1. 회귀(Regression)
: 출력값이 연속형 숫자(value)인 지도학습
- 입력 x로부터 예측값 ŷ를 만드는 과정
- 집의 특성 x(면적, 역세권, 층수) -> 예측 집값 ŷ=7.3억
- 내일 날씨 특징 x(기압, 습도) -> 예측 기온 ŷ=28.4°C
- 종류
- 입력 기준
- 단변량 회귀: 입력 x가 1개
- 다변량 회귀: 입력 x가 여러 개
- 출력 개수 기준
- 단일 출력 회귀: 예측값 y가 하나
- 다중 출력 회귀: 한 번에 여러 개의 숫자 예측
- 출력 분포 기준
- 일반 연속값: y가 연속형 숫자(온도, 키, 점수)
- 카운트 데이터(Poisson Regression): y가 0개 이상 정수
- 음수가 나올 수 없고 평균이 커질수록 분산도 커짐
- λ=exp(w⋅x)
- 예) 주문 건수, 방문 수, 사고 발생 횟수
- 금액형 데이터(Tweedie): 대부분이 0인 데이터
- 발생하면 양수 연속값이고 분산이 매우 큼
- Poisson + Gamma 성질을 섞은 분포
- 예) 보험 청구 금액, 광고 클릭 후 결제 금액, 손해액
- 입력 기준
1) 손실함수 선택
- MAE(L1): |y - ŷ|
- 이상치에 덜 흔들리고 큰 오차도 선형으로 벌점
- 중앙값 쪽으로 예측을 끌어당기는 성질
- MSE(L2): (y - ŷ)²
- 큰 오차에 매우 민감(제곱 벌점)
- "평균"쪽으로 예측을 끌어당기는 성질
- RMSE: √MSE
- 단위가 원래 y 단위로 돌아와서 해석 쉬움
- Huber loss: 작은 오차는 L2처럼, 큰 오차는 L1처럼
- 평소에는 MSE의 매끈함과 이상치에는 MAE의 강인함으로 타협
큰 오차 한 번이 치명적이면 MSE/RMSE 쪽
데이터에 이상치/라벨 노이즈 많으면 MAE/Huber 쪽
2) Target 스케일/분포
- 문제 상황: 0 ~ N억(집값), long-tail(매출), 양수만 존재, 분산 커짐
- 해결: log1p 변환(y’ = log(1 + y))
- 큰 값의 영향 줄이고, "비율 오차"에 가까운 최적화가 됨
- 예측 후에는 expm1로 되돌림
- log 변환은 0/음수 처리를 설계해야 함(0이면 log1p, 음수면 다른 변환/모델링 필요)
3) 평가지표
- R²: 1 - (SSE/SST)
- 평균 예측 대비 얼마나 설명했는지
- 데이터 스케일/분포 따라 착시 있음
- MAE/RMSE
- MAPE: |(y-ŷ)/y|
- y가 0 근처면 폭발, 작은 값에 과민 -> 조심
- SMAPE: 비율형 보완
2. 단일 모델(Baseline)
1) 선형 회귀(Linear Regression)
로지스틱 회귀랑 똑같이 점수 만드는 구조 (다만, 분류처럼 sigmoid 확률로 바꾸지 않고 그 점수가 곧 예측값)
- ŷ = w·x + b
- 보통 MSE 최소화가 되게 w, b를 찾음
- 장점: 빠르고 해석 가능, baseline으로 최고
- 단점: 비선형 관계 못 잡음, 이상치에 흔들림
2) Ridge/Lasso/Elastic Net(정규화 회귀)
회귀에서는 다중공선성(피처끼리 비슷함)이 자주 터지는데 Ridge가 안정적으로 잡아줌.
