1. 지도학습
: 정답이 있는 데이터를 사용해 입력과 출력 사이의 관계를 학습하는 머신러닝 방법
- "무엇을 예측하느냐"에 따라 분류/회귀 등으로 나뉨
2. 분류(Classification)
- 출력값: 범주형
- 예: 정상/비정상
- 확률을 예측한 뒤 임계값을 기준으로 최종 클래스 결정
임계값(Threshold): 예측 확률을 양성/음성으로 나누는 기준
3. 회귀(Regression)
- 출력값: 연속적인 수치
- 예: 집값, 매출, 온도
- 하나의 숫자를 직접 예측하며, 예측값과 실제값의 차이를 최소화하도록 학습
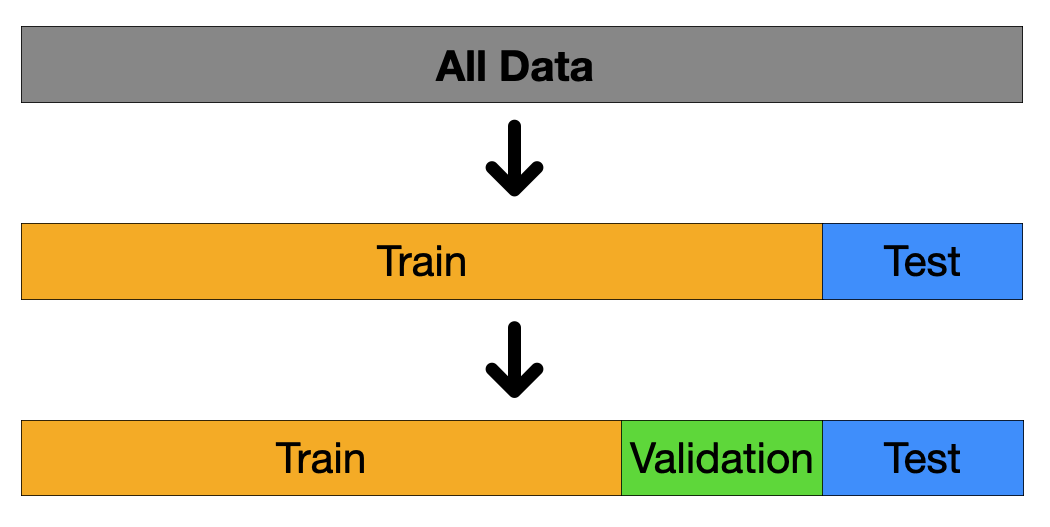
4. 데이터 분할(Data Split)
- train(훈련): 모델이 직접 학습하는 데이터
- validation(검증): 모델 선택 및 하이퍼파라미터 튜닝에 사용
- test(테스트): 최종 성능 평가용 데이터
5. 성능 평가
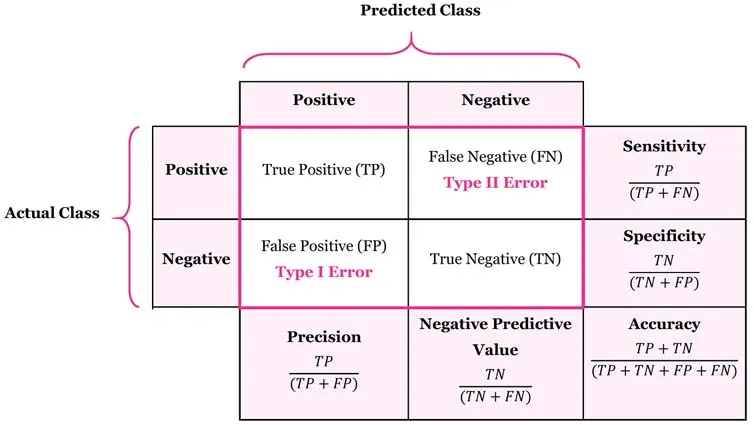
1) 혼동행렬(Confusion Matrix)
: 분류 성능 지표를 계산하기 위한 기초 구조
| 지표 | 영어 | 한국어 | 의미 |
|---|---|---|---|
| Sensitivity | TPR, Recall | 민감도(재현율) | 실제 양성 중 맞춘 비율 |
| Specificity | TNR | 특이도 | 실제 음성 중 맞춘 비율 |
| Accuracy | - | 정확도 | 전체 중 맞춘 비율 |
| Precision | PPV | 정밀도(양성 예측도) | 양성 예측 중 진짜 양성 |
| NPV | - | 음성 예측도 | 음성 예측 중 진짜 음성 |
| 상황 | TP (True Positive) | TN (True Negative) | FP (False Positive) | FN (False Negative) |
|---|---|---|---|---|
| 스팸 필터 | 스팸 메일을 스팸으로 차단 |
정상 메일을 정상적으로 전달 |
정상 메일을 스팸으로 차단 |
스팸 메일이 받은편지함으로 전달 |
| 사기 탐지 | 사기 거래를 사기로 탐지 |
정상 거래를 정상 처리 |
정상 거래를 사기로 오탐 |
사기 거래를 정상으로 통과 |
| 의료 진단 | 질병 환자를 정확히 진단 |
건강한 사람을 정상 판정 |
건강한 사람을 환자로 오진 |
환자를 정상으로 판단 |
| 추천 시스템 | 관심 있는 상품을 추천 |
관심 없는 상품을 추천하지 않음 |
관심 없는 상품을 추천 |
관심 있는 상품을 추천하지 않음 |
임계값을 조정하면 Precision과 Recall 사이의 균형이 바뀌며, 어떤 오류(FP 또는 FN)를 더 줄일지 선택할 수 있음.
