
Section 1 : pre-Neural Machine Translation
이 방법은 머신러닝을 Translation에 사용하기 전 1990-2010쯤 까지 사용된 방법이다.
Statistical Machine Translation(SMT)는 데이터로부터 확률적 모델 (Probabilistic model)을 학습하여 Translation을 진행한다.
예시와 식을 통해 더 자세히 알아보자.
번역하고자 하는 input을 X, 번역되어 도출되는 ouput을 Y라고 하자.
그럼, Y는 X의 분포를 학습하기 위한 다음 식을 만족하는 값중 가장 큰 값이어야한다.
- 두번째 식에서 는 Translation model의 역할을 한다. 즉, 학습데이터로 넣어지는 parallel data를 학습하는 것으로 어떻게 번역을 잘할지에 대해서 고민하는 방향으로 학습된다. parallel data란 짝지어진 데이터를 말한다. Translation모델에서는 원어와 번역된 언어가 짝지어진 data라고 할 수 있겠다.
- 는 Language model의 역할을 한다. 이는 monolingual(1개국어)data로 학습된다. 즉, 번역되어질 언어를 어떻게 유창하게 구사할지 고민하는 방향으로 학습된다. 프랑스어를 영어로 번역하기로 하였으면, 영어를 좀 더 알맞는 문법과 어색하지 않게 도출해 낼지에 대해서 방향을 잡는 것이다.
그렇다면 다음 고민은 parallel data로 를 어떻게 학습하는 것이냐에 대한 것이다.
이를 위해 사람들은 위의 식에 변수 a를 추가하였다. >>
a는 alignment로, source data X 와 target data Y사이의 word leve correspondence를 나타낸다.
하지만, 이는 매우 복잡하다. 언어의 뜻은 한가지만 있지 않을 뿐더러, 여러가지 단어로 대체할 수 있기 때문이다. (일대일 대응이 아님 )
또한 위의 식의 값을 가장 크게 만드는 Y값을 찾기 위해서는
모든 가능한 y를 다 쪼개고 확률을 계산해야 했다. 하지만 이는 too expensive한 방법이었다.
문제가 많다. . .
