
이 강의는 사고의 흐름에 따라 정리되어있다.
현재 모델의 문제점을 소개하고 이를 해결하는 기술을 알려주는 방식으로 설명된다. (개인적으로 매우 마음에 들었다)
강의내용의 밀도가 굉장히 높았기 때문에 이번 포스팅에서는 Attention만 정리하도록 하겠다
(2) 에서 Transformer모델에 대해 다룰 것이다.
Recurrent model의 문제점
Recurrent model이란 순환모델이다.
즉, RNN처럼 이전 단계의 ouput이 다음단계의 input으로 사용되는 것이다. 따라서 이전 상태를 기억하고 현재상태를 예측하는 능력이 있다.
하지만 이 모델에는 치명적인 단점들이 있다.
Linear interaction distance
이 모델들은 Linear locality를 encode한다.
가까이 위치한 words는 각각의 meanings에 영향을 끼치며, 학습도 잘 된다.
예를 들어, tasty와 pizza라는 단어를 보자. 이 둘은 유사도 거리가 가깝기 때문에 학습에 지장이 없다. 하지만, chef, who, was는 이에 비해 거리가 멀다고 할 수 있다.
이렇게 벡터간 거리가 먼 단어들은 학습하기 힘들다. 많은 층이 쌓여 gradient problem이 발생하기 때문이다.
Lack of parallelizability
순환 모델은 병렬 처리 가능성이 현저히 떨어진다.
forward 와 backword pass는 sequence length 만큼의 unperallelizable operation을 가진다.
또한 미래의 state는 과거의 state가 완전히 계산되기 전에는 계산되지 않기 때문에 large dataset에서는 training이 매우 어렵다.
Recurrent model을 대체할 만한 것들
How about word windows?
제안된 것 중 하나는 word windows이다.
미리 정해진 window숫자로 그 단어 중심근처 단어만 탐색하는 것이다.
따라서, 병렬되지 않은 계산들이 sequence length에 따라 기하급수적으로 늘어나지 않는다.
또한 멀리 떨어진 단어의 경우, word window가 여러 개 쌓이면 가능하다.
최대로 상호작용 가능한 거리는 sequence length / window size 이다.
How about Attention?
Attention은 각각의 word representation을 query로 access하고, word의 정보는 value값을 통해서 통합한다.
다음 그림을 보자.
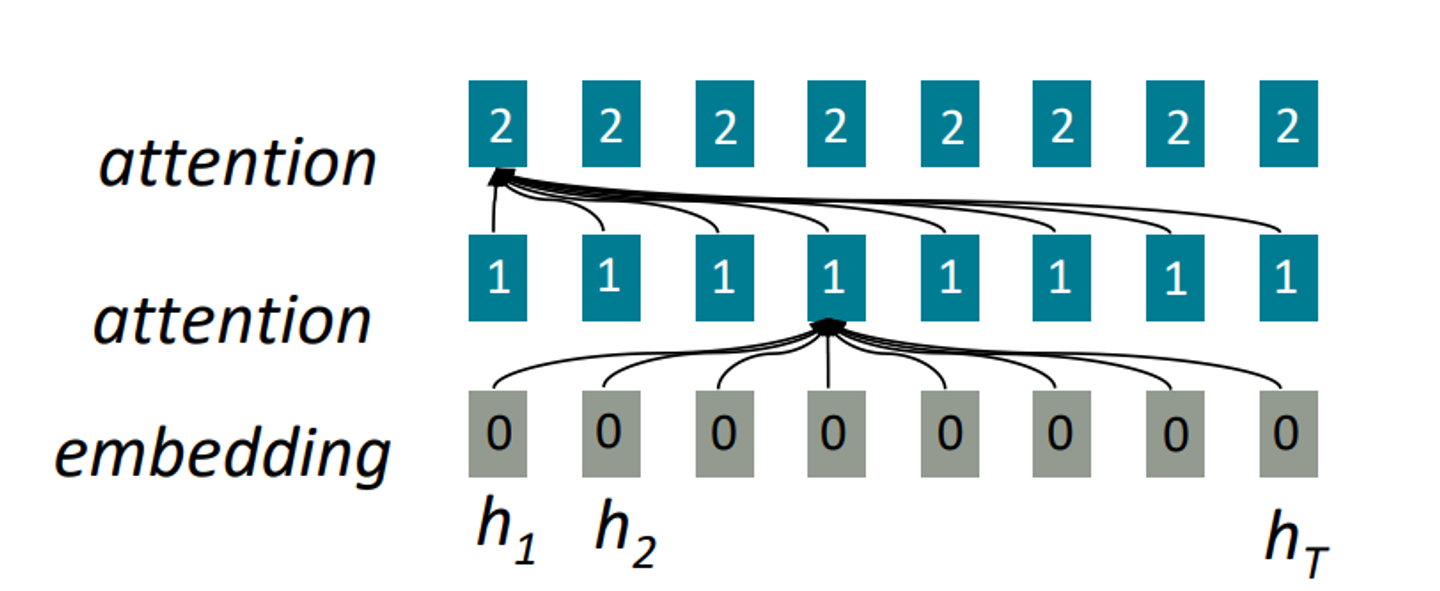
두 번째 줄의 한 단어는 이전 층에서 embedding된 층으로부터 모든 단어들의 정보를 통해 attend된 것이다.
