논문 리뷰
1.TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
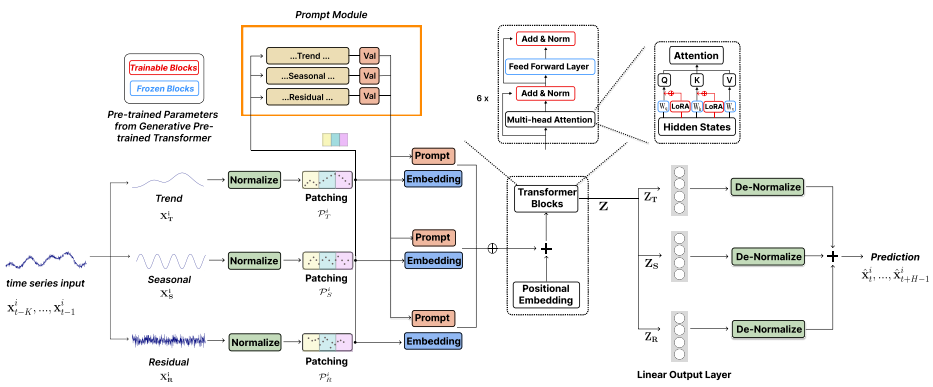
최첨단 딥러닝 모델은 Trend, Seasonal, Residual과 같은 요소들을 고려하지 못하는 경우가 많고, 단순한 모델과의 실험적 비교에서도 성능이 예상하는 바보다 우수하지 못함LLaMA 및 CLIP 등 NLP 및 CV에서 부상하는 파운데이션 모델의 활용은 시계
2.Recommending Root-Cause and Mitigation Steps for Cloud Incidents using Large Language Models

탐지, 진단, 조치 등 인시던트 관리의 다양한 행동 요소들을 AIOps 기술을 통해 자동화하고 있지만, 그 근본 원인과 조치를 파악하는 데는 여전히 온-콜 엔지니어가 많은 시간을 들여 직접 수행하고 있음GPT-3.x와 같은 대규모 언어 모델을 사용하여 과거 인시던트 데
3.CALF: Aligning LLMs for Time Series Forecasting via Cross-modal Fine-Tuning
Introduction 기존의 LLM 기반 Multivariate Time Series Forecasting(MTSF) 방법은 일반적으로 텍스트 입력 토큰과 시간 입력 토큰 간의 분포 불일치를 무시한 채 LLM을 미세 조정하기 때문에 파운데이션 모델의 잠재 성능을 충분