Section2 : Neural Machine Translation
이젠 Translation을 위해 딥러닝을 이용한다.
neural Machine Translation은 다른 말로 sequence- to - sequence 모델이라고도 불린다.
두 개의 RNN을 포함하는 모델이다.
Neural Machine Translation, 어떻게 작동합니까
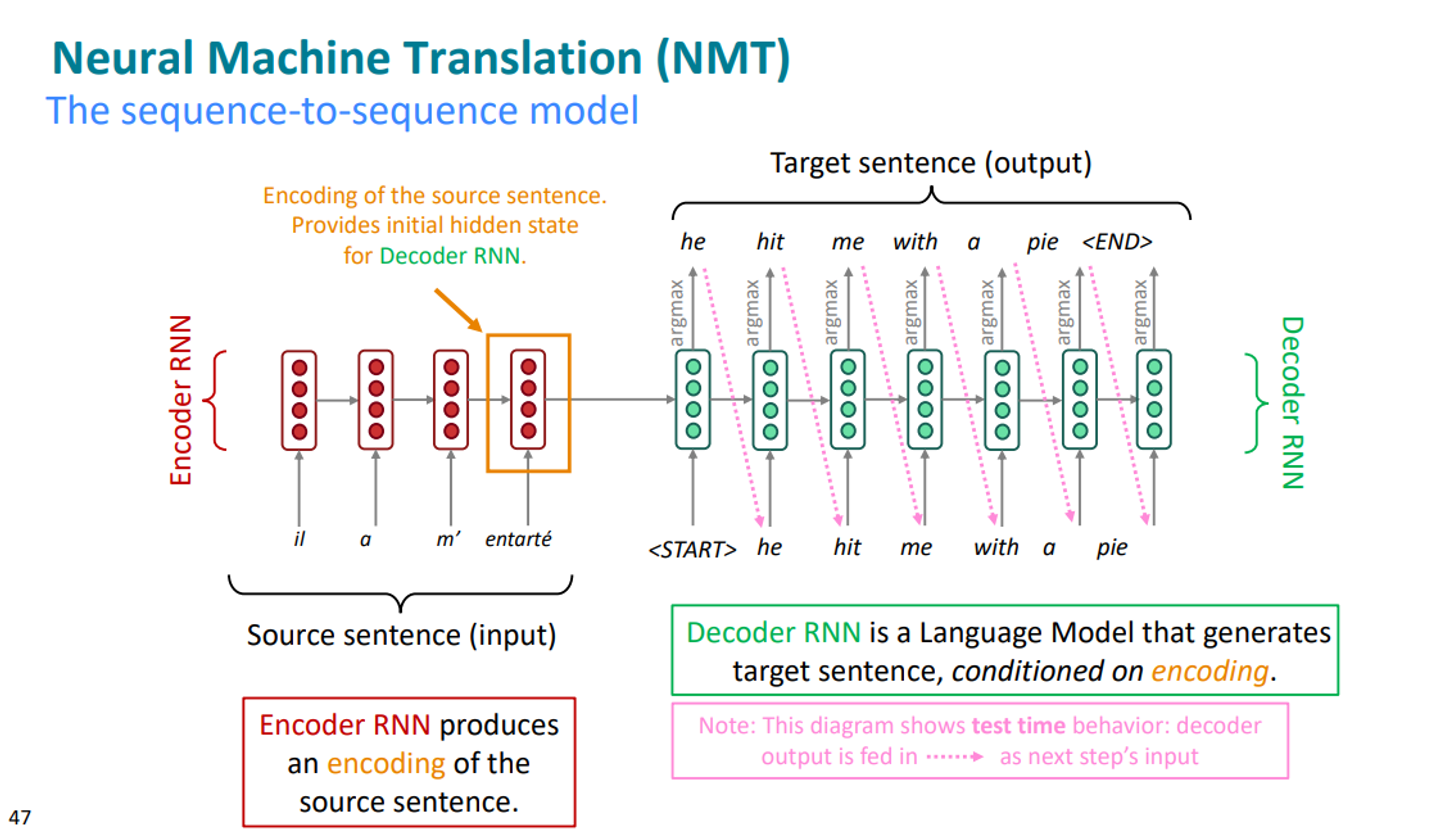
위의 그림이 개괄적인 sequence - to - sequence model의 모습이다.
input sentence를 넣는 곳은 Encoder RNN, target sentence를 생성해내는 곳이 Decoder RNN이다.
- Encoder RNN에 input sentence를 넣는다.
- RNN이므로 이 sentence에 대한 집약된 모든 정보는 마지막 hidden state에 저장된다.
- Encoder의 마지막 층의 정보가 Decoder RNN의 첫번째 층에 input된다.
- 이 정보로 Decoder는 ouput을 만들어낸다. (한 단어 씩 예측하고 그 예측은 다음 예측에 영향을 주는 방식으로)
참고로 1~4의 과정은 test 과정이다. training시에는 parallel data로 docoder만 이용한다.
sequence - to - sequence 모델은 다재다능함.
이 모델은 많은 과제들을 수행할 수 있다.
- Summarization (long text - > short text)
- Dialogue
- parsing
- code generation
Sequence - to - sequence 모델은 Conditional Language Model의 예이다.
input data 즉 source sentence X에 따라서 예측이 달라지기 때문에 “Conditional” 하다.
Decoder가 target sentence Y의 다음 단어를 예측하기 때문에 Language Model이다.
Sequence - to - sequence 모델은 single syetem 이다.
