1. 분류(Classificiation)
: 출력값이 범주형(label)인 지도학습 문제
- 절차: 입력 x로부터 점수를 만들고 -> 그 점수를 확률로 바꾸고 -> 임계값을 기준으로 최종 클래스 만듦
- 예) 임계값이 0.5일 때, 0.5보다 크면 1(양성)이고 아니면 0(음성)
- 종류
- 이진 분류(Binary)
- 클래스 2개
- 스팸/정상
- 다중 분류(Multi-class)
- 클래스 3개 이상
- A/B/C 등급
- 다중 라벨(Multi-label)
- 여러 라벨 동시 가능
- 이미지에 사람 + 자동차 + 동물클러스터링과의 차이점
- 분류는 입력 데이터를 하나 이상의 미리 정의된 클래스 중 하나로 예측하는 문제이다.
- 이진 분류(Binary)
2. 단일 모델(Baseline)
- 모델을 하나만 써서 학습/예측하는 방식
- 역할: 비교 기준
- 머신러닝에서 모델을 만들 때 바로 XGBoost 같은 고급 모델로 가면 위험함.
- 내가 만든 피처가 좋은 건지
- 모델이 좋아서 성능이 나온 건지
- 누수가 있는 건지
- 운이 좋은 건지
- 이러한 판단 기준이 존재하지 않기 때문에, 단순한 모델로 일단 성능을 찍어보고, 그걸 기준으로 개선해 나가는 것
- 다만, Baseline 모델에서 성능을 개선한 피처라도, 모든 모델에서 항상 유효한 것은 아님. Baseline은 피처의 정보 유무를 확인하는 도구이며, 복잡한 모델에서는 해당 정보를 어떤 형태로 사용하는지가 오히려 더 중요함.
- 머신러닝에서 모델을 만들 때 바로 XGBoost 같은 고급 모델로 가면 위험함.
1) 선형 모델
- 입력 특징의 가중합(=선형 결합)으로 점수를 만들고, 그 점수로 클래스 구분
가중치는 사람이 규칙처럼 정하는 값이 아님!
score=w1x1+w2x2+⋯+wnxn+b- 모델은 정답(label)이 있는 데이터를 보고
- 예측과 실제의 차이(Loss)를 계산한 뒤
- 그 차이가 줄어들도록 가중치를 조금씩 조정한다
이 과정을 반복하면서,
- 어떤 피처가 정답을 잘 설명하면 → 가중치 크기 ↑
- 정답과 반대로 작용하면 → 가중치 부호가 음수로 이동
- 의미 없는 피처면 → 가중치가 0에 가까워짐
1-1) Logistic Regression
-
가중합으로 만든 점수를 "확률"로 바꿔서 분류하는 모델
score=w1x1+w2x2+⋯+wnxn+b
해당 score는 -5, 3.2, 17 같은 아무 범위의 숫자라서 "폐업 확률이 73%다"처럼 해석할 수 없음.
그래서 score를 그대로 쓰지 않고 확률로 바꾸는 과정이 필요함 -> Logistic Regression -
시그모이드 함수: P(y=1∣x) = 1 / (1 + e-score)
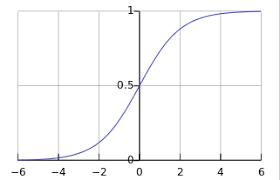
-
score를 시그모이드 함수에 통과시키면 아무 범위의 점수(score)가 항상 0과 1 사이의 값으로 변환됨.
- score → “양성(1) 쪽으로 얼마나 기울었는지”를 나타내는 내부 점
- sigmoid(score) → “양성일 확률”로 해석 가능한 값
-
예시
- score = 0 → sigmoid(0) = 0.5 (폐업/존속이 반반)
- score > 0 → 폐업일 확률이 0.5보다 큼
- score < 0 → 폐업일 확률이 0.5보다 작음
이때 score = 0은 확률이 0.5가 되는 기준선이며,
모델이 클래스를 나누는 결정 경계(decision boundary)가 됨. -
따라서 로지스틱 회귀에서 분류란,
- 가중합으로 점수(score)를 만들고
- 그 점수를 시그모이드로 확률로 변환한 뒤
- 임계값(threshold)을 기준으로 최종 클래스를 결정하는 과정
기본적으로 임계값은 0.5를 사용하지만, 문제의 목적에 따라 이 값은 얼마든지 조정할 수 있다.