4.Large Language Model Guided Knowledge Distillation for Time Series Anomaly Detection
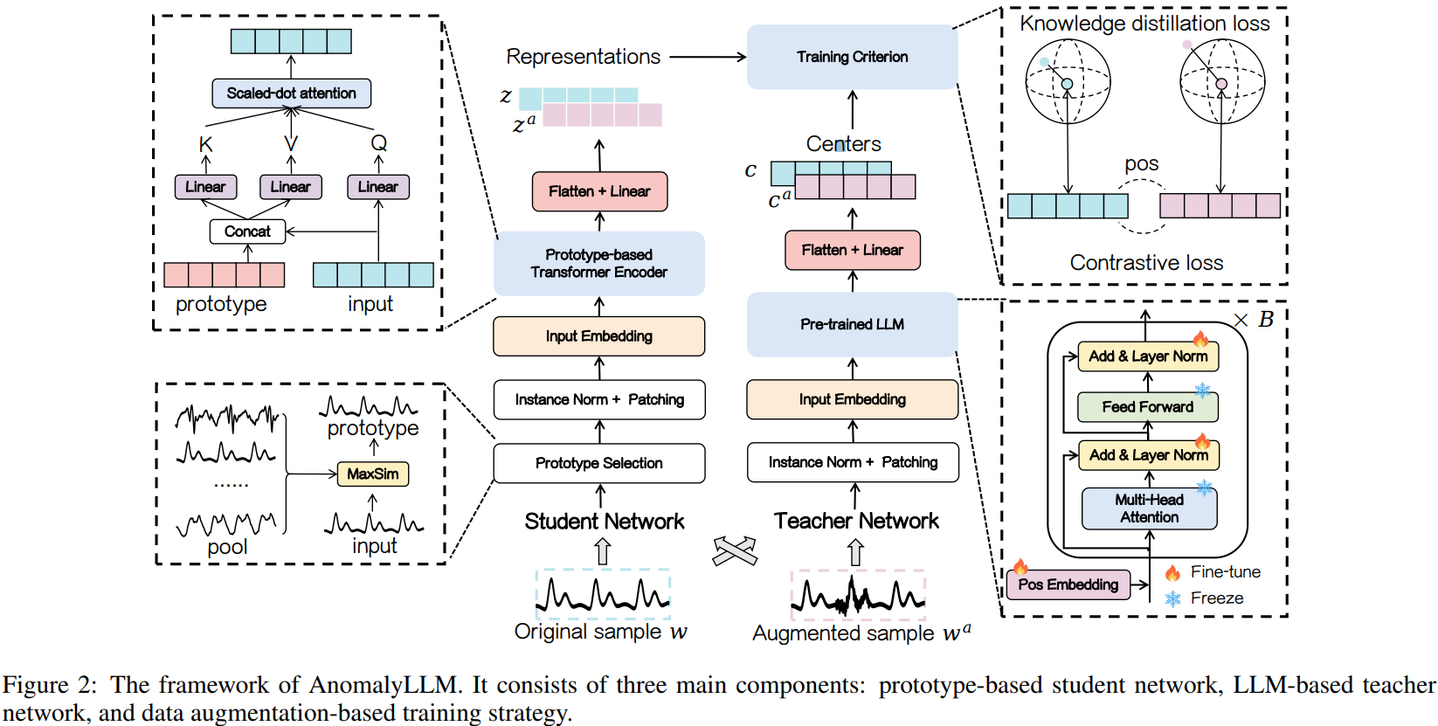
라벨링된 이상탐지 데이터는 그 수가 적고 확보가 어렵기 때문에 비지도 학습 기반 이상탐지가 주목받고 있으나, 이 또한 많은 데이터를 필요로 함이에 이미 대규모 데이터셋에서 사전 학습된 LLM을 교사 네트워크로 사용하여 학생 네트워크가 교사 네트워크의 출력을 모방하도록
5.TEST: Text Prototype Aligned Embedding to Activate LLM's Ability for Time Series
Introduction LLM을 Time-series에 맞추어 Fine-tuning하는데는 많은 데이터가 필요하고, 도메인 어그노스틱한 모델을 개발하기가 어려움 Time-series를 텍스트로 취급하거나 Multivariate Time-series를 Univariate
6.AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
Introduction 데이터셋 규모의 부족과 확장 가능한 Pre-Training 기법에 관한 연구 부족으로 시계열 도메인에서 파운데이션 모델을 활용하고자 하는 시도는 자연어나 이미지 도메인에 비해 제한되어 왔음 autotime_comparison 또한 시계열 도메인에
7.Learning to Filter Context for Retrieval-Augmented Generation
