1. 앙상블(회귀)
회귀에서는 출력이 숫자이기 때문에 모델 결합 방식이 "평균"이라는 점!
앙상블(회귀)
├─ Bagging 계열 → 분산(Variance) 감소
└─ Boosting 계열 → 편향(Bias) 감소"분류 vs 회귀"의 결합 방식
결합 규칙: 다수결 vs 평균
- 분류: 결과가 클래스 -> 여러 모델의 결과를 투표(다수결)로 합침.
- 회귀: 결과가 숫자 -> 여러 모델의 예측값을 평균(또는 중앙값)으로 합침.
특히, 회귀는 조금씩 틀린 걸 평균 내면 잡음이 줄고 예측이 매끈해지는 효과(분산 감소)가 눈에 보이게 큼.
2. Bagging
: Bootstrap(복원추출)로 데이터셋을 여러 개 만들고 각 데이터셋에 모델을 학습시킨 뒤 예측을 합치는 방법
- 회귀에서는 평균 또는 중앙값 사용
- 분산이 줄어드는 이유
- 불안정한 모델(단일 Decision Tree)는 훈련 데이터가 조금만 바뀌어도 경계/규칙이 크게 바뀜.
- 서로 다른 표본으로 학습한 트리들을 여러 개 만들고 마지막에 평균내서 각 트리의 '우연한 실수'가 상쇄되게 만듦.
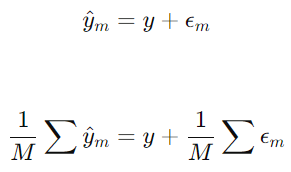
- 모델들 오차가 서로 덜 비슷할수록 좋음 = 다양성
1) Bagging Regressor
- 원본 데이터에서 복원 추출(bootstrap)로 여러 데이터셋 생성
- 같은 모델을 각각 학습
- 예측을 평균으로 결합
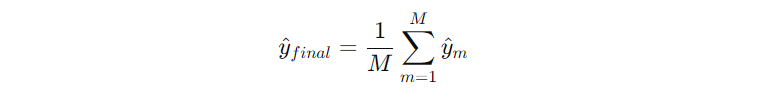
- base estimator를 자유롭게 선택 가능
- 병렬 학습 가능
- Bias는 거의 줄이지 못함
- Variance 감소가 핵심 목적
2) RandomForest
= Bagging + Feature Randomness
: 노드마다 일부 피처만 랜덤으로 후보에 올려서 트리들이 서로 다르게 자라도록 강제로 다양성 생성
- 결과: 트리들 상관관계 낮아짐
- 평균 효과 증가
- 분산 감소 효과 증가
3) Extra Trees
= RandomForest + Split Randomness
RandomForest는 분기 기준값은 최적을 찾지만, ExtraTrees는 분기 기준값도 랜덤으로 뽑음.
- 트리 다양성 더 증가
- 평균 효과 더 증가
- 대신 너무 랜덤이면 bias 증가 위험
3. Boosting
: 이전 모델이 못 맞춘 부분을 다음 모델이 집요하게 보정하면서 순차적으로 쌓는 방식
- Bagging이 병렬 평균이면, Boosting은 순차 보정임!
- 회귀에서 Boosting의 직관성 : 잔차(residual)
1. 첫 모델 예측: y^1- 잔차: r1=y−y^1
- 다음 모델은 r1을 맞추도록 학습
- 계속 반복
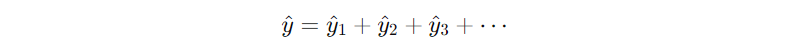
분류는 y가 0/1 같은 범주라서
- "잔차 = y - ŷ”를 그대로 쓰기엔 구조가 맞지 않는 경우가 많고
- 대신 손실함수의 gradient(기울기)를 다음 모델이 학습한다는 관점이 더 정확함.