이 또한 해당 층을 encode하기 위해서는 전의 층을 계산해야하기 때문에 깊이로써는 parallelize할 수 없지만, 시간적으로 parallelizable하다.
각각의 모든 단어의 interaction distance는 모두 이다. (거리가 얼마나 떨어져 있든 간에 )
Self-Attention 과 해결해야 할 과제들
그렇다면 이제 Attention의 과정을 알아보자.
previous layer의 ouput이 라고 하자. (단어 한 개당 vector한개)
우리는 이 X 하나당, query(), key(), value()를 지정할 것이다.
이는 모두 계산의 편리함을 위한 것이고, 결국에는 ===라고 놓을 수 있다.
query와 key와 value는 모두 같은 source에서 오는 것이다 ! !
이 값들을 통해 계산되는 dot product는 다음과 같다.
- Compute key - query affinities
query matrix를 Transpose한 뒤 key matrix와 dot product를 진행한다.
- Compute attention weights from affinities(softmax)
1에서 구한 값에 softmax를 씌여서(?) 분포를 구해준다.
- Weights for that multiplied by the value
value 값을 가중치로 하여 sum을 구해준다.
우리는 이러한 self - Attnetion을 계산하는 층을 여러층 stack하여 사용한다(LSTM층처럼 말이다)
하지만 Attention에도 해결해야 할 문제점들이 몇가지 있다.
- 각 단어들의 위치를 표현할 방법이 없다.
- 너무 선형적이다 (복잡하지 않다 )
- training할때 미래의 단어를 볼 우려가 있다.
이 3가지 문제점을 해결하기 위한 조치들을 알아보자
첫 번째 문제의 해결 : Sequence order
첫 번째 문제는 translation에 있어서 치명적이다.
Attention공식으로만은 문장에서의 단어 위치를 나타내지 못하기 떄문이다.
이를 위해서 우리는 위치를 나타내는 vector을 구축해야 한다.
이를 position vector Pi라고 표시한다.
보통 deep self - Attention에서는 이 처리를 첫 번째 층에서만 한다.
각각의 query, key, value 벡터에 대해서 position vector 를 예전의 값에 더하거나 concatenate해주면 된다!!
그렇다면 position representation vector은 어떻게 생성할까?
이를 위해 varying period의 sinusoidal function을 concatenate한다.
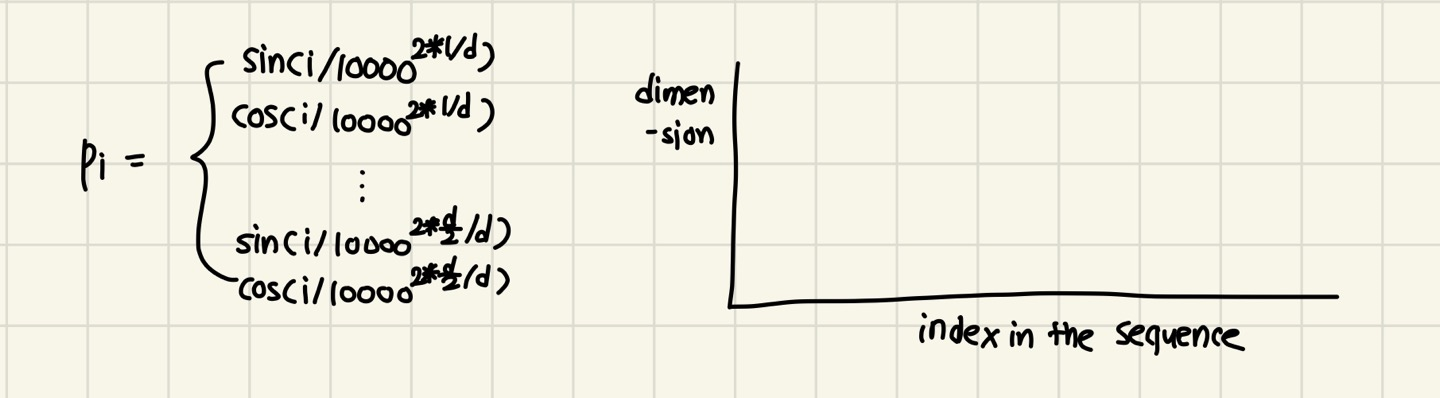
세로축이 dimension(R), 가로축이 문장의 길이(T)이다.
따라서 는 이다.
각각의 행과 열마다 다른 값을 가진다. (다 일일이 쪼개서)
이는 매우 좋은 방법이지만 학습이 가능하지 않다는 단점이 있다.
두 번째 문제의 해결 : No nonlinearities
Attention score을 계산하는 과정에 포함된 weighted average과정을 보면 알 수 있듯이 이는 모두 선형적인 결합이기 때문에 너무 간단하다는 문제점이 있다.