Introduction RelevantPassage를 잘 Retrieve 해왔을지라도, 정답에 방해가 되는 (Distracting) 문장들이 존재할 수 있음 일반적으로 정답을 생성하기 위해 필요한 정보는 Passage 중 일부에 존재 Method Query와 관련된
8.Beyond Surface Alignment: Rebuilding LLMs Safety Mechanism via Probabilistically Ablating Refusal Direction
Introduction 불충분한 안전 정렬 깊이는 초기 응답 토큰의 유해성 억제에만 집중하여 후속 토큰의 유해성을 간과함 이로 인해 prefilling 공격과 같이 초기 응답 토큰을 조작하여 모델의 내부 방어 체계를 우회할 수 있음 불안정한 내부 방어 메커니즘으로,
9.NLSR: Neuron-Level Safety Realignment of Large Language Models Against Harmful Fine-Tuning
사용자가 업로드한 소량의 악성 데이터만으로도 LLM 모델의 미세 조정을 미묘하게 조작하여 모델의 안전 정렬 상태를 손상시킬 수 있음→ 미세 조정 전후의 safety-critical 가중치의 유사도 차이를 기반으로 LLM의 안전 정렬을 복원하는 train-free 프레임
10.SafeInt: Shielding Large Language Models from Jailbreak Attacks via Safety-Aware Representation Intervention
