Introduction
- 기존의 LLM 기반 Multivariate Time Series Forecasting(MTSF) 방법은 일반적으로 텍스트 입력 토큰과 시간 입력 토큰 간의 분포 불일치를 무시한 채 LLM을 미세 조정하기 때문에 파운데이션 모델의 잠재 성능을 충분히 발휘하지 못함
- 텍스트 입력 토큰과 시간 입력 토큰 간의 분포 불일치를 고려하기 위한 크로스 모달 LLM 미세 조정 프레임워크 제안
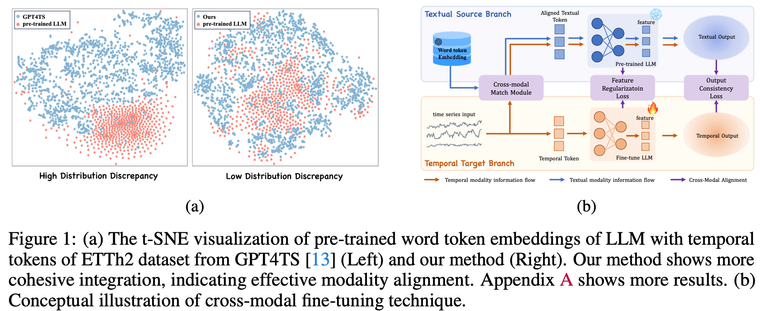
Methodology
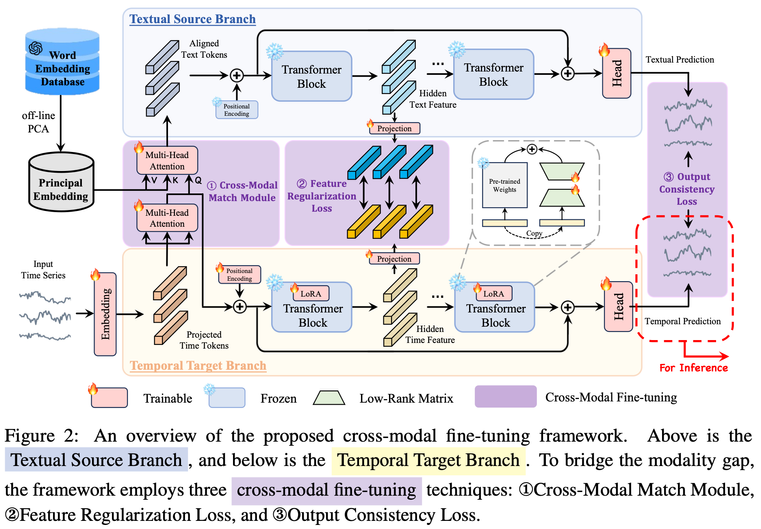
제안하는 프레임워크는 Time-series 정보를 처리하는 Temporal target Branch와 Aligned Text Token을 사용하여 Pre-trained LLM에서 정보를 추출하고 조정하는 Textual Source Branch로 구성
Cross-Modal Match Module
- 입력 Time-series Embedding: →
- 임베딩된 Time-series에 대하여 Multi-head Self Attension 수행: $X_{time} = \textnormal{MHSA}
- 베이스라인 LLM의 Vocab을 PCA를 통해 차원 축소하여 Principal Embedding 도출:
a. Vocab 에서 는 Vocab의 크기인데, 이는 GPT-2의 경우 50257로 매우 큼 → 의미적으로 유사한 단어들끼리 동의어 클러스터를 만드는 개념으로 PCA를 통해 차원 축소 - 을 key와 value로, 을 query로 한 Multi-head Corss Attention을 수행하여 timporal token과 principal word embedding이 align된 도출
→ Time-series와 텍스트 간의 입력 분포 간극을 효율적으로 정렬
Feature Regularization Loss
- Textual Source Branch와 Temporal Target Branch의 l번째 트랜스포머 블록의 출력 과 을, 각각 훈련 가능한 레이어를 통해 textual modality와 temporal modality가 서로 공유되는 표현 공간에 투영
- L1 손실과 같은 유사도 함수를 통해 각 모달리티 간 차이 도출
- 를 통해 중간 레이어 위치별로 손실 규모 조절 후 총합