결국 로지스틱 회귀는 선형 모델로 만든 점수를 사람이 해석할 수 있는 “확률”로 바꿔주는 분류 모델임.
| 구분 | 내용 |
|---|---|
| 장점 | 확률 출력 가능, threshold 조절 쉬움, 계수 해석 가능, 안정적인 baseline |
| 단점 | 비선형 관계 한계, 이상치에 민감, 고차원 sparse 데이터에서 약할 수 있음 |
| 언제 쓰나 | 확률/점수화가 필요할 때, 설명 가능성이 중요할 때, tabular 데이터 |
| 핵심 튜닝 | 정규화 강도, L1/L2, class_weight |
정규화 강도
- 가중치를 얼마나 세게 누를지 정하는 값
- 값 ↑ → 가중치 ↓, 과적합 ↓
- 값 ↓ → 데이터 적합 ↑, 과적합 ↑
(sklearn: C = 1 / 정규화 강도)
L1 / L2 정규화
- L1: 중요 없는 피처 가중치를 0으로 만듦
→ 자동 피처 선택, 피처 많을 때 유용, 해석 쉬움 - L2: 모든 가중치를 조금씩 줄임
→ 안정적, 성능이 대체로 좋음
class_weight
- 클래스마다 “틀렸을 때 벌점”을 다르게 주는 설정
- 데이터 불균형 시 사용
(소수 클래스 실수 → 더 크게 벌점)
딥러닝 분류 모델의 출력층은 로지스틱 회귀 구조를 따름.
로지스틱 회귀에서도 log loss와 gradient 기반 학습이 사용되지만,
이 단계에서는 “왜 이런 구조가 필요한지”를 이해하는 것이 목적임.
실제로 loss를 미분하고 가중치를 업데이트하는 구체적인 계산은
딥러닝에서 훨씬 일반화되고 본격적으로 다뤄짐.
1-2) Linear SVM
- 클래스를 나누는 직선을 그리되, 가장 가까운 데이터들과 최대한 멀어지게 그리는 모델
- Logistic Regression은 score를 확률로 변환하여 사용했지만, Linear SVM은 확률로 안 바꿈.
- 로지스틱 회귀: "각 공이 빨강일 확률을 계산해서 0.5 넘으면 빨강, 아니면 파랑"
- Linear SVM: 선은 하나만 긋는데, 그 선이 어떤 공에도 너무 가까이 가지 않게 최대한 안전한 위치에 긋기
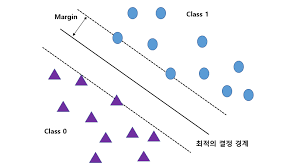
경계(margin)에 있는 점 = Support Vector
- Hard Margin
- 한 점도 예외 없이 전부 마진 밖에 있어야 함.
- 노이즈 한 개만 있어도 실패
- 이상적인 세계( y⋅(w⋅x+b)≥1∀i )
- Soft Margin
- 대부분은 마진 밖에 있게 하되, 못 지키는 점들은 벌점을 주고 허용하기
- y⋅(w⋅x+b)≥1−ξi(ξi = 얼마나 규칙을 어겼는지, 0이면 완벽)
- Linear SVM의 학습 목표(objective Function) = 21∥w∥2+Ci∑ξi 의 최소화
- 첫 번째 항: ∥w∥² 작게 → 마진 크게
- 두 번째 항: ξᵢ 작게 → 규칙 위반 최소화
- C: 두 목표 사이의 트레이드오프 조절 파라미터
| 구분 | 내용 |
|---|---|
| 장점 | 마진 최대화로 경계 안정적, 이상치에 상대적으로 강함, 고차원 sparse에 강함 |
| 단점 | 확률 제공 안 함, 해석력 낮음, C에 민감, 스케일링 필수 |
| 언제 쓰나 | 확률 필요 없고 분류 정확도가 중요할 때, 텍스트 분류 |
| 핵심 튜닝 | C, feature scaling, (필요 시) probability calibration |
1-3) Logistic Regression vs SVM - 공통점과 차이점
| 비교 기준 | Logistic Regression | Linear SVM |
|---|---|---|
| 출력 | 확률 | 클래스 |
| 목표 | 확률 정확도 | 경계 안정성 |
| 이상치 | 민감 | 상대적으로 강함 |
| 고차원 sparse | 보통 | 강함 |
| 공통 특징 | |
|---|---|
| 모델 형태 | 선형 score = w·x + b |
| 최적화 | convex → 학습 안정적, 재현성 좋음 |
| 정규화 | L1/L2로 복잡도 제어 |
| 피처 의존 | 피처 엔지니어링 품질이 성능 좌우 |
2) 확률 기반: Naive Bayes(Gaussian/Multinomial/Bernoulli)
: "피처들이 서로 독립"이라고 가정하고, 베이즈 정리로 클래스 확률 계산!
