
language Model
전통적인 언어 모델
“나는 지금”이란 문장 뒤에 올 단어를 어떻게 예측하는가?
초기의 언어 모델은 통계를 기반으로 구축되었다.
확률 분포를 기반으로 주어진 문맥(sequence) 이후에 위치할 단어를 예측하는 것이다.
이때 사용하는 확률 기법은 multiplication rule 이다.
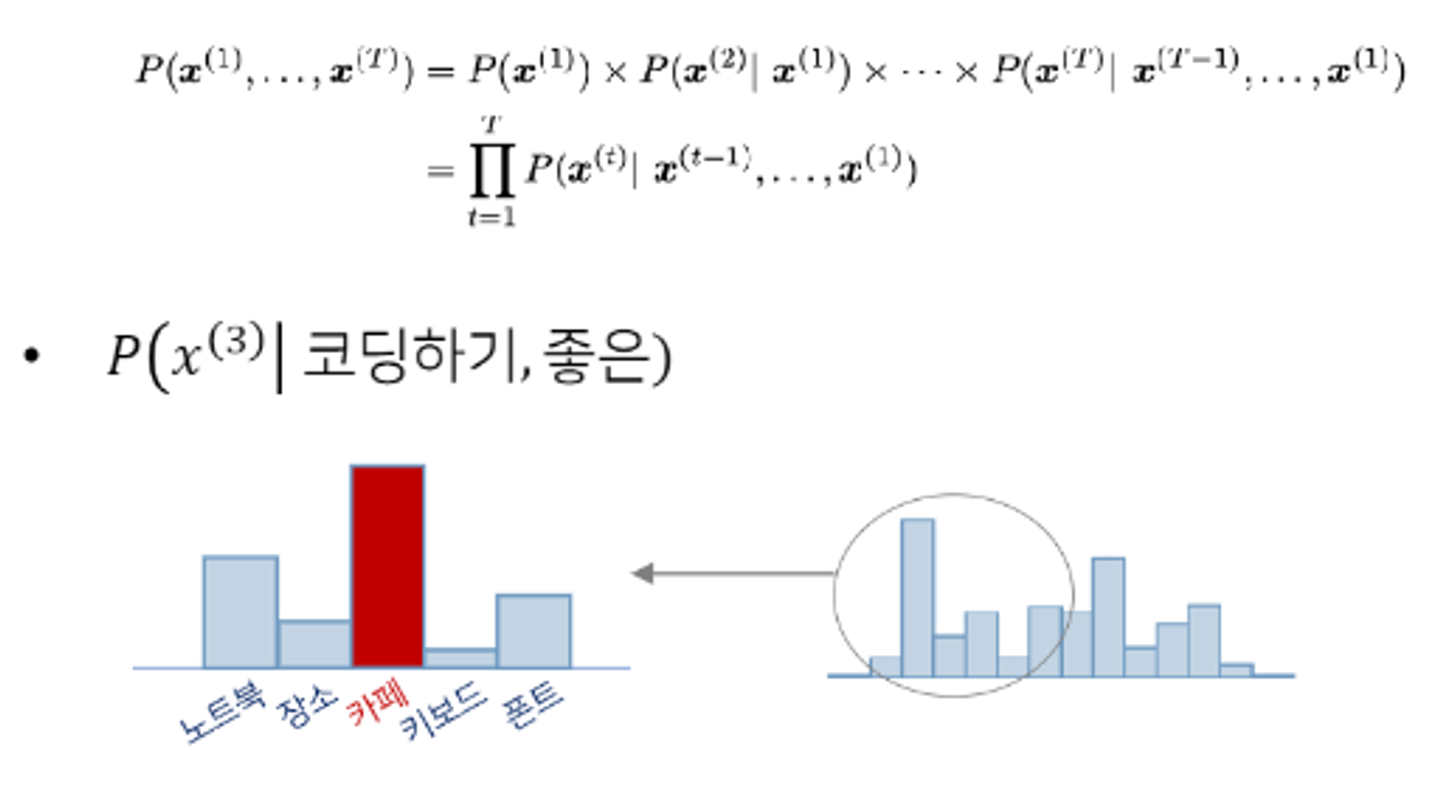
위의 예시는 코딩하기, 좋은 이라는 단어 뒤에 어떤 단어가 오는지 가장 적합한지 분포를 예측한 뒤, 카페라는 확률분포의 값이 제일 크기 때문에 카페라는 단어를 선택할 것이다.
n-gram, Neural LM
이를 좀 더 발전 시킨 개념이 count기반의 n-gram이다.

예측하고자 하는 단어 전에 나왔던 n개의 단어를 바탕으로 예측하는 것이다.
단어가 아예 등장하지 않으면 분자나 분모가 0으로 나올 수 있다는 문제점이 있다. ( 이를 sparsity problem이라고 한다. )
이 문제를 해결하기 위해 등장한 모델이 Neural language Model이다.
이는 n개의 단어 모두를 보는 것이 아니라 미리 지정한 window size만큼의 이전 단어를 바탕으로 예측을 진행하는 것이다.

워드 임베딩을 통해서 입력된 값의 distributed representation을 학습한다.
임베딩 공간 상에서 비슷한 의미를 가진 단어는 비슷한 공간에 임베딩된다는 사실을 바탕으로 진행되는 것이 distributed representation이다.
하지만, 이 두 모델 모두 입력 길이가 고정되어 있기 때문에 이전에 등장하는 모든 단어를 고려할 수 없다.