→ 가중치가 고정된 Textual Source Branch의 LLM 출력 값이 Temporal Target Branch의 Fine-tuning 시 참조될 수 있도록 하여 훈련 가이딩
Output Consistency Loss
L1 손실과 같은 유사도 함수를 통해 Textual Source Branch의 출력 와 Temporal Target Branch의 출력 간의 차이 도출
→ Time-series modality와 text modality 간의 출력 표현 불일치를 해소하고 맥락의 일관성 보장
Parameter Efficient Training
- Temporal Target Branch의 Pre-trained LLM 미세 조정은 LoRA를 통해 수행
- 훈련 과정에서의 손실 함수는 으로 정의
- Feature Regulaization Loss와 Output Consistency Loss의 사용 유무에 따른 성능 비교를 보면 모든 손실 함수를 통합한 경우가 가장 우수했던 것으로 나타남
Result
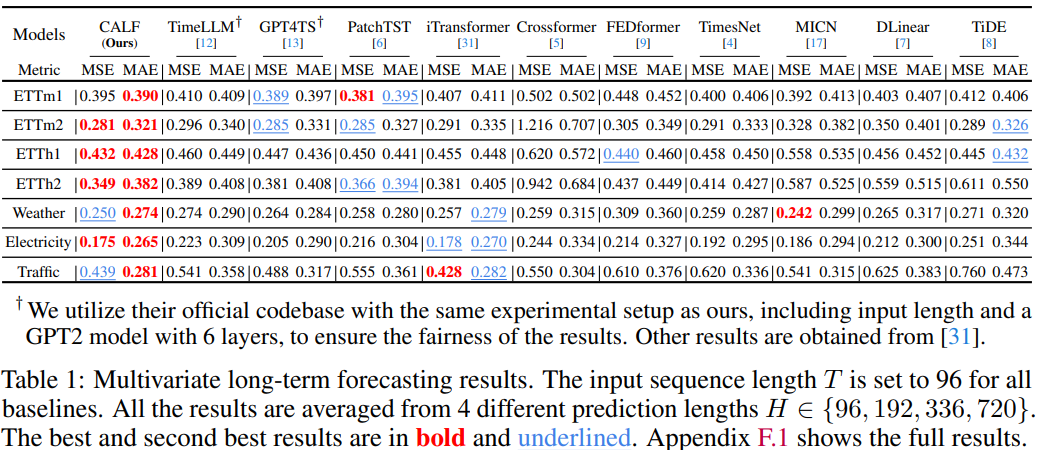
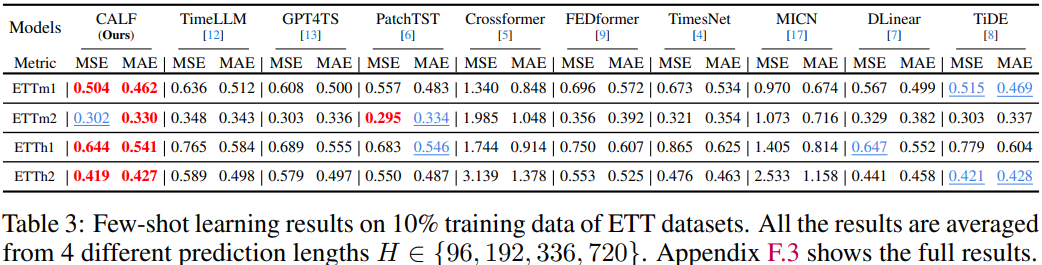
- CALF는 Problem Statement를 공유하고 유사한 방법론을 제안하였던 Time-LLM에 비해서도 모든 데이터셋에서 더 나은 성능을 보여준다고 주장하지만 Time-LLM 논문의 Result 문단을 살펴보면 오히려 Time-LLM이 정량적으로 더 우수한 것으로 나타나므로 어느 방법론의 우월을 판단하기 어려움
- 단, Few-shot 및 Zero-shot은 Time-LLM이 논문에서 제시한 Result보다 더 개선된 성능을 보이는 것으로 나타남
- Feature Regularization Loss와 Output Consistency Loss를 제외하면 CALF와 Time-LLM의 주요 차이는 크게 2가지로 요약할 수 있음
- Channel-mix (CALF) vs Channel-indepenant (Time-LLM)
- 프롬프트 활용 안함 (CALF) vs 프롬프트 활용 (Time-LLM)
- CALF가 LLM의 단어 토큰 임베딩 분포와 Time-series 분포를 맞추어 주는 것은 LLM에 내재된 잠재 지식을 활용하는 데 유의미하지만, LLM의 의미 추론 성능을 활용하는 데는 프롬프트를 통한 지시가 더 효과적이기에 이러한 결과적 차이가 나타난 것을 추정