P(y∣x)∝P(y)i∏P(xi∣y)
- 경우
- 차원이 매우 크고, 피처가 많을 때
- 빠르게 성능 가늠하는 baseline 필요할 때
- 장점
- 매우 빠르고 데이터가 적어도 성능이 잘 나옴
- 텍스트 분류에서 의외로 강력
- 단점
- 피처 독립 가정이 깨지만 성능 한계
- 실제 확률은 잘 안 맞는 경우 많음
- 종류
- Multinomial NB: 단어 카운트, TF-IDF(텍스트 분류)
- Bernoulli NB: 0/1 피처 (단어 존재 여부)
- Gaussian NB: 연속형 피처(각 피처가 정규분포를 따른다는 가정)
3) 거리 기반: KNN
: 새 데이터가 들어오면 가장 가까운 k개 이웃의 라벨을 보고 다수결로 클래스 결정
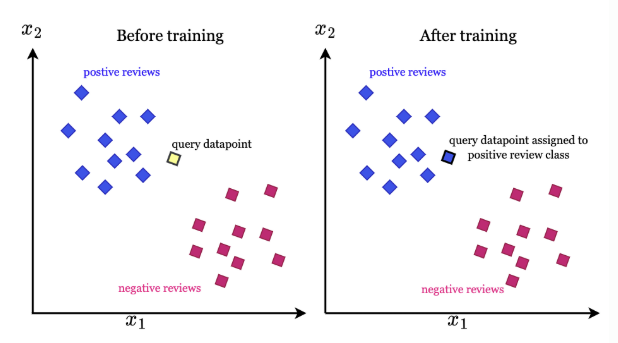
- 경우
- 데이터 구조가 단순하고 비슷한 애끼리 같은 클래스가 잘 성립할 때
- 데이터가 많지 않은 상태에서 빠르게 아이디어 검증할 때
- 장점
- 개념이 매우 직관적- 학습 과정이 거의 없고
- 비슷한 경계도 자연스럽게 표현 가능
- 단점
- 데이터가 많아질수록 예측이 매우 느림
- 고차원에서는 최근접 이웃의 의미가 사라짐으로써 성능 급락
- PCA(차원 축소)랑 같이 자주 사용
- 스케일링 비슷
4) 분포 기반: LDA(Linear Discriminant Analysis)
(비지도에서 자주 쓰는 LDA는 Latent Dirichlet Allocation이라는 모델!)
: 클래스별 데이터가 정규분포를 따른다고 가정하고, 클래스 간 분리를 최대화하는 선형 투영을 학습하는 지도학습 분류 모델
- 개별 점이 아닌 클래스 전체의 모양(평균, 분산/공분산)을 봄.
- 같은 클래스 안에서는 서로 가깝게, 다른 클래스끼리는 서로 멀게 찾기 위해 -> 클래스 간 분산/클래스 내 분산
- LDA의 전제
- 각 클래스 데이터는 정규분포
- 모든 클래스는 공분산이 동일
이를 토대로, 각 클래스의 확률밀도 계산이 가능하고 베이즈 관점에서 최적 분류기!
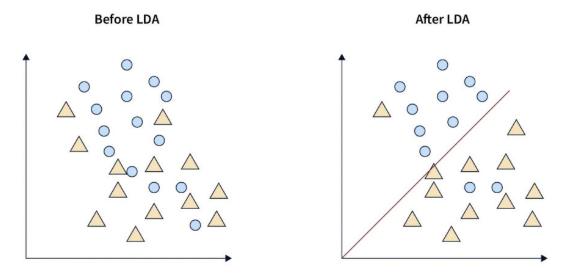
데이터 + 라벨로 클래스별 평균, 공분산 계산
최적 투영 방향 w 계산
모든 점을 그 방향으로 투영
투영된 값 기준으로 클래스 결정
5) 트리 기반: Decision Tree
: 피처 조건(if-then)을 순차적으로 나누어 데이터를 가장 잘 구분하는 규칙을 학습하는 규칙 기반 지도학습 분류 모델
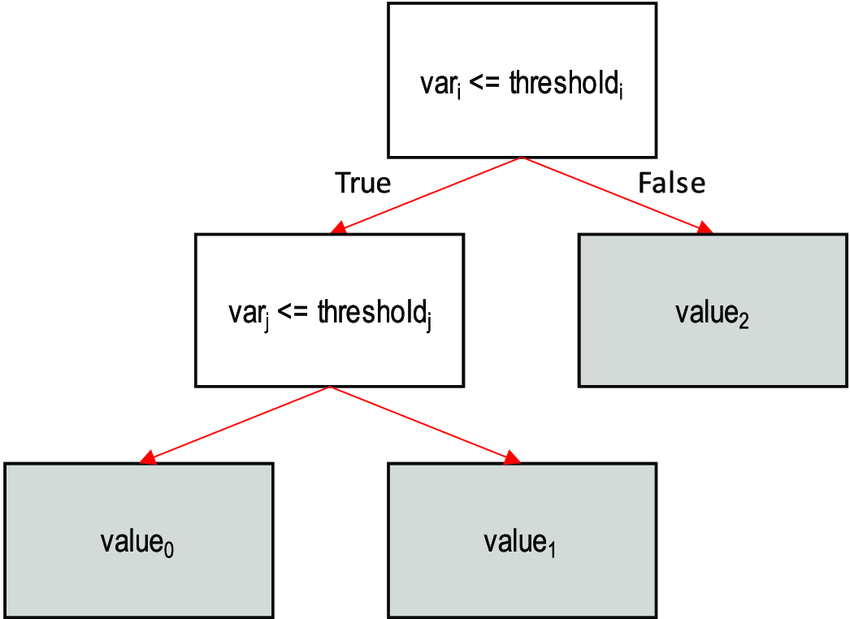
-
기본 구조
- 노드(node): 질문(조건)