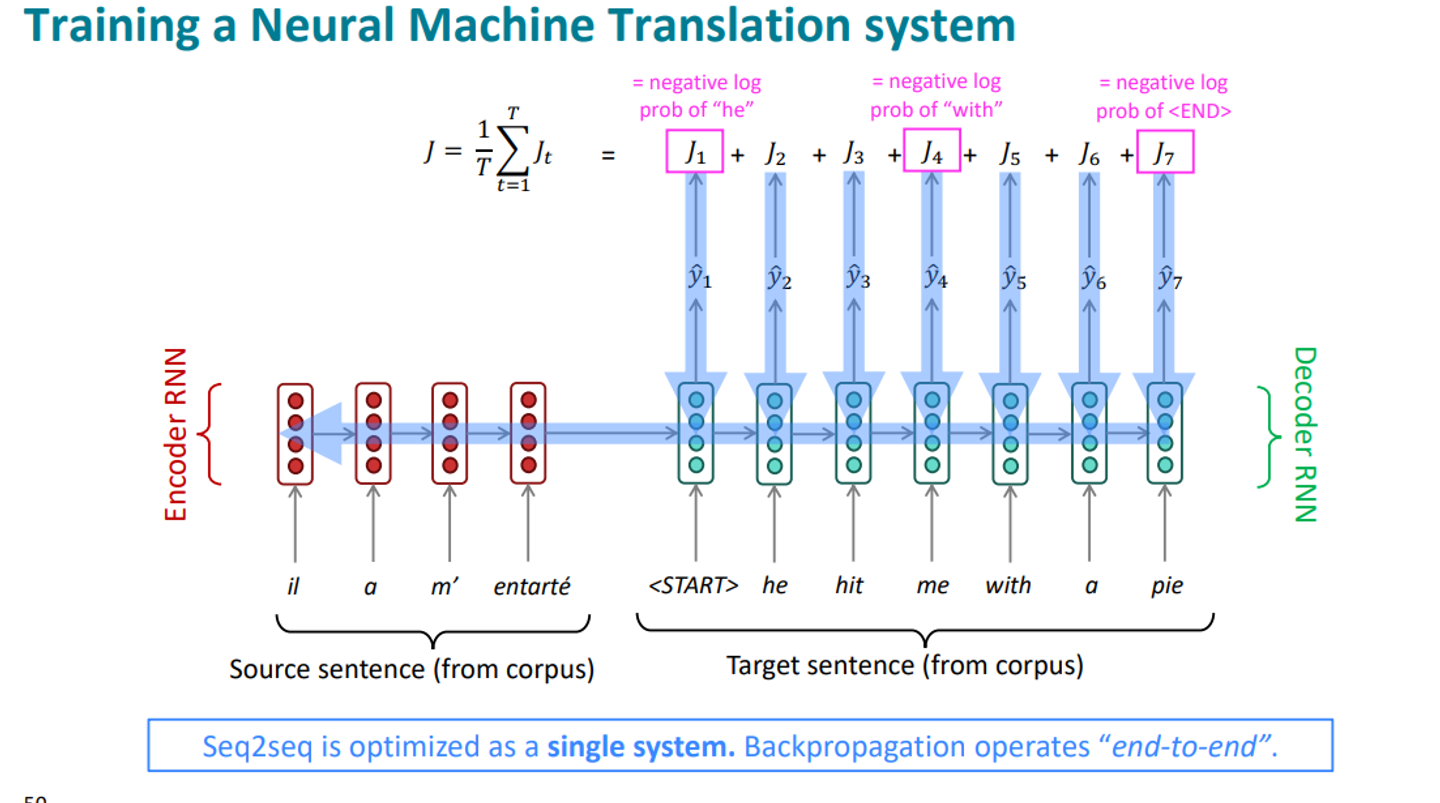
Decoder의 활동을 자세히 보자 ( training 시점 )
Decoder는 Encoder에서 받은 정보를 기반으로 한 글자씩 예측한다. 그리고, 이를 구할 때 마다 정해진 정답과 비교하여 loss를 계산한다.
그리고 이 loss가 주는 정보로 entire network를 backpropagate 한다. /
이 모든 것은 single system처럼 end to end으로 optimized된다.
Decoder의 parameter만 업데이트 되는 것이 아니라 Encoder의 parameter도 업데이트 된다.