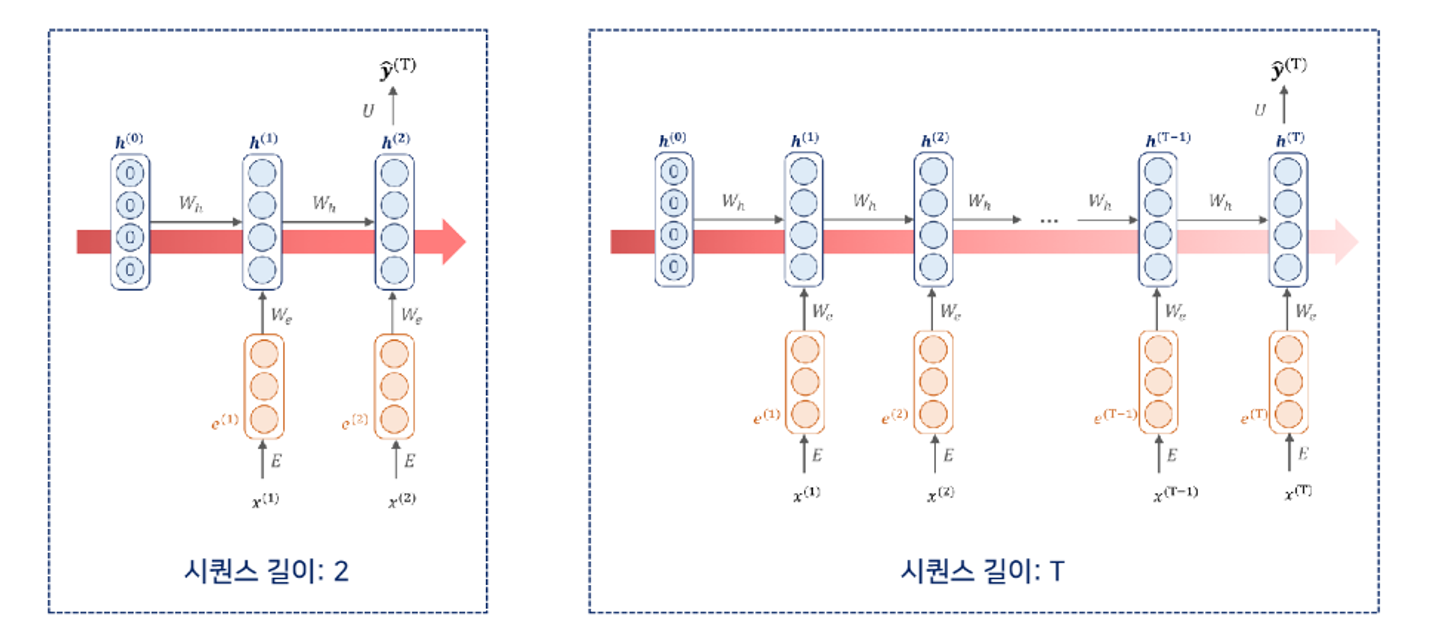
RNN Language Model
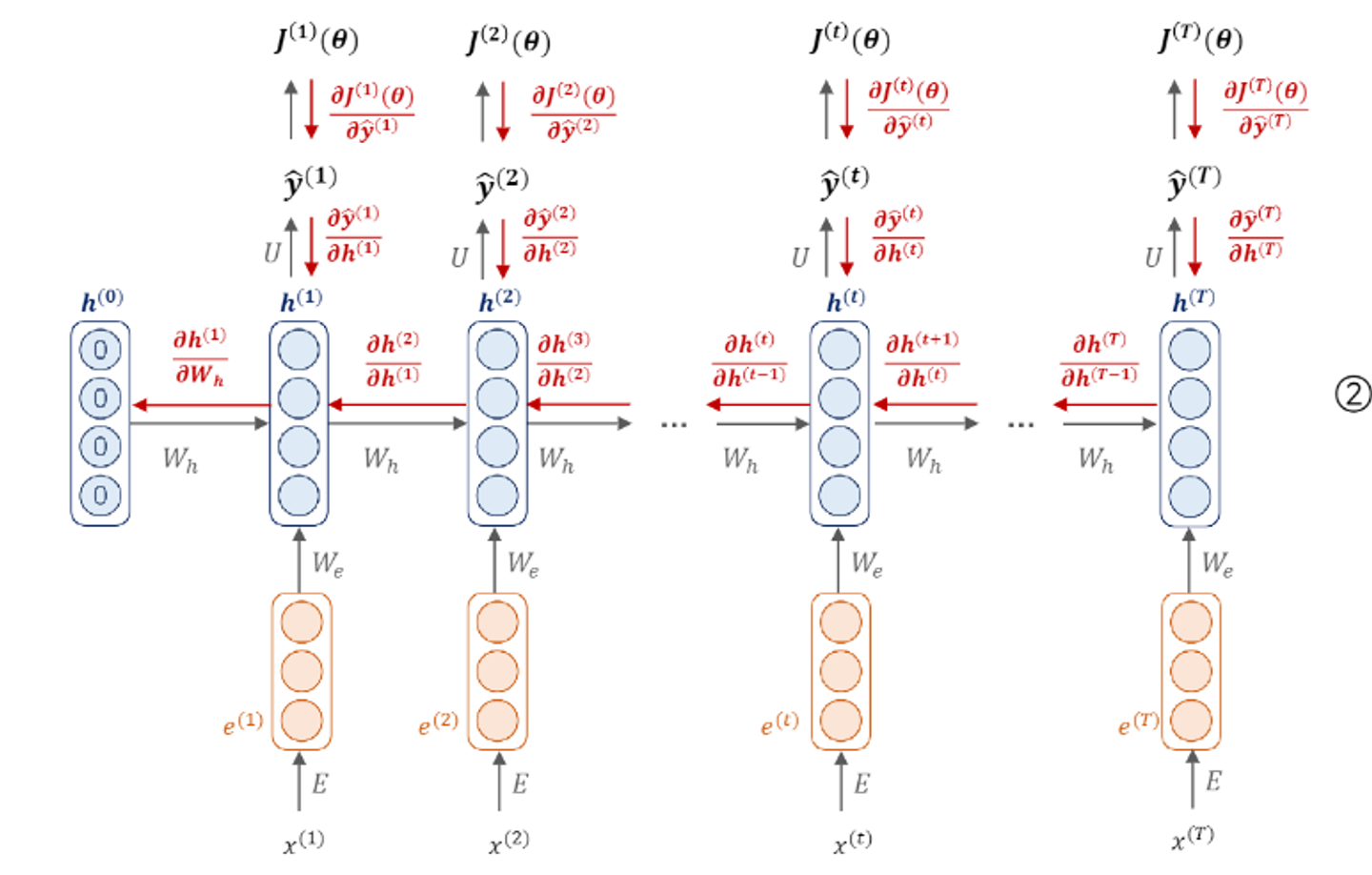
- 첫번째 단어가 vocab size만큼의 원핫 벡터로 들어온게 된다.

- 이는 임베딩 과정(E)를 만나서 연산과정을 거쳐 임베딩 representation vector을 얻는다.

- 다음으로는 hidden state vector을 도출하기 위한 과정을 거쳐야한다. 이를 위해서는 앞서 구한 임베딩 벡터 뿐만 아니라 초기값으로 초기화된 히든 state vector가 필요하다. 가중치 Wh와 함께 다음 연산을 통해 hidden vector을 구한다.

- 첫 타임 스탭의 만들어진 히든 스테이트 벡터는 U는 가중치연산을 통해 vocab 사이즈 만큼의 아웃풋 벡터를 만들어 냅니다. 해당하는 벡터에서 가장 높은 값을 가지는 단어가 다음 단어로 예측이 진행된다.

