
이 포스팅에서는 Tranformer모델에 대해서 알아볼 것이다.
목차는 다음과 같다.
The Transformer Encoder - Decoder
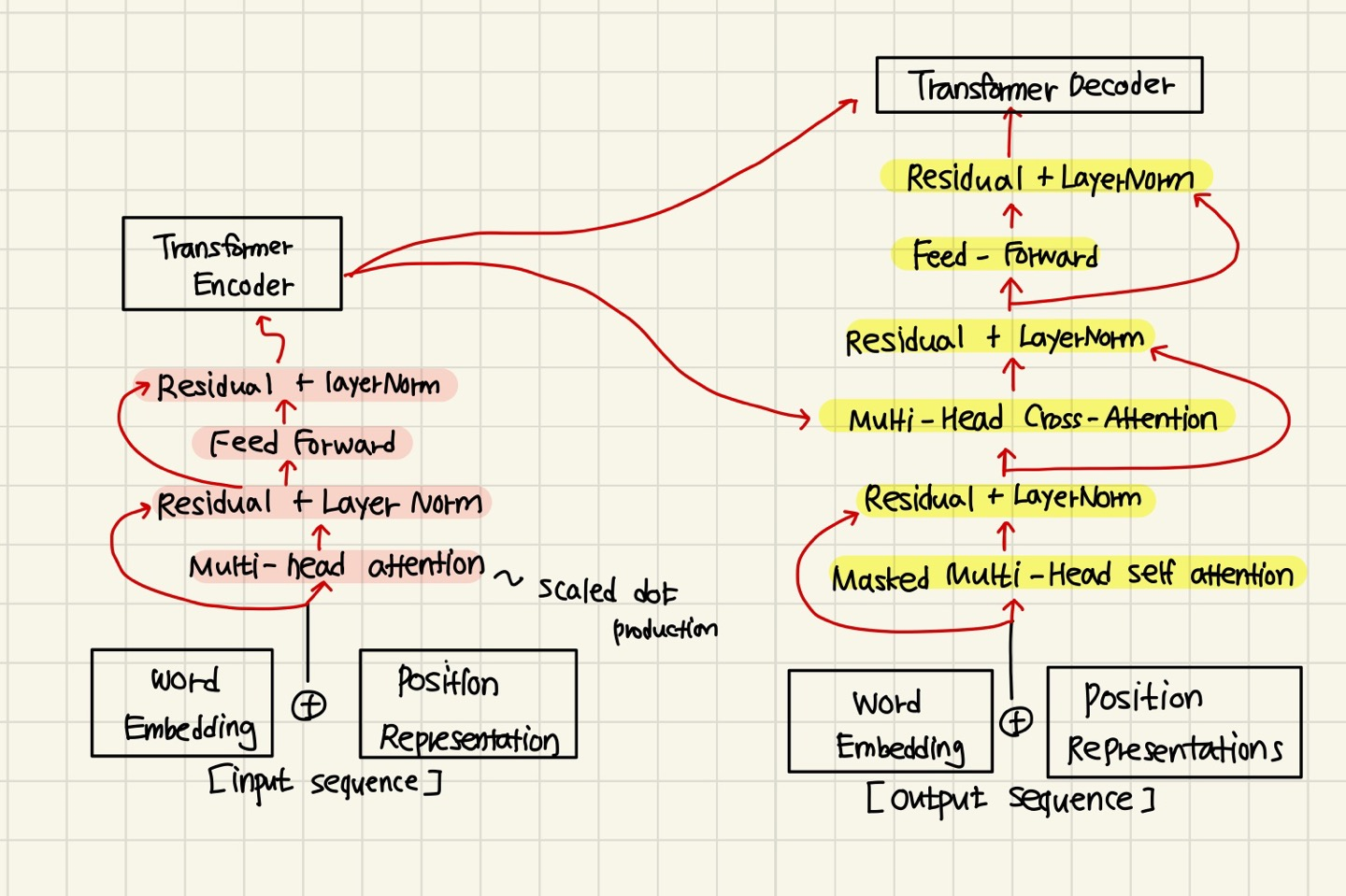
각각 Transformer Encoder 두 번, Transformer Decoder을 두 번씩 지난다.