RNN의 층은 몇 개가 적당할까
- Greedy decoding
Multi - layers RNNs는 복잡한 표현을 계산할 수 있기 때문에 주로 high - performing을 준다.
하지만, 2017 연구에 따르면 2~4개의 층이 Encoder에 적합하고, 4개의 층이 Decoder에 적합하다고 한다.
Decoder에서는 각 단어를 어떻게 예측할까?
Greedy decoding
다음을 가장 maximize하는 translation Y를 찾는다.
즉, 가장 높은 확률을 선택하는 것이다.
하지만 이 방법에는 다소 문제점이 있다.
확률이 높다고 가장 맞는 단어는 아니기 때문이다.
예를 들어보자.
The chef 뒤에 가장 많이 오는 단어는 be동사 is 라고 선택될 수 있다.
하지만 이 문장에서는 주격관계대명사 who 가 뒤에 온다…!
또 하나의 문제점은 잘못된 선택을 한 경우 되돌아 갈 수 없다는 것이다.
이를 위해 다른 방법이 제안된다.
Beam search decoding
Decoder의 각 단계에서, partial translation이 가장 probable한 k개를 계속 따라가는 방법이다.
즉, 아래의 사진에서 두번째 단어가 he, I로 예측됨에 따라 세번째 단계에서는 총 4가지의 경우의 수가 생긴다. 여기서, k를 2라고 설정한다면, 이 4가지 경우에서 가장 log probability score이 높은 2가지만 ( hit, was) 선택하고 나머지는 배제하는 것이다.
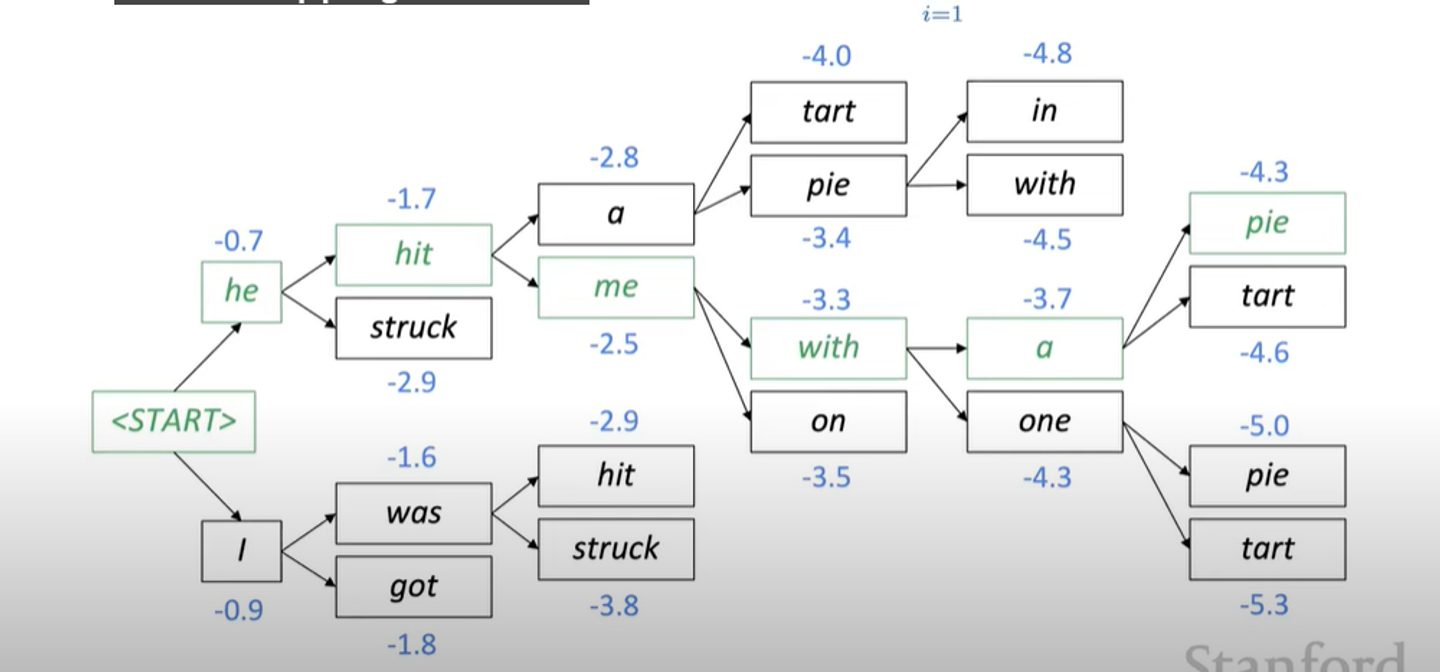
greedy decoding에서는 모델이 토큰을 produce할때 까지 decode한다.