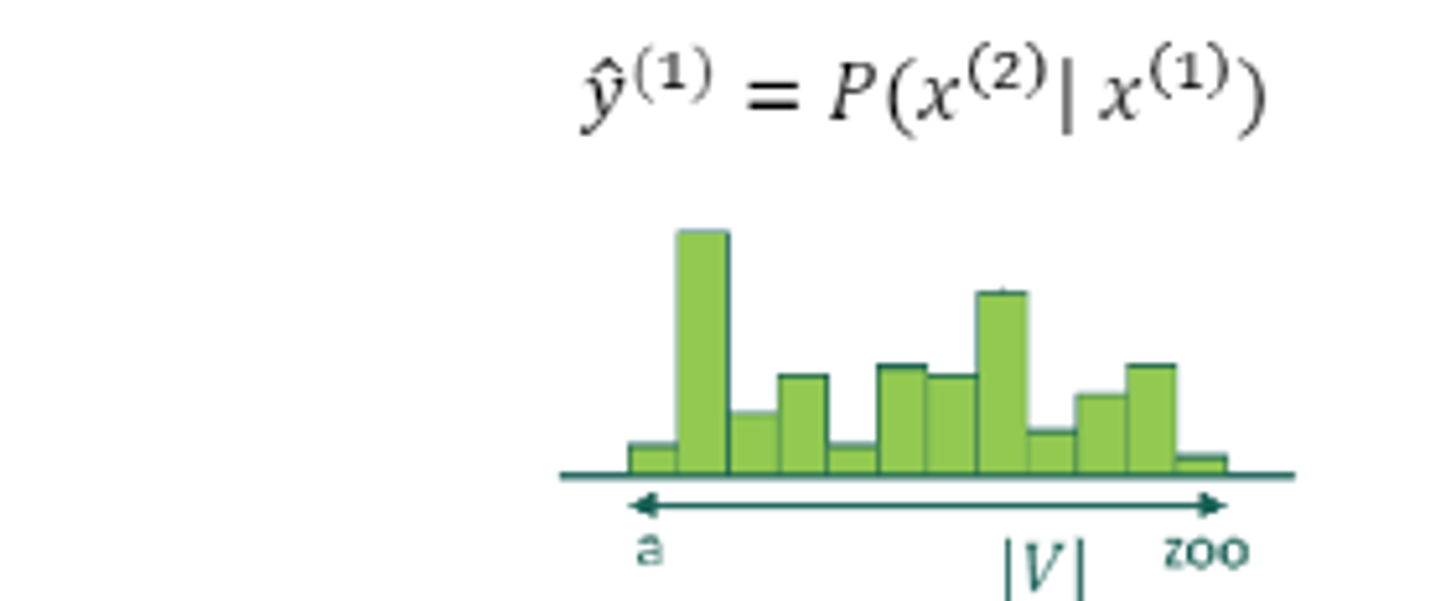
이를 반복하여 입력값을 넣어 반복한다.
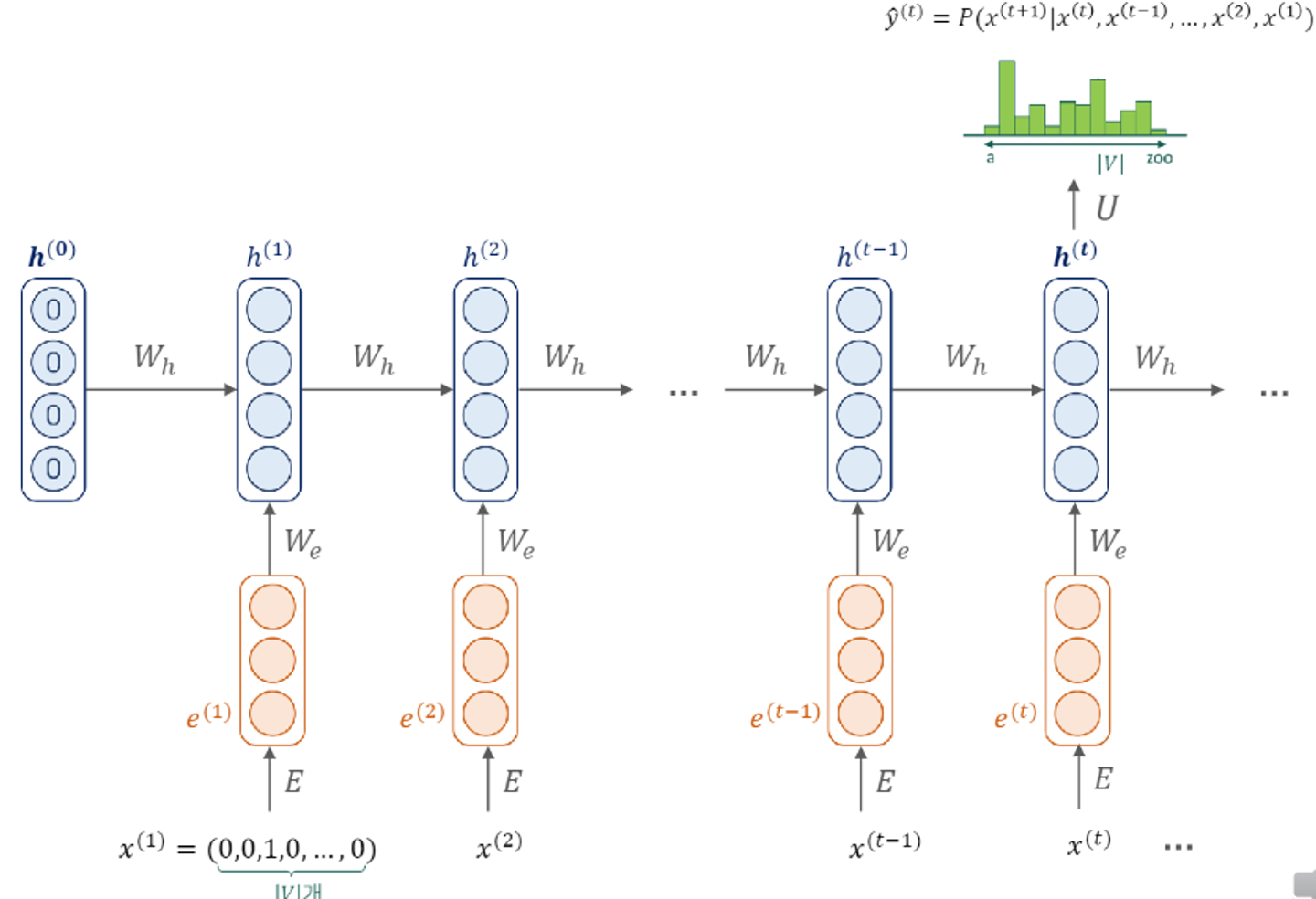
가중치 메트릭스는 타임스텝에 상관없이 동일한 메트릭스를 사용한다.
순차적인 입력과 아웃풋 반환을 가지게 된다.
이와 같은 방법은 many-to-many 구조라고 한다.
매 타입스탭 별로 입력과 출력값이 존재해야한다.
RNN loss function
분류 테스트이므로 cross entropy loss function을 사용한다.
이 loss값은 매 타입스탭별로 계산이 된다.
각각의 loss값을 평균낸 값으로 전체 손실을 구한다.