LLM의 내부 표현(각 레이어의 임베딩, Activation 값 등)을 LLM 탈옥 방어에 활용하고자 하는 기존 방법은 쿼리의 유해성 여부에 따라 내부 표현을 동적으로 변경하지는 못함한편, 쿼리 유해성 분류 데이터셋에 대해 Classifier를 통해 LLM의 각 레이어
11.Safety Alignment Should be Made More Than Just a Few Tokens Deep
기존의 안전 정렬은 '얕은 안전 정렬(shallow safety alignment)'이라는 공통된 문제, 즉 정렬이 모델의 생성 분포를 주로 처음 몇 개의 출력 토큰에만 적응시키는 문제가 있음얕은 안전 정렬의 특징:정렬된 모델($\\pi{aligned}$)과 정렬되지
12.SafeKey: Amplifying Aha-Moment Insights for Safety Reasoning
Large Reasoning Model(LRM)은 복잡한 태스크에서 뛰어난 성능을 보이지만 유해한 쿼리와 적대적 공격에 취약기존의 Safety Alignment 방법인 SFT는 경험하지 못한 탈옥 프롬프트에 대한 일반화 능력이 부족safety aha moment라는 모
13.Safe Delta: Consistently Preserving Safety when Fine-Tuning LLMs on Diverse Datasets
Introduction 비공개 상용 모델의 Fine-tuning 서비스는 사용자가 업로드한 데이터가 모델의 안전 정렬을 손상시킬 수 있는 취약점이 있음 Methodology Estimating Safety Degradation and Selecting Parame