이를 위한 해결책은 바로 Feed Forward network를 추가하는 것이다.
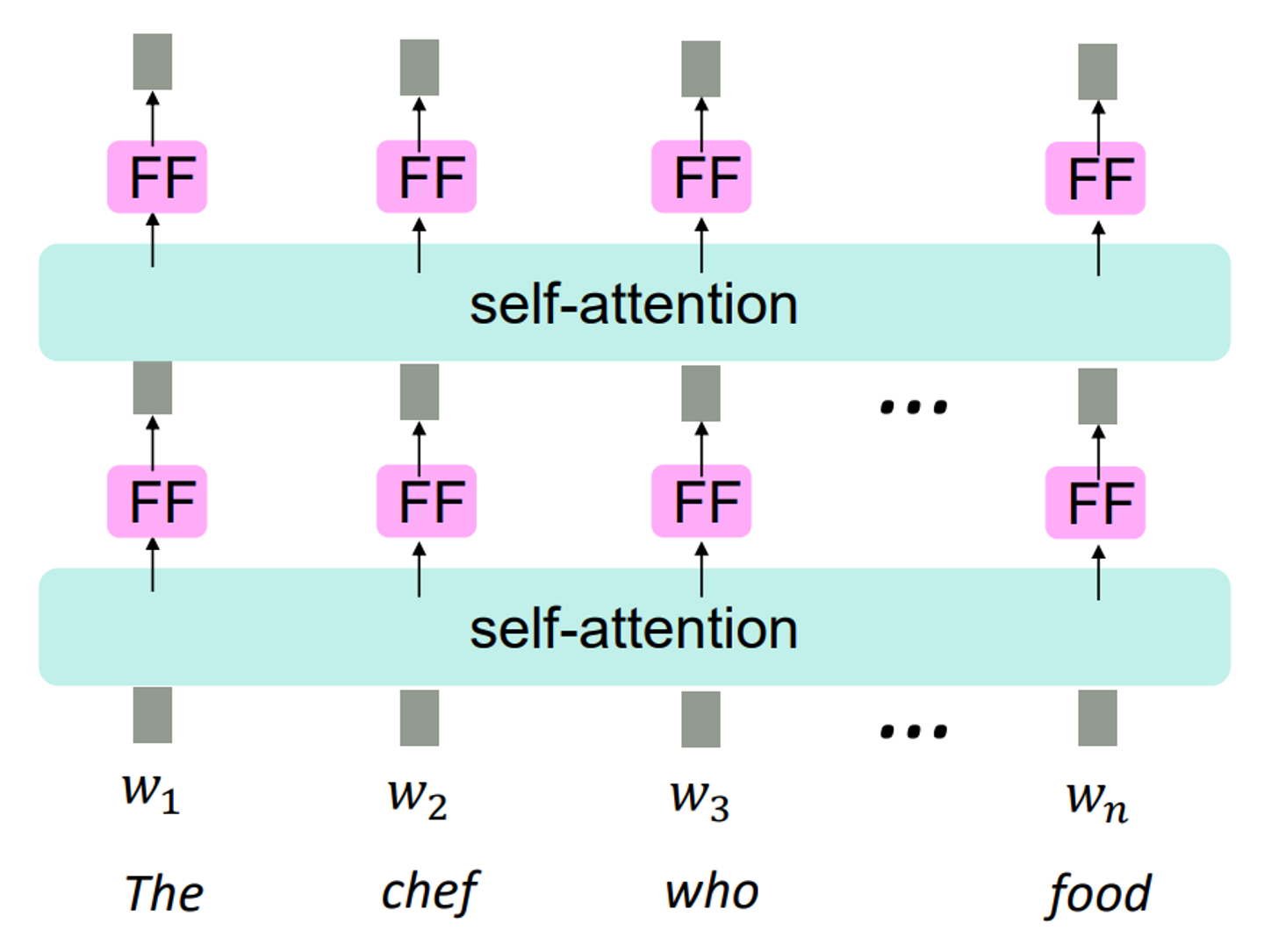
위 그림과 같이 각 단어마다 self attention을 지난 후 FF를 지나도록 설계한다.
모든 FF는 파라미터들을 공유하지만 각 단어의 self attention ouput을 입력받는다.
세 번째 문제의 해결 : Don’t look future block!
우리는 단어를 예측하는 training을 할 때 뒤의 단어를 보지 않기를 바란다.
왜냐하면 우리가 실제로 단어를 test 할때는 decoder를 이용하기 때문이다.
(오로지 현재 상태로 미래를 예측함)
따라서 미래를 cheating하는 방식으로 훈련하면 모델을 가치가 없어진다.
이를 위해서 우리는 future state를 mask하는 방식을 이용한다.
말그대로 뒤의 단어를 보지 못하도록 지우는 것이다.
수식으로는 다음과 같이 표현한다.
음의 무한대를 심어 놓는 것이다.