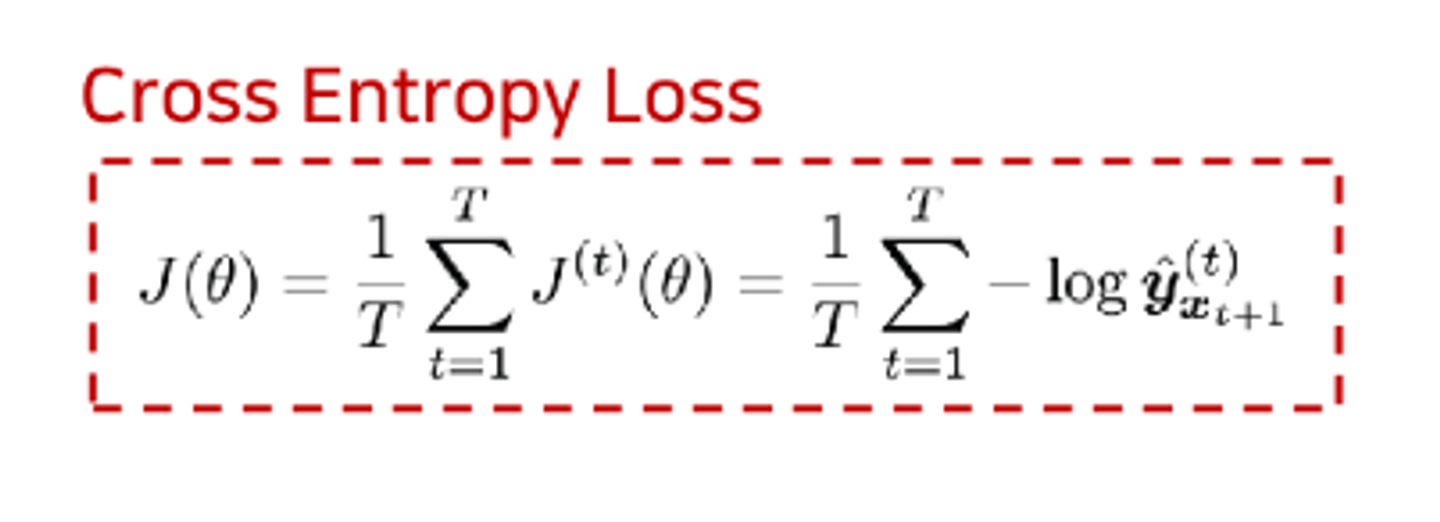
역전파 with RNN
- 마지막으로 진행되는 U가중치벡터 부분의 역전파.
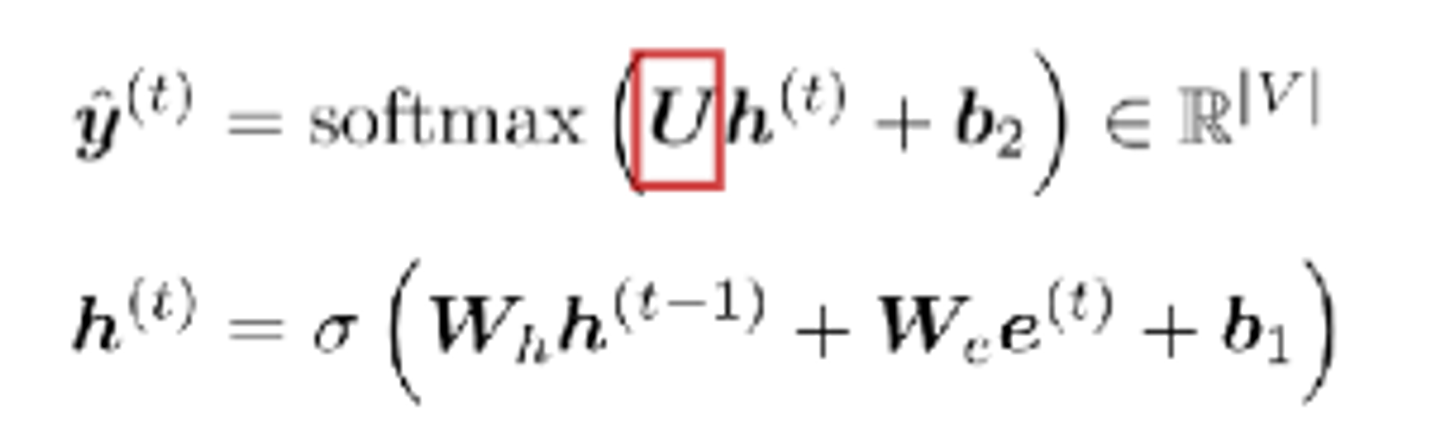
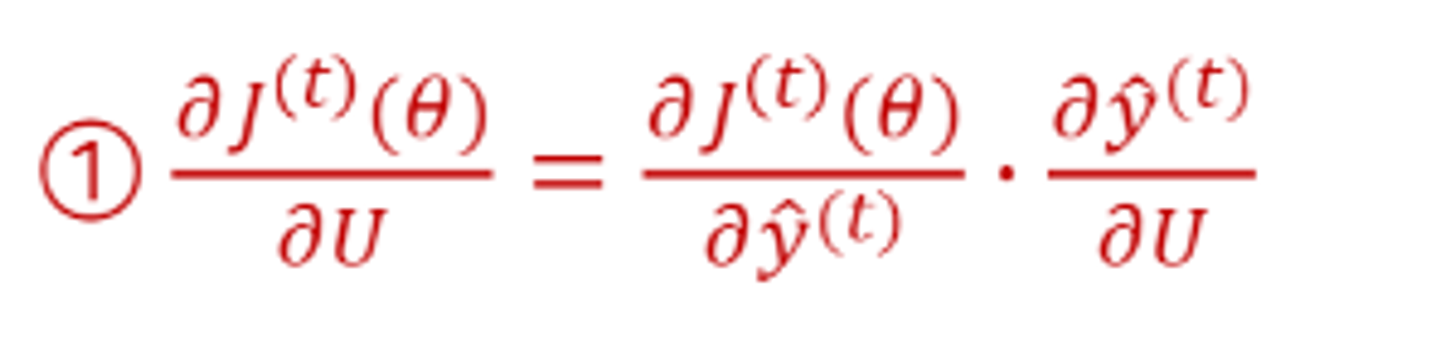
U가중치 벡터를 통해서 최종 예측 값이 반환이 되는 것이었는데, 이 값을 U로 편미분을 진행한다. chain rule에 의해서 다음과 같이 분해가 된다.
RNN의 경우, 이 U편미분을 매 타임스텝마다 진행하여 다음과 같이 편미분한 값의 최종 합을 통해 전체의 값을 얻는다.