- Ridge(L2): 가중치 전체를 조금씩 줄여 안정화
- Lasso(L1): 일부 가중치를 0으로 -> 피처 선택
- ElasticNet(L1+L2): 둘 섞어서 타협
피처 많고 상관 강하면 Ridge/ElasticNet이 편함
"설명 가능한 소수 피처"를 뽑고 싶으면 Lasso가 유용
3) SVR(회귀 버전 SVM)
: 예측선 주변에 '허용 오차 폭 ε’(엡실론)을 두고, 그 안의 오차는 "0으로 치고" 무시하면서 모델을 최대한 단순하게(너무 요동치지 않게) 만드는 회귀
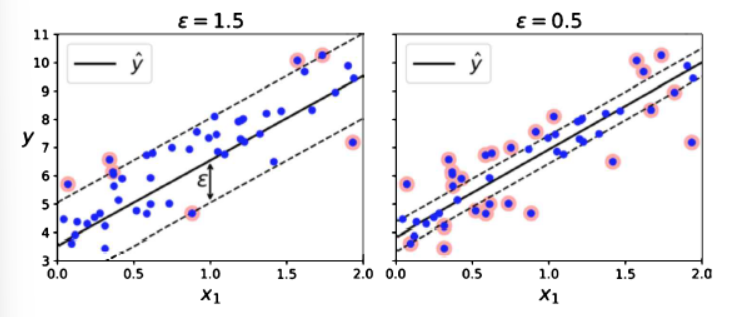
- ε 오차 - ε-insensitive loss
- 회귀에서 보통 오차가 0이 아니면 무조건 벌점인데 작은 오차까지 다 맞추려다 모델이 흔들릴 수 있으니, 엡실론 안쪽 오차는 벌점 0으로 함.
- 예시 (ε=2)
- 정답 100, 예측 101 -> 오차 1 (ε 안) -> 벌점 0
- 정답 100, 예측 98 -> 오차 2 (ε 안) -> 벌점 0
- 정답 100, 예측 95 -> 오차 5 (ε 밖) -> 벌점 발생 (5-2=3만큼만)
- ε-튜브: 예측함수 ŷ(x) 주위로 위아래 ε만큼 띠(튜브)를 만든다고 생각하면 됨.
- 튜브 안: "맞춘 걸로 치자"
- 튜브 밖: 벗어난 거리만큼만 벌점
- 핵심 파라미터
- ε: 허용 오차 폭
- 커지면: 더 많이 무시(관대) -> 매끈하지만 디테일 놓침(편차 큼)
- 작아지면: 더 엄격 -> 디테일 맞추려다 흔들릴 수 있음(분산 큼)
- C: 튜브 밖 점에 대한 벌점 세기
- 커지면: "튀어나온 점 무조건 맞춰!" -> 과적합 위험 증가
- 작아지면: "좀 틀려도 돼" -> 더 부드러워짐. 과소적합 위험 증가
- ε: 허용 오차 폭
종류
| 구분 | Linear SVR | Kernel SVR |
|---|---|---|
| 관계 표현 | 선형 | 비선형 가능 |
| 계산량 | 비교적 빠름 | 데이터 커질수록 급격히 증가 |
| 커널 행렬 | 사용 안 함 | N×N 계산 |
| 확장성 | 큰 데이터에도 비교적 가능 | 대규모 데이터 부적합 |
| 튜닝 난이도 | C, ε 중심 | C, ε, gamma 등 더 복잡 |
| 추천 상황 | 피처 많고 선형 근사 가능할 때 | 데이터 적고 복잡한 곡선 필요할 때 |
SVR 쓰는 상황
| 구분 | 좋은 상황 | 안 좋은 상황 |