회귀: 숫자 오차가 남기 때문에 잔차를 직관적으로 보정
분류: 맞/틀 문제라서 확률 공간에서 손실을 줄이는 방향을 보정
1) GBDT(Gradient Boosting Decision Tree)
: 손실을 줄이는 방향(gradient)을 다음 트리가 근사하도록 얕은 트리를 하나씩 순차적으로 더해가는 기본 부스팅 모델
- 작동 원리
- 초기값: y의 평균으로 시작
- 현재 예측의 오차(또는 gradient) 계산
- 다음 트리가 그 오차를 맞추도록 학습
- 기존 예측에 더함
- 반복
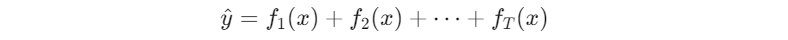
- 강한 이유
- 비선형 관계 자동 학습
- 피처 간 상호작용 자동 발견
- 스케일링 거의 불필요
- tabular 데이터에서 매우 강력
- 핵심 파라미터
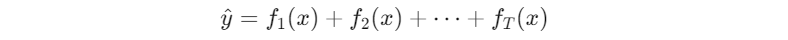
- 한계
- 순차 학습 -> 느림
- 과적합 쉬움
- 대규모 데이터에서 비효율적일 수 있음.
2) XGBoost
:GBDT에 정규화와 안정적 최적화를 추가한 모델
- GBDT와의 차이점
- 목적함수에 트리 복잡도 벌점 추가
- 리프 수 벌점
- 리프 값 크기 벌점 -> 과적합 구조적으로 억제
- 2차 미분(gradient+hessian) 사용
- 분기 판단이 더 안정적
- 수렴이 빠르고 정확
- Pruning(가지치기) 전략
- 손실 감소가 작으면 분기 안 함
- 시스템 최적화
- 병렬 처리
- 결측치 자동 처리
- 희소 데이터 대응
- 목적함수에 트리 복잡도 벌점 추가
- 대표 파라미터
- eta(learning_rate)
- max_depth
- min_child_weight
- subsample
- colsample_bytree
- gamma(분기 최소 이득)
- reg_lambda/reg_alpha
3) LightGBM
: 대규모 데이터에서 빠르게 학습하도록 설계된 고속 GBDT 구현체
- Histogram 기반 분기
- 연속값을 bin으로 압축
- 계산량 대폭 감소
- Leaf-wise 성장
- 손실을 가장 많이 줄일 수 있는 리프부터 확장
- level-wise보다 수렴 빠름
- 특징
- 매우 빠르고 대용량에 강하며, 메모리 효율적
- leaf-wise 특성상 과적합 빠름
- 작은 데이터에서는 불안정할 수 있음
| 파라미터 | 의미 |
| ---------------- | ---------------- |
| num_leaves | 최대 리프 수 (표현력 핵심) |
| max_depth | 깊이 제한 |
| min_data_in_leaf | 과적합 방지 |
| feature_fraction | 피처 샘플링 |
| bagging_fraction | 데이터 샘플링 |
4) CatBoost
: 범주형 피처 처리를 내부에서 안정적으로 수행하는 GBDT 구현체
- 범주형 인코딩을 모델 내부에서 처리
- 타깃 누수 완화 전략 포함
- 기본 설정으로도 강한 성능
- 범주형 많은 데이터에 강하며 전처리 부담이 감소되고 안정적인 학습
- 데이터/환경에 따라 속도 차이가 나며, 튜닝 옵션 구조가 다른 계열과 다름
정리
| 모델 | 핵심 목적 | 강점 | 주의점 |
|---|---|---|---|
| GBDT | 기본 부스팅 | 개념 단순 | 느릴 수 있음 |
| XGBoost | 안정+정규화 | 성능/안정 밸런스 | 파라미터 많음 |
| LightGBM | 속도+대규모 | 빠름/대용량 | leaf-wise 과적합 |
| CatBoost | 범주형+누수 완화 | 범주형 강함 | 상황별 속도 |
총정리
| 항목 | Bagging | Boosting |
|---|---|---|
| 핵심 목표 | 분산 감소(안정화) | 편향 감소(정교화) |
| 방식 | 병렬로 여러 모델 → 평균/투표 | 순차로 계속 보정 |
| 회귀 결합 | 평균/중앙값 | 잔차(gradient) 누적 |
| 분류 결합 | 다수결/확률 평균 | 확률 공간에서 gradient 보정 |
| 과적합 | 비교적 덜함 | 더 쉬움(파라미터 중요) |
| 대표 | RF, ExtraTrees | GBDT, XGB, LGBM, Cat |