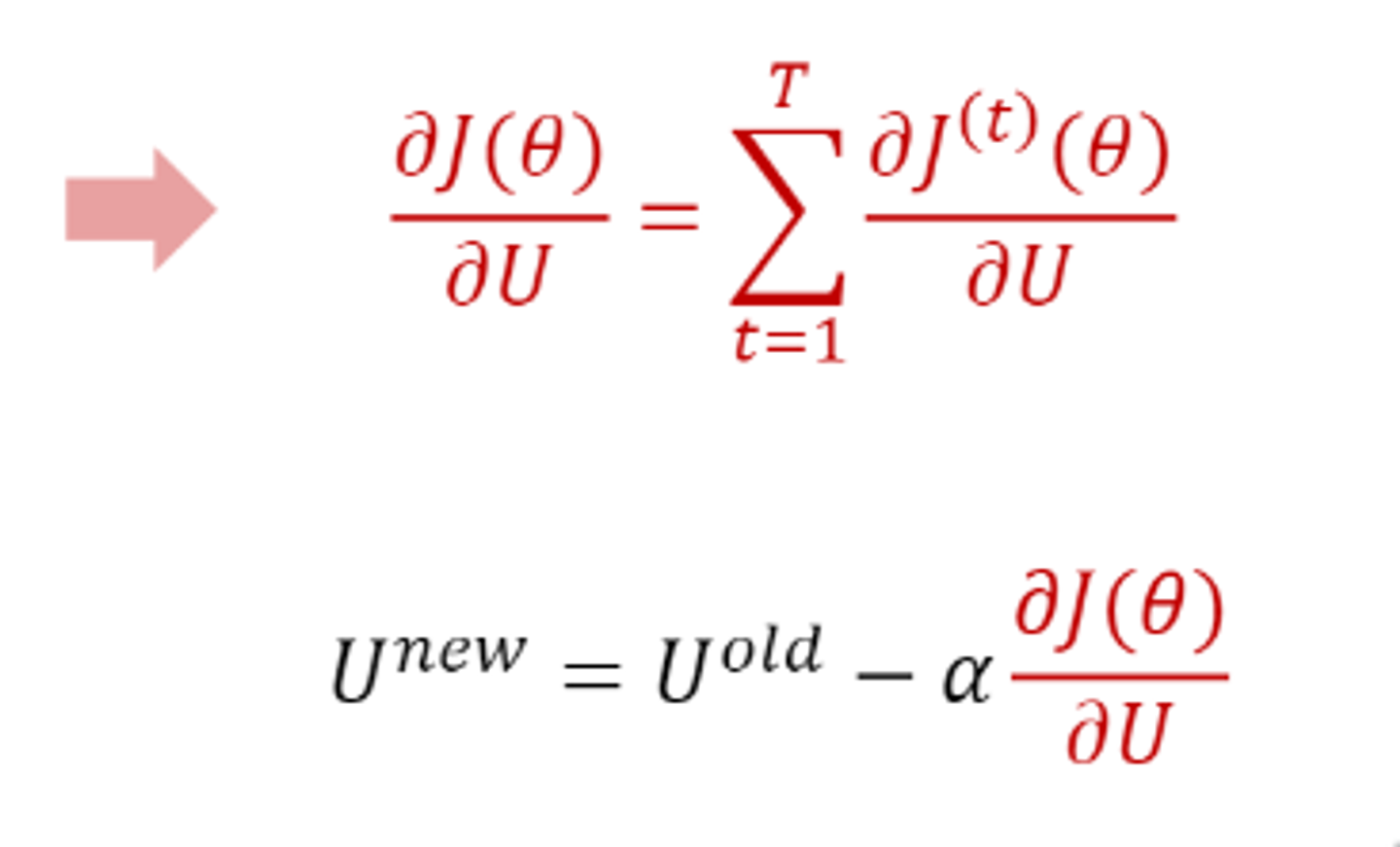
그리고 learning rate와 곱해 U가중치 벡터를 업데이트 해준다.
- Wh 가중치 역전파
전 시점의 hidden state와 계산하는 Wh가중치 벡터 업데이트하기.
이를 단지 전 단계의 hidden state만 고려하면 