|---|---|---|
| 데이터 크기 | 데이터가 아주 크지 않음 (수만~수십만 이하) | 데이터가 매우 큼 (특히 커널 SVR) |
| 데이터 특성 | 노이즈가 있고 작은 오차는 중요하지 않음 | 작은 오차까지 정밀하게 맞춰야 함 |
| 관계 구조 | 비선형 구조가 있지만 트리 말고 다른 해법도 보고 싶을 때 | 고차원 sparse 데이터에서 커널 사용 시 비효율 |
| 모델 특성 | 매끈하고 안정적인 함수 형태를 원할 때 | 튜닝(ε, C, gamma)이 까다로워 빠른 실험이 어려울 때 |
| 계산 자원 | 중소 규모 실험, 연구용 | 대규모 실시간 시스템 |
필수 전처리
| 항목 | 설명 |
|---|---|
| 스케일링 | 필수에 가깝다. SVR은 내적/거리 기반이므로 피처 스케일에 매우 민감. StandardScaler/MinMaxScaler 권장 |
| 이상치 확인 | ε-튜브 밖 점에 벌점이 가므로 극단값이 많으면 C 조정 필요 |
| 커널 선택 | Linear → 단순/빠름, RBF → 비선형/느림, gamma 조정 필수 |
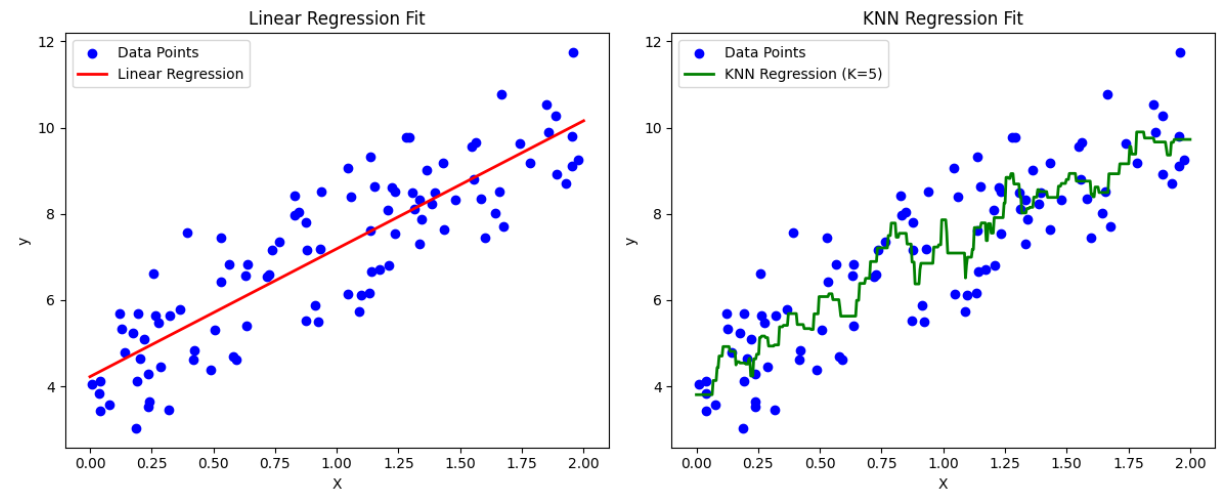
4) KNN Regression
- 분류가 다수결이면, 회귀는 주변 k개 이웃의 y를 평균(가중평균)해서 예측
- 가중평균: 거리가 가까운 이웃에 더 큰 가중치(거리 역수 등)
- 데이터가 많아질수록 예측 느림
- 고차원에서 급격히 망가짐
- 스케일링 중요
- feature별 단위 다르면 StandardScaler 써서 표준화
- feature별 단위 다르면 StandardScaler 써서 표준화
5) Decision Tree Regressor
- 분류 트리는 지니/엔트로피로 "라벨 섞임" 최소화였고, 회귀 트리는 보통 분기 후 MSE 감소(분산 감소)가 최대가 되게 자름
- 리프의 예측값: 그 리프에 들어온 y들의 평균(MSE 기준)
- 트리 회귀는 특히 계단형 예측이 나옴(구간마다 일정한 값)
| 문제 | 원인 | 해결책 |
|---|---|---|
| 과적합 | 노이즈까지 완벽 외움 (훈련 MSE=0) | max_depth: 깊이 제한 |
| 각 샘플마다 리프 생성 | min_samples_leaf: 리프당 최소 샘플 수 | |
| 테스트셋 성능 급락 | 앙상블 (Random Forest 등) |