Encoder와 Decoder의 내부 과정은 위의 그림과 같다.
이제 우리가 공부해야 할 것들은 다음과 같다.
- key-query-value을 하나의 word embedding에서 어떻게 얻을 것인가?
- Multi-head attention은 무엇인가?
- training을 도와주기 위한 몇 가지 트릭들 : Residual connection, layer Normalization, scalling dot product
Transformer Encoder : key,query,value Attention
앞의 내용을 복귀해보자.
query는 현재 처리 중인 단어에 대한 벡터로서, 다른 단어와의 연관된 정도를 계산하기 위한 기준이 되는 값이다.
키는 단어와의 연관된 정도를 결정하기 위해 query와 비교하는데 사용되는 벡터이다.
value는 특정 key에 해당하는 입력 시퀀스의 정보로, 가중치 벡터의 역할을 한다.
각 인코더의 input vector 로 부터 3개의 벡터를 생성한다.
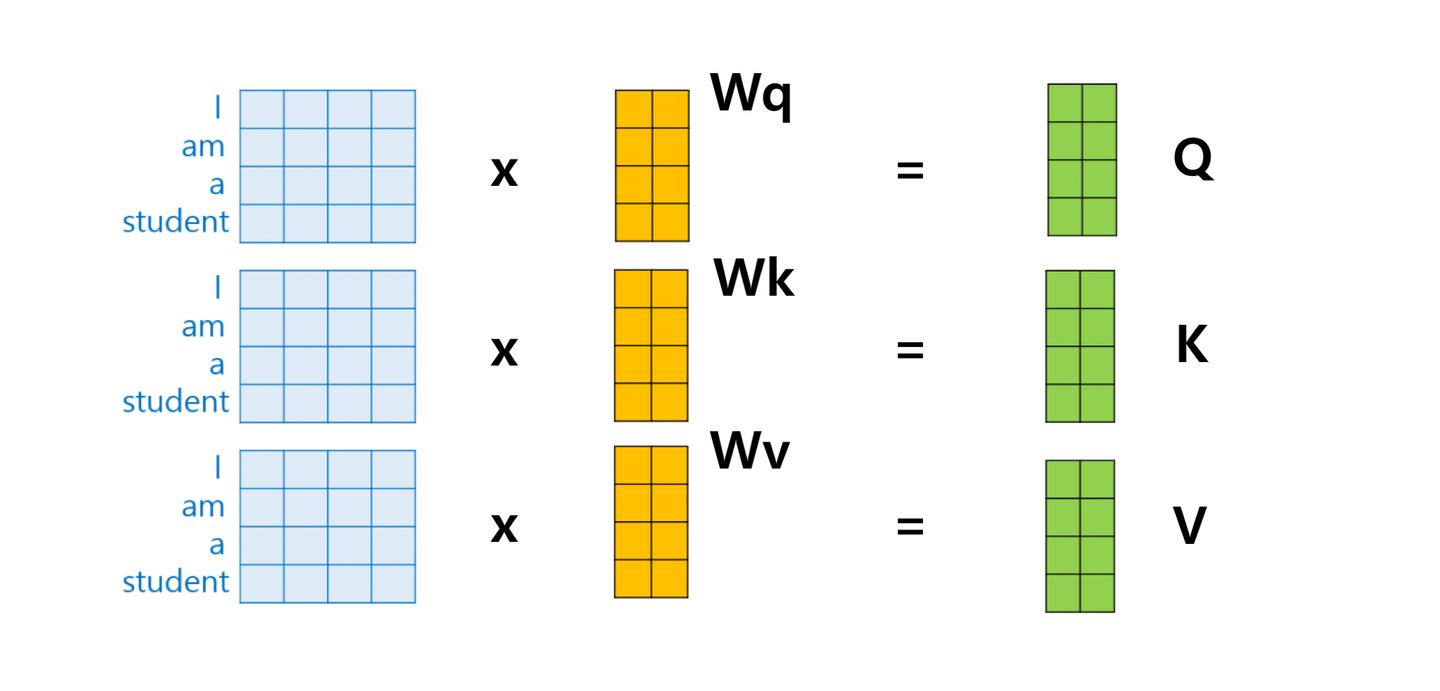
이 메트릭스들은 input vector W에 대해서 세가지의 다른 측면들을 계산하고 강조하도록 한다. (여러가지의 방면을 볼 수 있도록 )
최종적으로 나오는 output은 이다.