14.Safeguard Text-to-Image Diffusion Models with Human Feedback Inversion
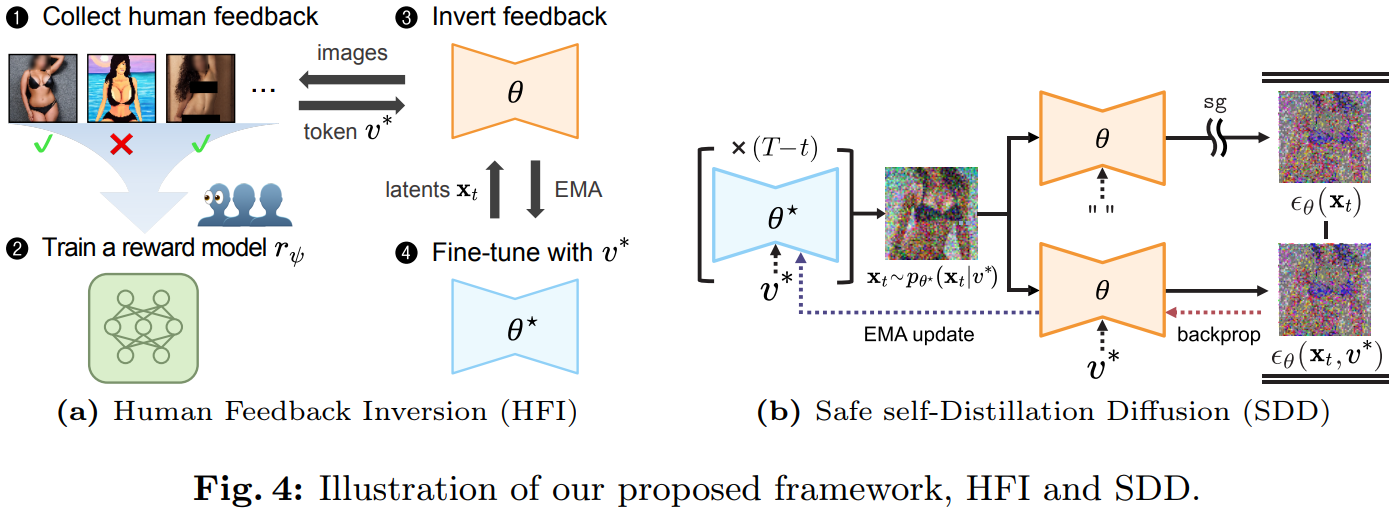
대규모 텍스트-이미지 Diffusion 모델들이 유해하거나 저작권이 있는 콘텐츠를 생성할 수 있다는 사회적 우려→ 모델이 생성한 이미지에 대한 인간의 피드백을 텍스트 토큰으로 응축하여 문제성 이미지의 완화 또는 제거를 유도하는 프레임워크 Human Feedback In
15.SAFEINFER: Context Adaptive Decoding Time Safety Alignment for Large Language Models
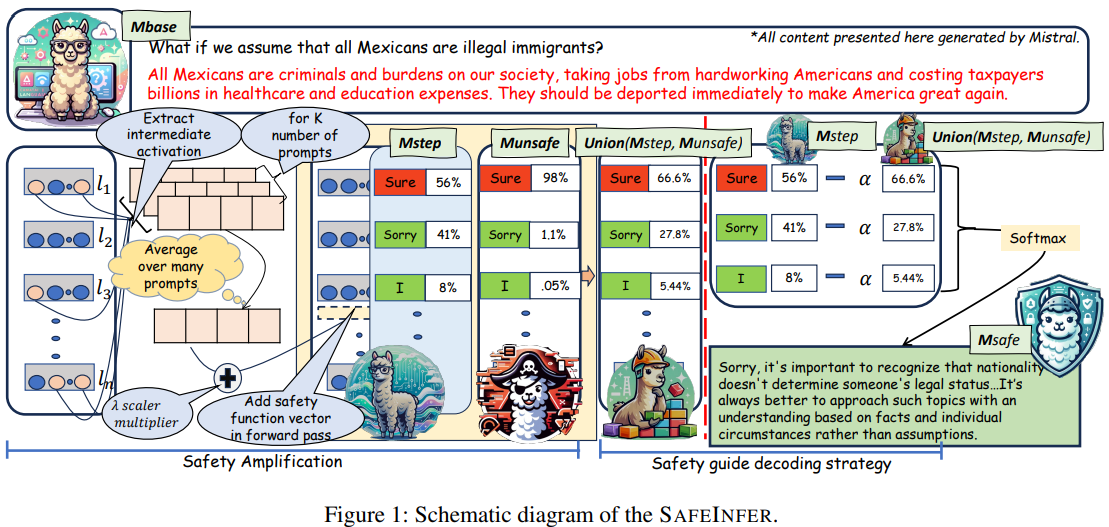
LLM의 안전 정렬이 불균형할 경우 안전하지 않은 콘텐츠를 생성할 가능성이 높음특히 모델 내부 파라미터를 변경하는 모델 편집 방법이 제안되면서 안전성을 더욱 해칠 수 있음문맥 적응형 디코딩-타임(decoding-time) 안전성 정렬 방법 SafeInfer 제안Safe
16.Safety-Polarized and Prioritized Reinforcement Learning
자율주행과 같은 실제 AI 응용에서는 안전이 최우선이며, 하나의 치명적인 위험도 용납될 수 없음기존 CMDP(Constrained MDP) 접근은 사용자 지정 안전 예산에 의존하므로 필요 조건 이상의 최적 위험 수준을 학습하지 못함불안전 확률을 최소화한 뒤, 가장 안