안되기 때문에 다음과 같이, 전의 모든 hidden state를 고려하는 수식을 사용한다.
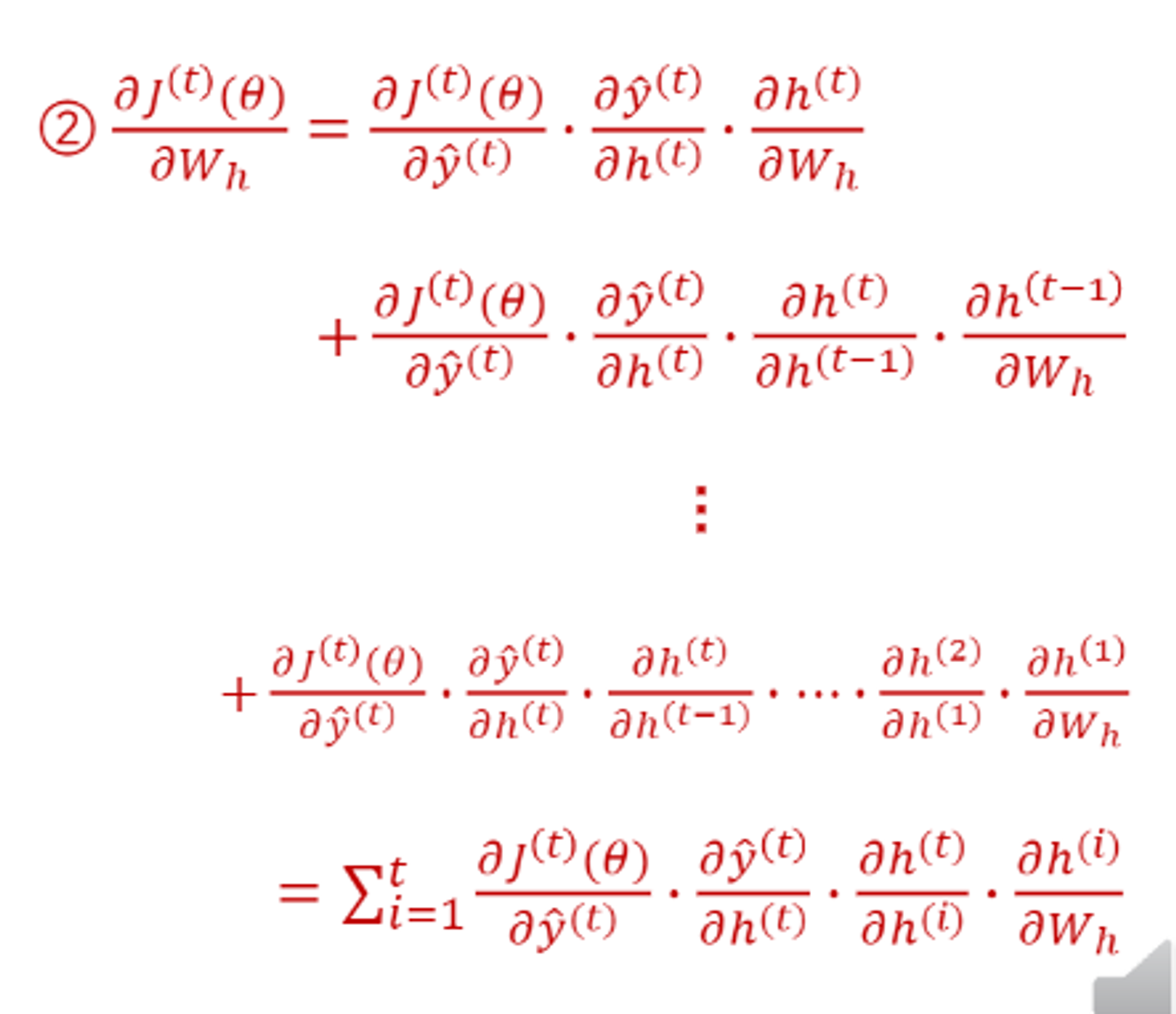
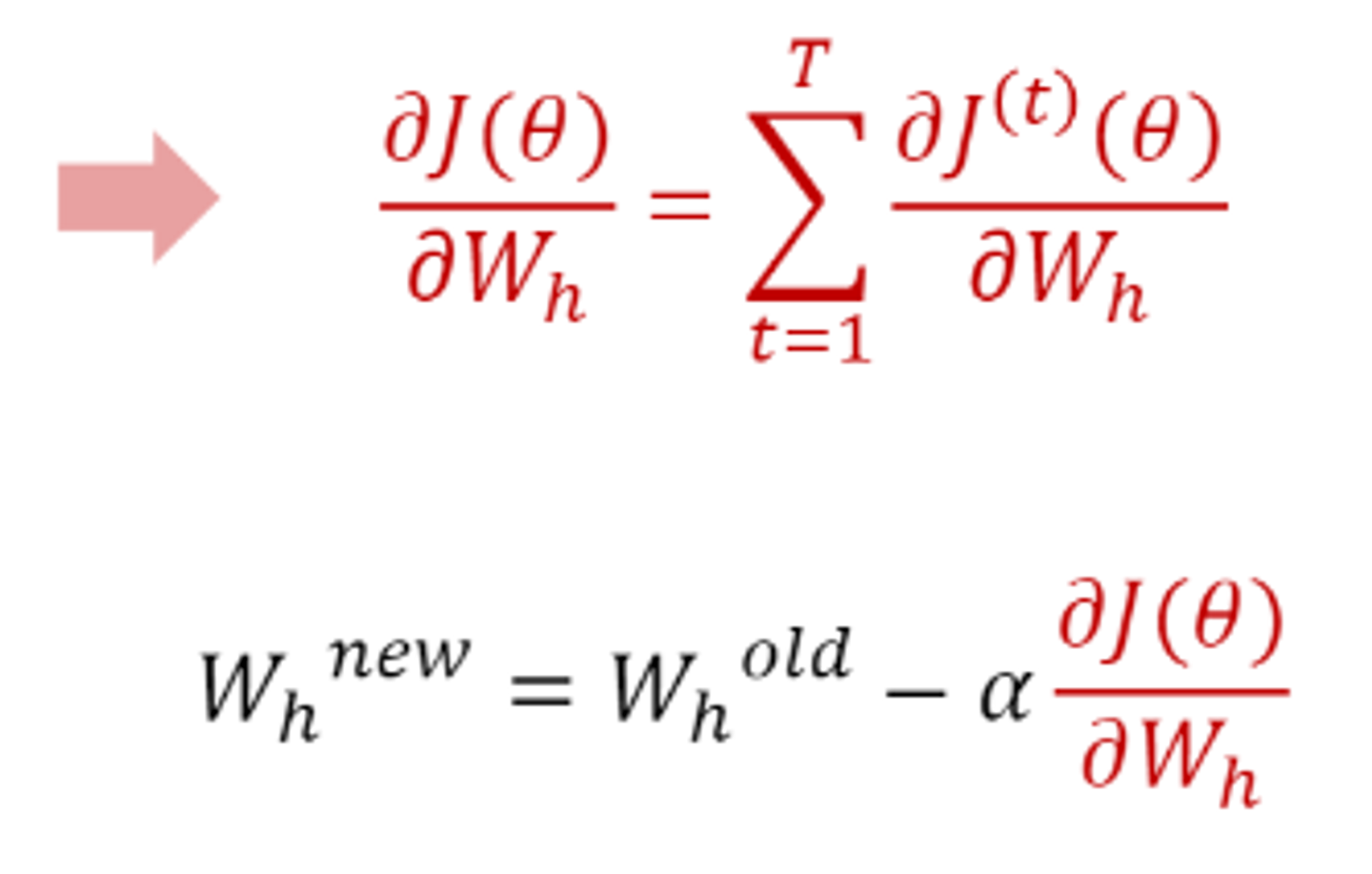
- We가중치 벡터의 업데이트도 2번과 동일한 과정으로 시행된다.