Transformer Encoder : multi-headed Attention
Transformer는 한번의 Attention보다 Attention을 병렬로 여러 번 사용하는 것이 더 효과적이다.
병렬로 하면 다른 시각으로 정보들을 수집 가능하기 때문이다.
따라서, 여러 head로 나누어 병렬 계산을 하도록 하는 것이 multi-headed Attention이다.
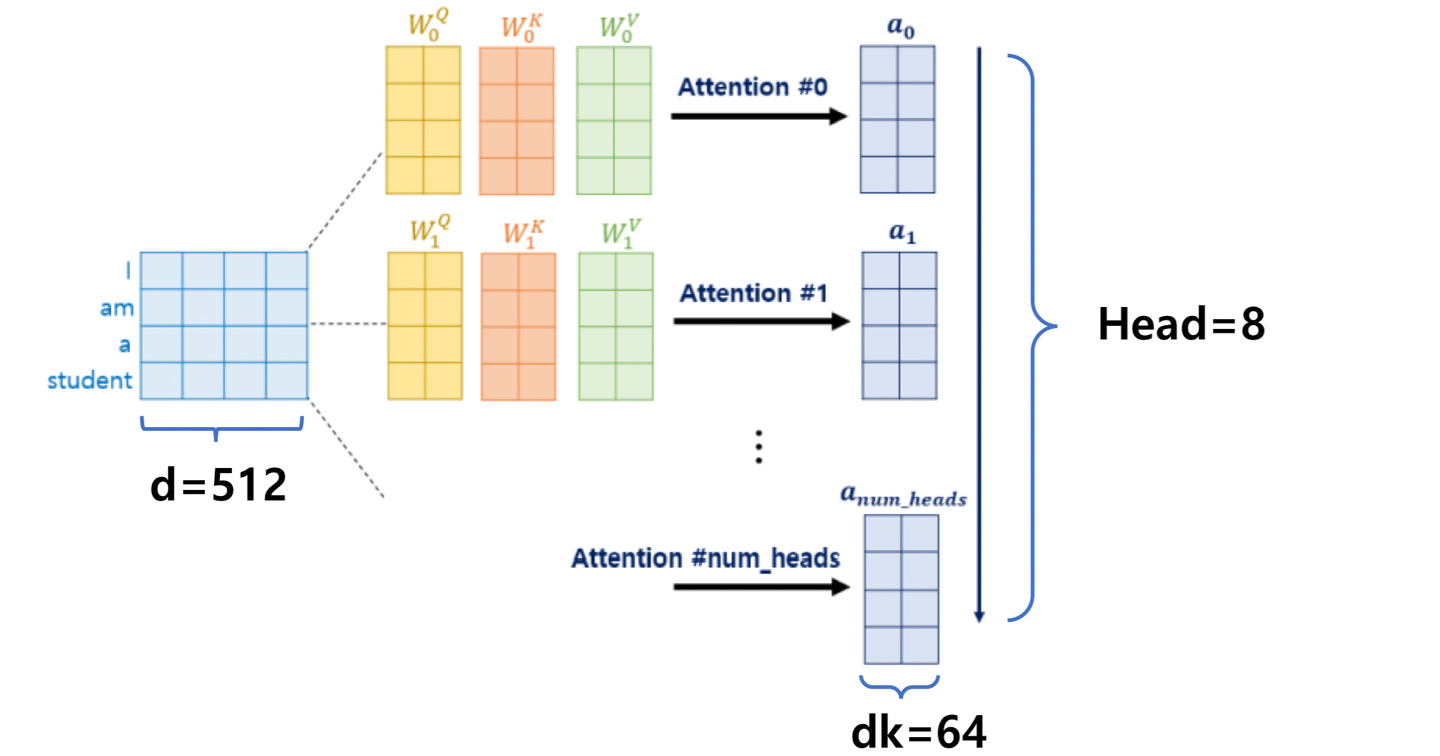
위의 그림에서는 head=8로 설정하였다.
