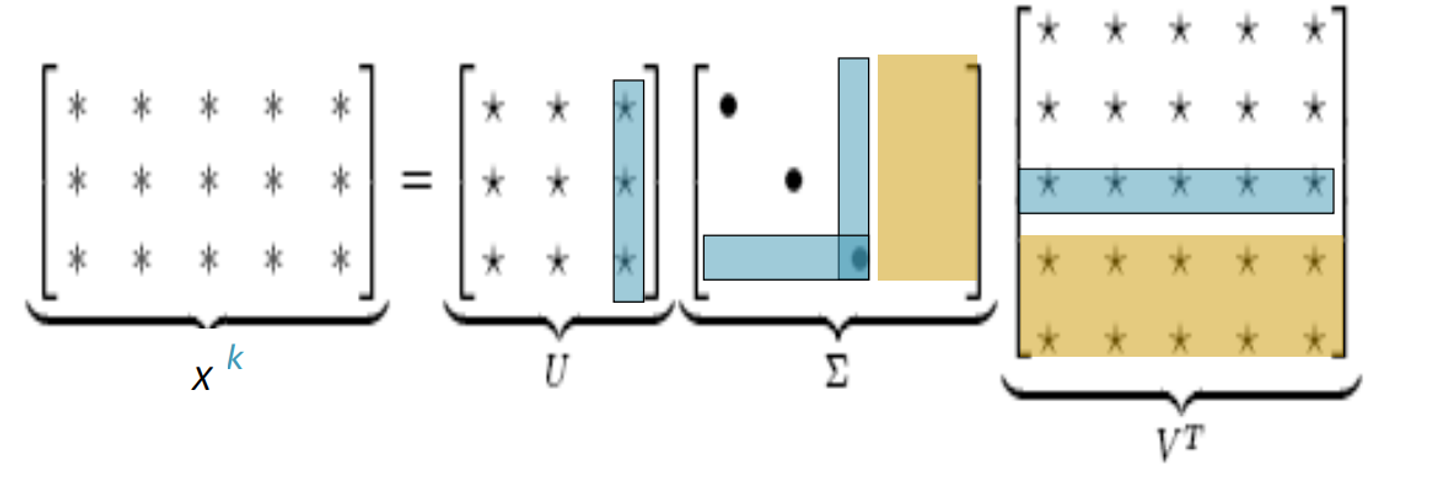
이것은 선형대수학의 고전적인 방법이지만 실제로 이 방법을 사용하면 그닥 잘 되지 않는다.
a, and , that 같은 기능어들이 너무 많이 등장하기 때문이다. 이 것들은 너무 많은 impact를 가지고 있다. 이를 해결하기 위해서
1) 적게 나온 count에 로그 씌우기
2) 최대개수 정해서 넘은건 자르기
3) 기능어들은 삭제하기
Glove나오기 전에 총정리
지금까지 정리한 알고리즘은 크게 두가지로 분리된다.
-
동시행렬과 선형대수학을 기반(count based)
- 빠른 훈련
- 통계의 효율적인 이용
- 단어 유사도를 파악하는데만 장점
- 큰 count에 대한 중요도를 분해하지 못함(그니까 빈도수가 높으면 무조건 중요하게 보는걸 해결못함)
-
반복적인 신경망 업데이트 알고리즘(skip-gram,CBOW..direct prediction)
- 코퍼스 사이즈가 늘수록 처리량이 늘어남
- 통계를 잘 활용하지 않ㅇㅁ
- 다른 업무에도 향상된 성과를 보임
- 유사도 말고도 복잡한 다른 패턴도 캡처 가능
Encoding meaning in vector diffenrences
중요한 인사이트가 하나 나왔다.
Ratios of co- occurrence probabilities can encode meaning components
동시행렬의 비율로 의미있는 component를 만들어낼 수 있다는 것이다. 아래 표는 예시이다.

Q : "단어 벡터 공간에서 공존 확률(co-occurrence probabilities)의 비율을 선형 의미 요소로 어떻게 포착할 수 있을까요?”
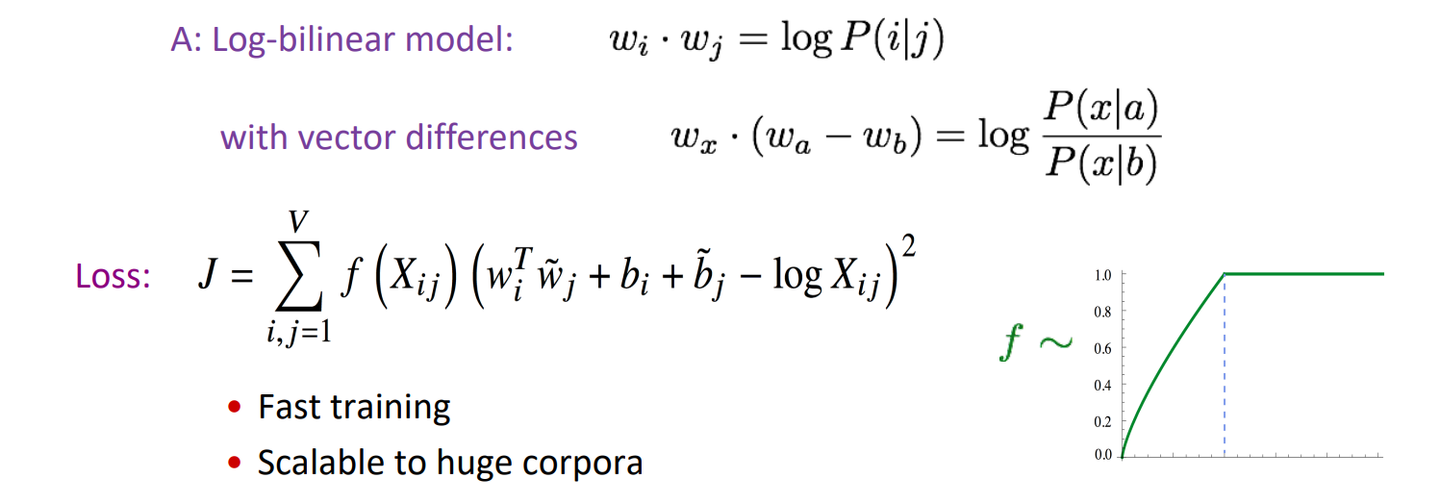
다음과 같이 나타냈다고 한다…
강의에서는 Glove의 cost function과 활성화함수에 대해서 자세히 설명하진 않았다. 아마 논문을 보란 소리겠지..,. 숙제가 없어서 그런가
이 모델은 동시행렬의 아이디어와 신경망 모델의 아이디어를 합쳤다. 동시행렬의 기반으로 계산되지만 손실함수로 반복적인 기울기 계산이 진행되기 때문이다.