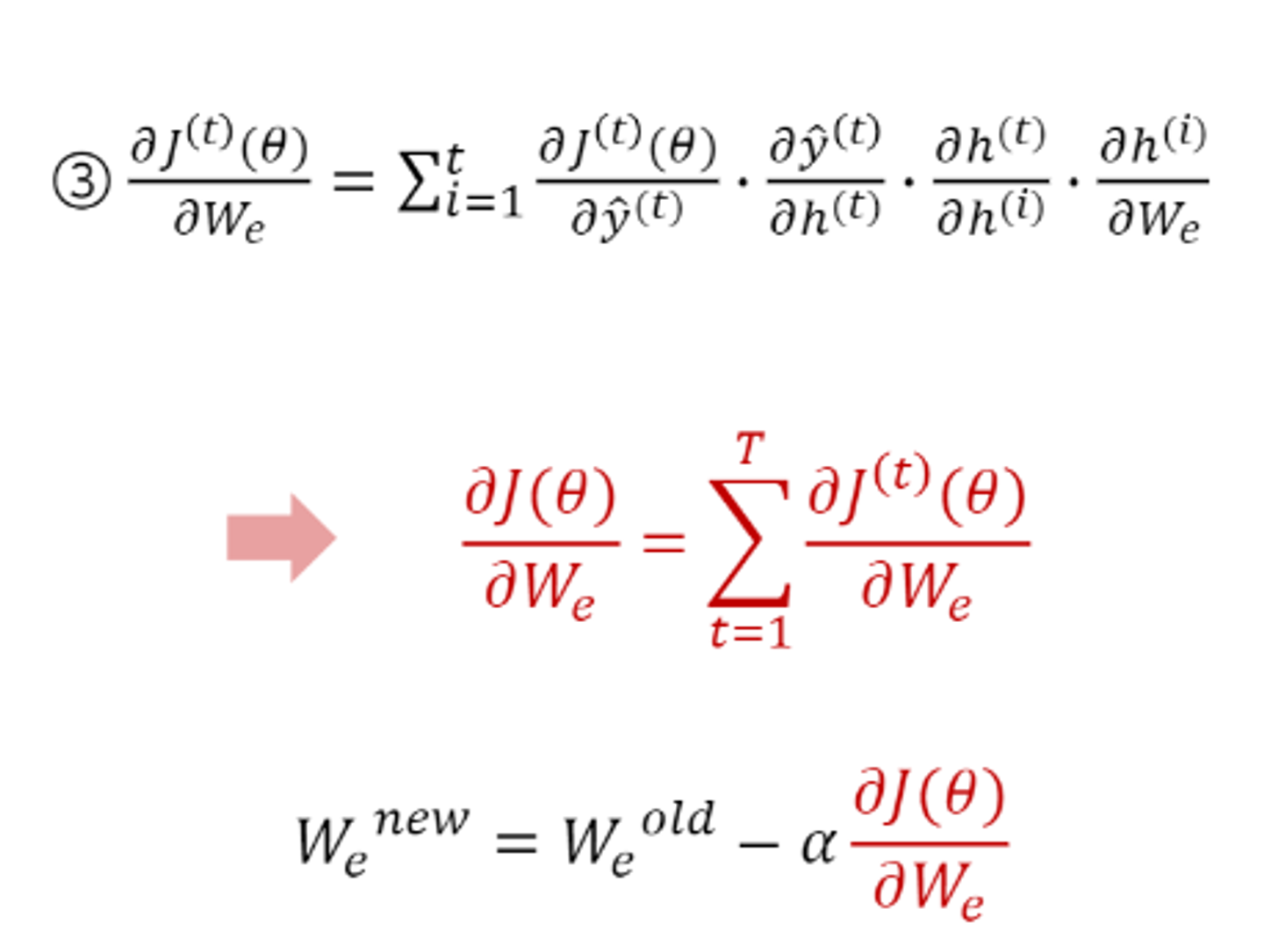
problem of RNN
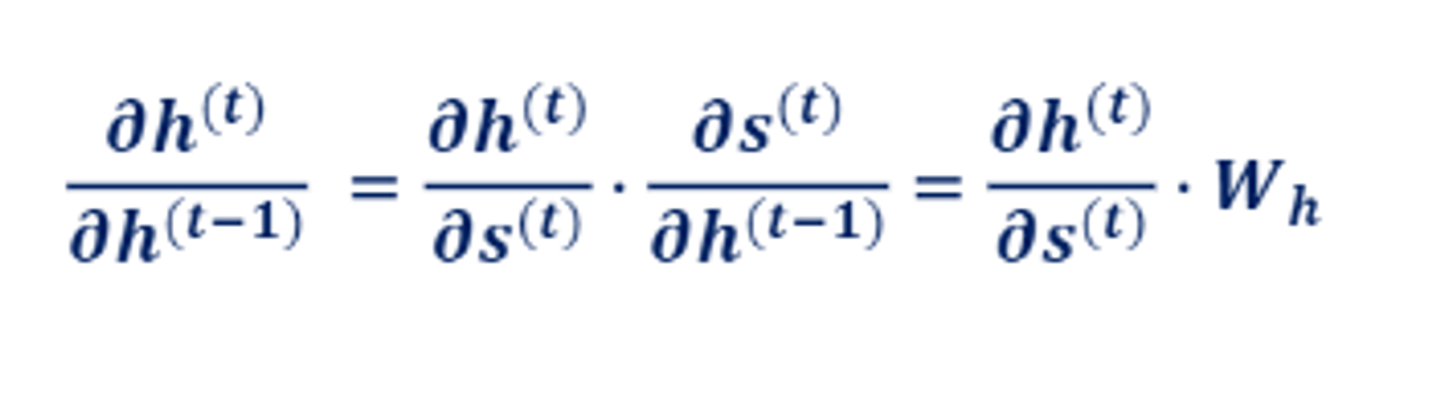
첫번째 문제는 기울기 소실 또는 폭증 문제이다.
가중치를 업데이트 할때, 다음과 같이 동일하게 Wh를 곱하는 과정이 포함되어 있다.
Wh의 값을 공유하기때문에 이를 반복적으로 곱하면, 0에 수렴하게 된다( 가중치가 1보다 작을 경우) >gradient vanishing
또는 1보다 크다면 곱하면 곱할수록 기울기가 폭증한다. > gradient exploding
이를 조금이나마 해결하려고 RNN은 sigmoid대신 tanh 함수를 채택한다.
시그모이드는 기울기가 0에서 0.25 사이이지만, tanh는 기울기가 0에서 1사이이기 때문에 gradient vanishing에 더 강하다.
두번째 문제로는 장기 의존성이다.
입력 시퀀스의 길이가 길어질 수록, 초반의 정보가 맨 뒤의 입력까지 정보가 전달이 되는지가 의문임.
이를 해결하기 위한 알고리즘이 LSTM이다.
LSTM:Long short-term Memory RNN
hidden state로는 short term memory를 조절하고, cell state를 통해 long term memory를 보존한다.
forget, input, output의 3개의 gate를 통해 매 tiem step의 cell state와 hidden state의 input에서 취할 정보의 양을 결정한다.

cell state를 정의하기 위해서는 먼저 forget gate와 input gate, new cell content를 정의해야 한다.
- forget gate
새로운 입력정보와 이전의 hidden state정보 값을 시그모이드를 취해 얻음
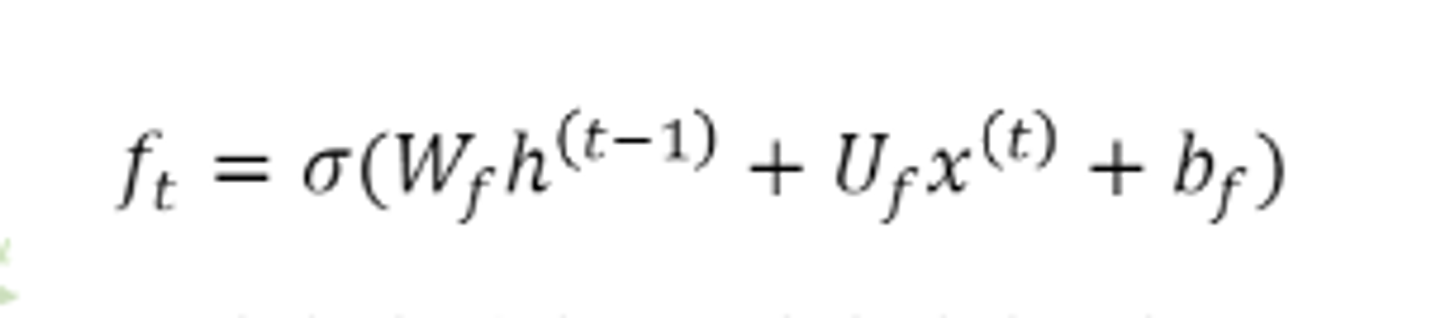
- input gate, new cell content

- cell state
forget gate에서는 이전 시점의 cell state에서 어느 정도의 정보를 가져갈 것인지 결정하고, input gate에서는 입력정보에서 장기기억으로 가져갈 정보의 양을 결정한다.