따라서 K,Q,V세트가 총 8개가 나오고, 각각의 세트의 길이는 64이다( 512/8)
로 표현할 수 있다.
h는 head의 개수, L은 1~h의 수이다.
각각의 attention head에서 attention계산을 독립적으로 수행한 뒤 concatenate한다.
single - head attention을 하는 것과 계산 양은 동일하다.
Transformer Encoder : Residual connections
Residual connection은 모델의 train을 좀 더 잘할 수 있게 도와주는 trick이다.
원래는 이었다. 여기서 i는 layer을 나타낸다.
그림으로 표현하면 아래와 같다.

하지만 Residual connection을 실행하게 되면 다음과 같은 식이 성립한다.
즉, 우리는 previous layer로 부터 잔차를 학습할 수 있게 된 것이다. 그림으로 표현하면 아래와 같다.
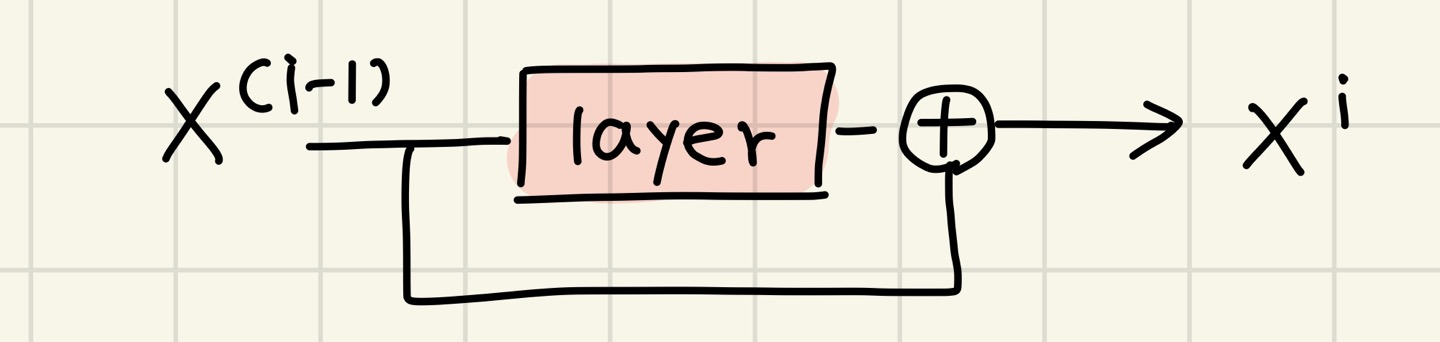
이 connection은 gradient관련 문제도 발생시키지 않는다.( 아주 훌륭한 connection이라고 칭찬한다..)
또한, 이 장치는 loss landscape를 상당히 smooth하게 만들어준다. (training이 쉬워지는 이유)
Transformer Encoder : Layer Normalization
이 장치는 train이 빨라지도록 도와준다.
아이디어는 이렇다. 학습을 시키기 전에 uninformative variation을 미리 잘라내면 더 효율적이지 않을까 ?? 하는 것이다.
이를 위해 각 layer에서의 평균과 표준편차를 통해서 normalize를 시켜주자 ! 라는 주장이 나왔다.
수식은 다음과 같다.
여기서 시그마는 표준편차, y는 gain, 베타는 bias이다.
Transformer Encoder : Scaled Dot Product
dimensionality를 뜻하는 d가 너무 커지면 vector 사이의 dot product가 너무 커질 수 있다.
softmax안에 들어가는 값이 너무 커지면 이는 gradient를 너무 작게 만들기 때문에 좋지 않다.
따라서, softmax 안에 들어가는 값을 으로 나누어준다.
Transformer Decoder : Cross-attention
cross - attention은 Decoder에서만 일어나는 특이한 attention이다.
이는 Decoder에서는 Encoder의 값의 일부가 사용되기 때문에 일어나는 것이다.
간단히 하면, key값과 value는 Encoder에서 나온다. (like a memory) Encoder에서 나온 output vector에서 나온다는 뜻이다.
query는 Decoder에서 나온다. Decoder에 넣어진 input vector에서 나온다는 뜻이다.
을 concatenation of encoder vectors라고
을 concatenation of decoder vectors라고 정의하자.
그러면 output공식은 아까 배운것처럼
이 성립된다.