beam seach decoding에서는 , 각각의 가정과 다른 timestamps마다 token을 배출할 수도 있기 때문에 위와 같은 방법은 사용하지 못한다.
따라서 beam seach에서는 미리 정해둔 (pre - defined cutoff) timestamp T에 다다르거나 , 최소한 n개의 가정들을 가지자고 설정한 것에 다다르면 decoding을 멈춘다.
각 단어의 probabilty를 계산하는 식은 greedy와 동일하다.
하지만, 문장의 길이가 길수록 이 score가 낮아지는 경향이 있기 때문에 문장의 길이로 평균을 낸 값을 이용할 수도 있다.
이 모델을 어떻게 evaluate 합니까?
가장 정확한 것은 사람에게 맡기는 것이다. Translation이기 때문에 사람의 판별이 가장 자연스럽고 정확할 것이다. 하지만 물론 비용이 너무 많이 든다.
BLEU(Bilingual Evaluation understudy) 라는 지표를 사용한다.
이는 machine - written translation과 한 명 또는 여러 human - written translation을 비교하고 similarity score을 계산하는 것이다
n-gram을 이용하여 평균을 구하되, 너무 번역한 문장이 짧으면 penalty를 부과한다.
BLEU는 유용하지만 완벽하진 않다. 사람의 언어는 같은 뜻을 지닌 수많은 문장이 있기 때문에 similarity score가 운이 좋게 겹칠수도, 안겹칠수도 있기 때문이다.
Section3 : Attention
section2에서 설명한 Encoder- Decoder모델에는 치명적인 문제점이 있다.
바로 input sentence의 정보를 Encoder RNN의 마지막 state에서밖에 얻지 못한다는 것이다.
Encoder RNN에서 마지막 state에 문장의 모든 정보가 담겨 있기 떄문이다.
따라서 마지막 state에서 source sentence에 대한 모든 정보에 대해서 계산해야 한다.
이를 information bottleneck이라고 불린다.
이 모든 문장 벡터들을 평균내서 표현하는 방법은 감정분석같은, 내용 파악에는 좋을 수 있지만 문장의 순서가 중요한 translation에는 별로 좋지 않다.
따라서 고민은 이것이다.
Decoder에서 translationg을 하면서 더 많은 source sentence정보를 얻을 수 있지 않을까?
사람이 번역을 할 때를 생각해보자. 우리는 일부를 번역하다가 다시 번역해야 할 문장으로 되돌아 확인한다. 이와 같은 방법을 사용할 수 있지 않을까?
이것이 바로 Attention의 시작이다.
Decoder의 각 step에서 use direct connection to the Encoder to focus on a particular part of the source sequence.
How it works?