- output gate, hidden state
output gate는 입력정보에 시그몽드를 취해 도출하고, hidden state는 output으로 나온 값과 tanh를 씌운 현재 cell state를 * 해서 장기기억에서 어느 정도의 정보를 단기 기억으로 사용할 지 결정한다.
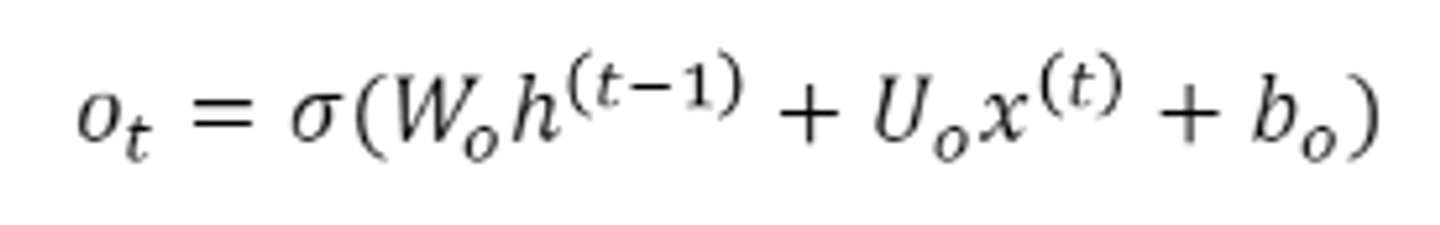
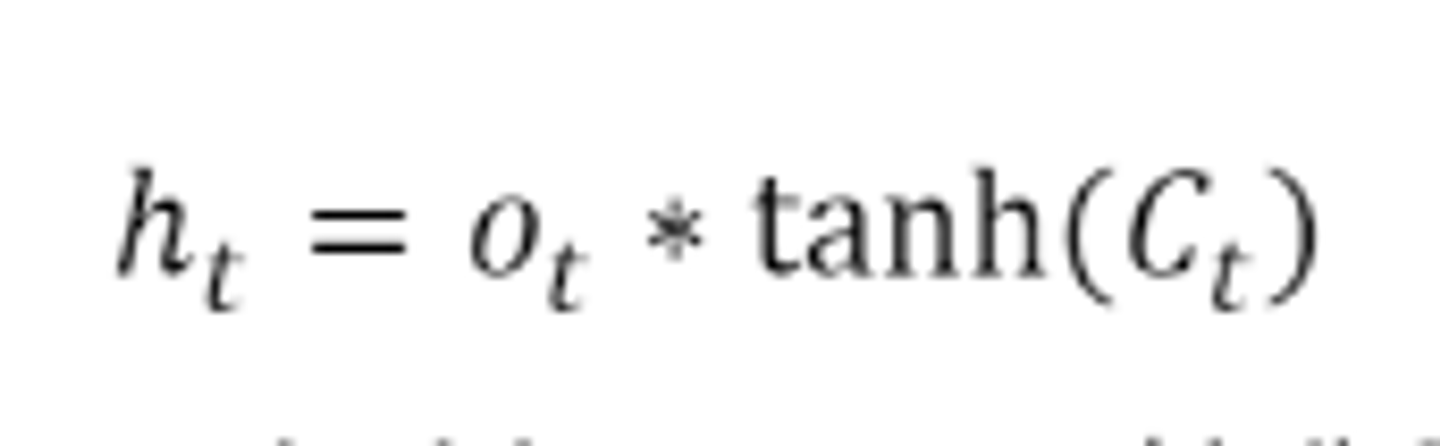
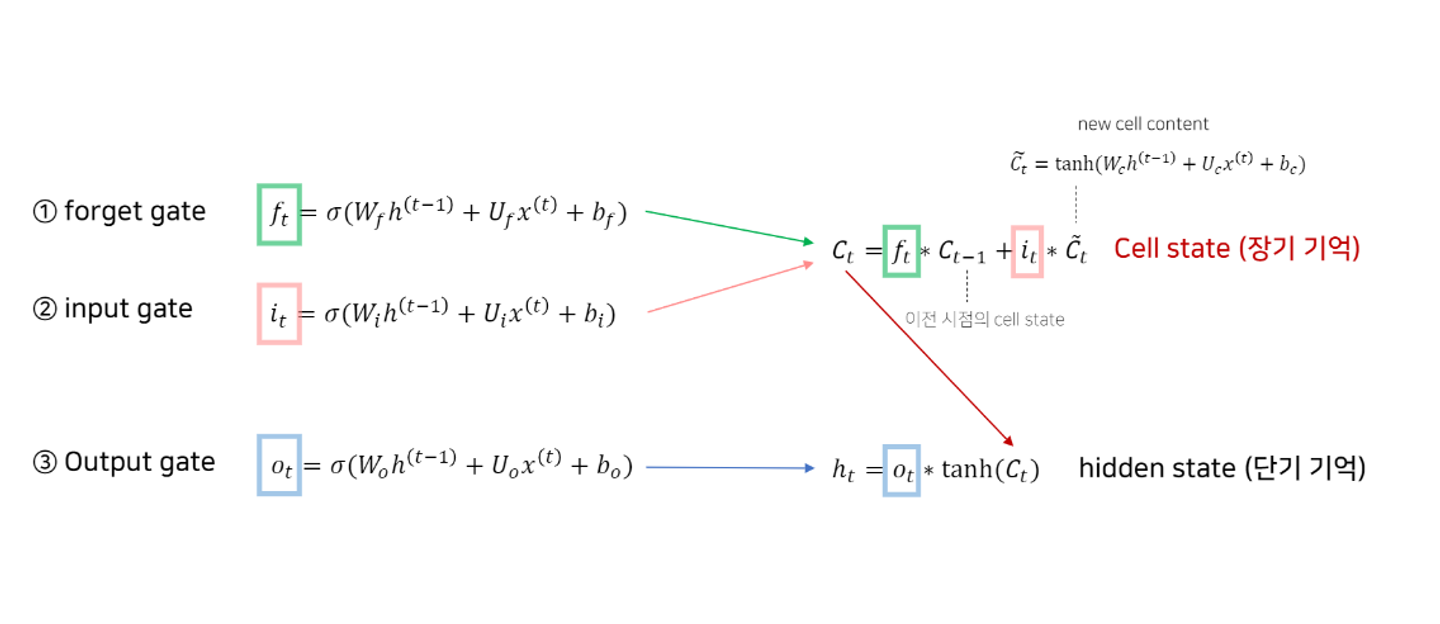
다음과 같이 정리할 수 있다.