- 가지(branch): 조건의 결과
- 리프(leaf): 최종 클래스
나이 < 30 ? ├─ YES → 소득 > 5000 ? │ ├─ YES → 클래스 A │ └─ NO → 클래스 B └─ NO → 클래스 C
-
불순도: 한 노드 안에서 클래스가 얼마나 섞여 있는지를 수치로 표현한 것
- Gini impurity: 무작위로 하나 뽑았을 때 다른 클래스일 확률
- Gini Gain: 분기 전 Gini - 분기 후 Gini, 값이 클수록 -> 좋은 분기 - Entropy: 불확실성/정보량, 섞여 있을수록 큼
- Information Gain: 분기 전 불순도 - 분기 후 불순도
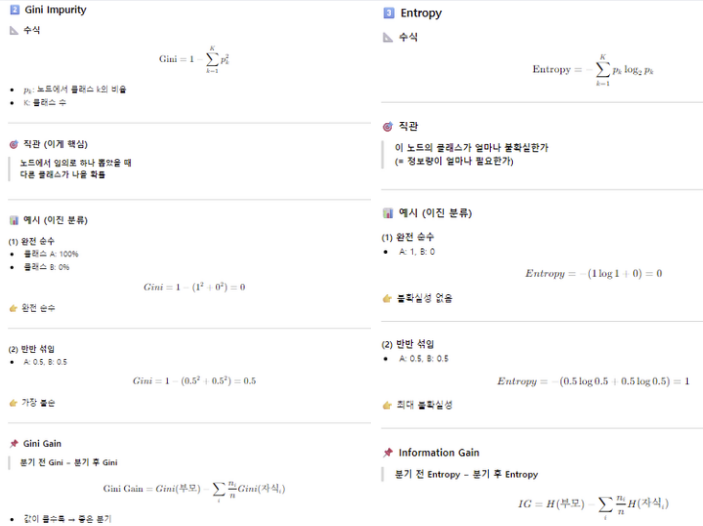
- Gini impurity: 무작위로 하나 뽑았을 때 다른 클래스일 확률
-
핵심 하이퍼파리미터
- max_depth: 트리 최대 깊이
- min_samples_split: 분기 최소 샘플 수
- min_samples_leaf: 리프 최소 샘플 수
- max_features: 분기 시 사용할 피처 수
이를 조절하면 어느 정도의 과적합 방지 가능
-
특징
- 좋은 상황
- tabular 데이터
- 피처 간 조합이 중요
- 설명 가능성 필요
- 규칙 구조 파악
- 안 좋은 상황
- 노이즈 많음
- 데이터 많음
- 성능이 최우선
- 좋은 상황
총정리
| 모델 | 핵심 기준 | 언제 특히 좋나 | 왜 이 모델을 쓰나 | 장점 | 단점 | 필수 전처리 |
|---|---|---|---|---|---|---|
| Logistic Regression | 확률 | tabular, 설명 필요 | 확률 기반 의사결정 필요 | 확률 제공, 해석 쉬움, 안정적 | 비선형 약함 | 스케일링(권장) |
| Linear SVM | 경계 | 텍스트, 고차원 sparse | 안정적인 경계 필요 | 마진 최대화, 이상치에 강함 | 확률 없음 | 스케일링 필수 |
| Naive Bayes | 확률+가정 | 텍스트 baseline | 빠른 초기 성능 확인 | 매우 빠름, 데이터 적어도 OK | 독립 가정 강함 | 거의 불필요 |
| KNN | 거리 | 소규모 실험 | 구조 탐색/직관 확인 | 비선형 가능, 개념 단순 | 느림, 차원의 저주 | 스케일링 필수 |
| LDA | 분포 | 분포 깔끔한 tabular | 통계적 최적 분리 | 이론적 깔끔함 | 가정 깨지면 붕괴 | 스케일링(권장) |
| Decision Tree | 규칙 | tabular, 관계 중요 | 피처 조합 규칙 필요 | 비선형, 해석 가능 | 과적합 심함 | 거의 불필요 |