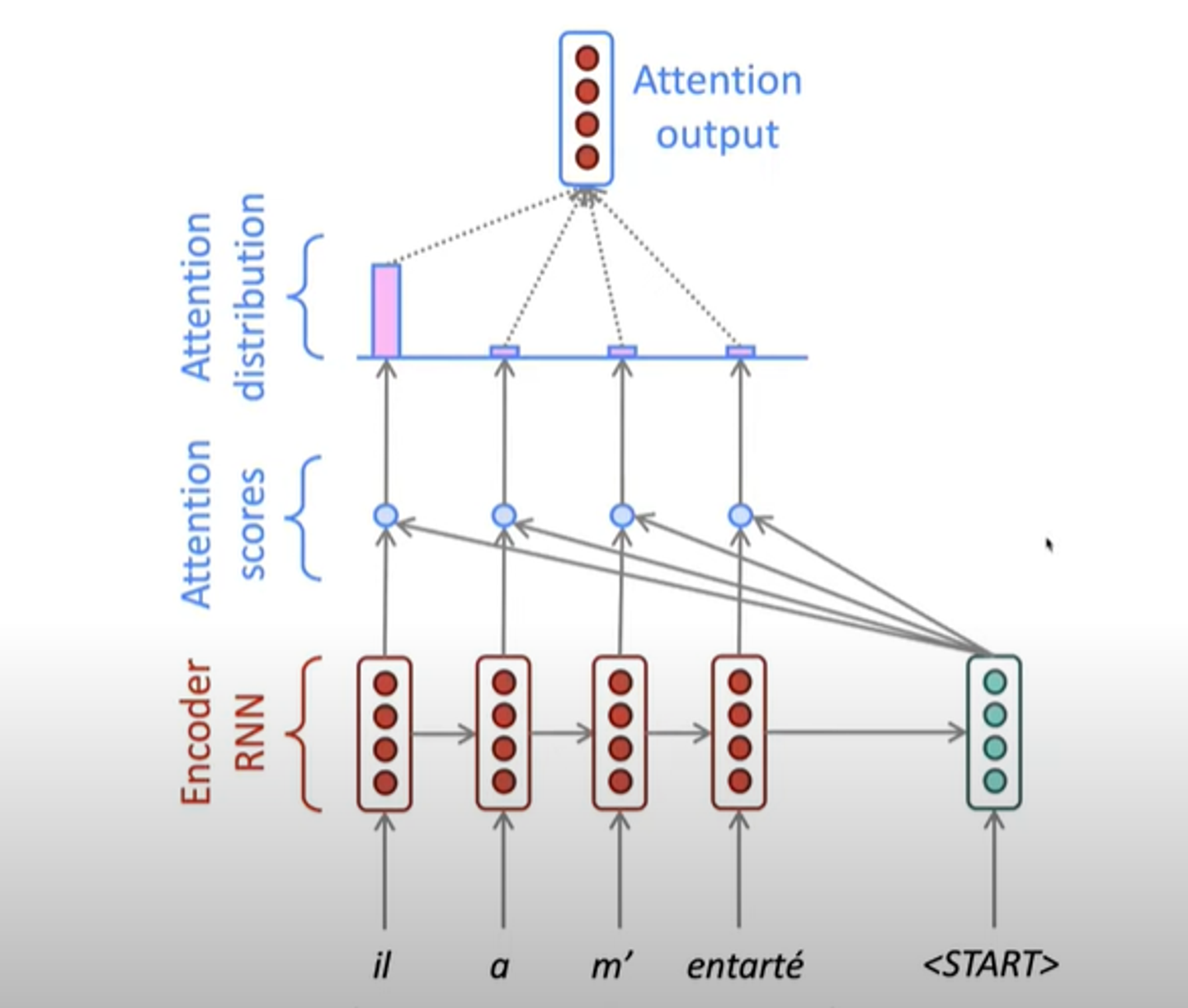
- Decoder의 hidden state와 각각의 포지션의 Encoder hidden state를 coompare하고 attention score을 계산한다. 이는 dot product로 similartiy score와 같은 종류이다.
- Attention score을 기반으로 probability distribution 을 계산한다(softmax이용) 어떤 Encoder state이 그 Decoder state와 가장 맞을지를 나타내는 것이다
- 제일 높은 Attention distribution의 Encoder를 선택한다.
- Attention output을 Decoder hidden state와 Concatenate하여 을 계산한다 .