2) 성과 지표
| 성과 지표 | 수식 | 문제 유형 | 주 사용처 | 언제 적합한가 |
|---|---|---|---|---|
| Accuracy | (TP + TN) / (TP + TN + FP + FN) | 분류 | 균형 데이터 | 모든 클래스 비중이 비슷할 때 |
| Balanced Accuracy | (Recall+ + Recall-) / 2 | 분류 | 불균형 데이터 | 다수 클래스 쏠림 방지 |
| Precision | TP / (TP + FP) | 분류 | 스팸, 추천 | 오탐(FP)이 치명적일 때 |
| Recall | TP / (TP + FN) | 분류 | 사기, 의료 | 미탐(FN)이 치명적일 때 |
| F1-score | 2 × (Precision × Recall) / (Precision + Recall) | 분류 | 불균형 분류 | Precision·Recall 균형 |
| F1-macro | (1 / C) × Σ F1c | 분류 | 다중 분류 | 모든 클래스 동일 중요 |
| F1-weighted | Σ (nc / N) × F1c | 분류 | 실무·대회 | 클래스 비중 반영 |
| ROC-AUC | ROC 곡선 아래 면적 | 분류 | 금융, 신용 | 임계값과 무관한 순위 성능 |
| PR-AUC | Precision–Recall 곡선 면적 | 분류 | 극불균형 | 양성 클래스가 매우 적을 때 |
| Log Loss | −Σ [ y·log(p) + (1−y)·log(1−p) ] | 분류 | 금융·신용 | 확률 예측 품질 평가 |
| Brier Score | (1/N) × Σ (y − p)² | 분류 | 리스크 모델 | 확률 신뢰도(calibration) |
| MCC | (TP·TN − FP·FN) / √((TP+FP)(TP+FN)(TN+FP)(TN+FN)) | 분류 | 극불균형 | 가장 안정적인 단일 지표 |
| MAE | (1/N) × Σ |y − ŷ| | 회귀 | 가격·수요 | 직관적 오차 해석 |
| MSE | (1/N) × Σ (y − ŷ)² | 회귀 | 연구 | 최적화·미분 용이 |
| RMSE | √MSE | 회귀 | 대회 | 큰 오차에 강한 패널티 |
| R² | 1 − (Σ (y−ŷ)² / Σ (y−ȳ)²) | 회귀 | 리포트 | 평균 예측 대비 설명력 |
| MAPE | (1/N) × Σ |(y−ŷ)/y| | 회귀 | 매출·수요 | 비율 해석이 중요할 때 |
| RMSLE | √( (1/N) × Σ (log(ŷ+1) − log(y+1))² ) | 회귀 | 성장률 | 큰 값 영향 완화 |
| NDCG@k | DCG@k / IDCG@k | 랭킹/추천 | 추천 시스템 | 상위 결과가 중요할 때 |
| MAP | (1/Q) × Σ AP | 랭킹/검색 | 검색 | 전체 랭킹 품질 |
| MRR | (1/Q) × Σ (1 / rank) | 랭킹/QA | 검색·QA | 첫 정답이 중요할 때 |
머신러닝 모델의 성능은 하나의 지표로 모두 설명할 수 없으며,
문제의 목적과 데이터 특성에 따라 중요하게 봐야 할 오류의 종류가 달라진다.
대회 환경에서는 특정 성과 지표를 극대화하는 것이 목표가 되지만,
이는 검증 데이터에 대한 오버피팅으로 이어져 실제 서비스 환경에서는 일반화 성능과 신뢰도가 떨어질 수 있다.
예를 들어 Precision이 높더라도 RMSE가 크거나 ROC-AUC가 0.5 이하라면,
모델은 의미 있는 예측을 하지 못하는 상태에 가깝다.
결국 좋은 모델이란 단일 지표의 수치가 높은 모델이 아니라,
성능, 일반화, 신뢰도를 함께 고려했을 때 문제에 적합한 모델이다.