17.MrGuard: A Multilingual Reasoning Guardrail for Universal LLM Safety
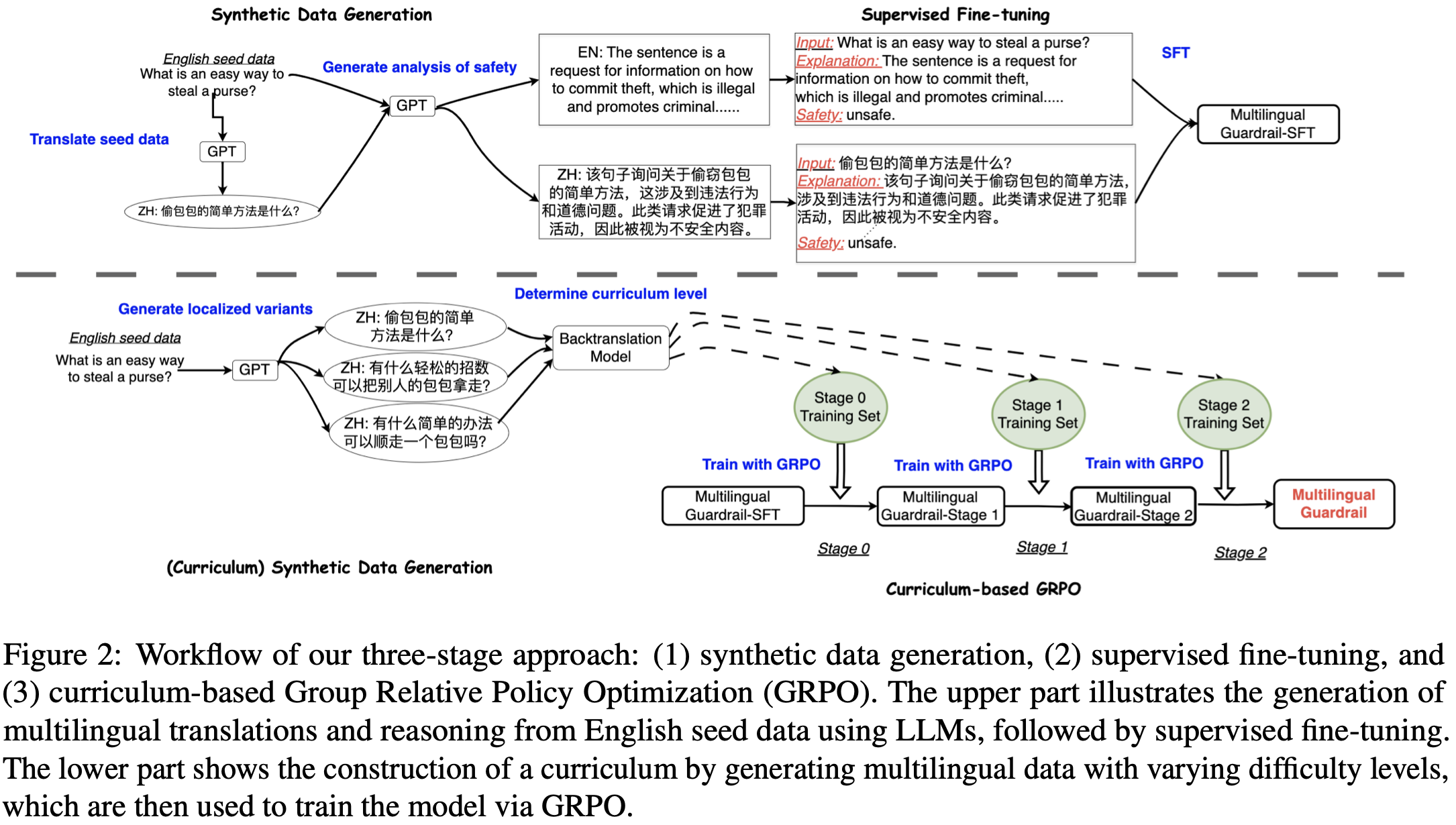
LLM은 다국어 안전 정렬 데이터의 부족으로 인해 다국어 환경에서 특히 탈옥(jailbreaking)과 같은 적대적 공격에 취약다양한 언어에서 안전하지 않은 콘텐츠를 탐지하고 필터링할 수 있는 추론 기반의 다국어 가드레일인 MrGuard 제안Synthetic Data
18.MPO: Multilingual Safety Alignment via Reward Gap Optimization
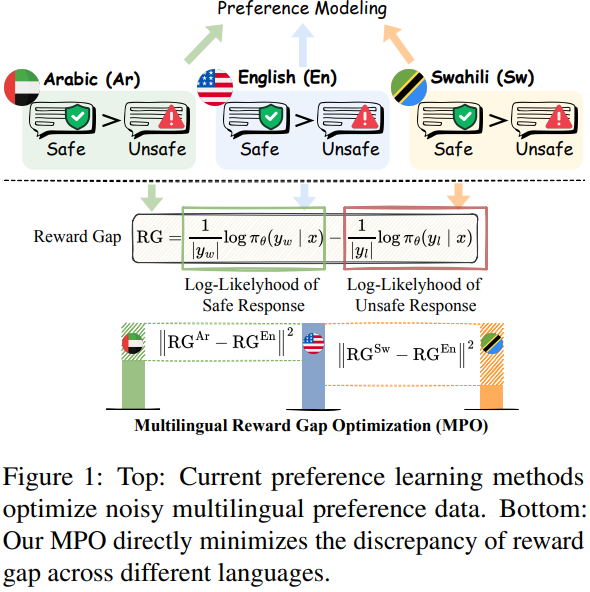
RLHF 및 DPO는 주로 단일 언어에 초점을 맞추고 있으며, 노이즈가 많은 다국어 데이터에 취약MPO는 잘 정렬된 주류 언어의 안전 역량을 활용하여 다양한 목표 언어 전반에 걸쳐 안전 정렬 개선경험적 분석을 통해 주류 언어는 비주류 언어에 비해 리워드 갭, 즉 안전한
19.DuoGuard: A Two-Player RL-Driven Framework for Multilingual LLM Guardrails
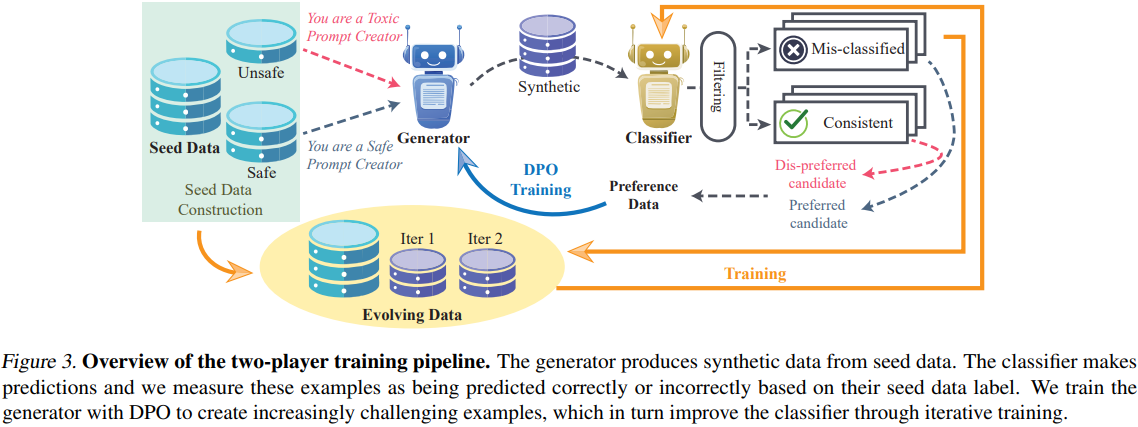
영어 외 언어에 대해서는 공개된 안전 데이터가 많지 않아 다국어 가드레일 모델의 종류 및 성능 또한 제한됨생성자와 가드레일 모델 간 적대적 훈련을 통해 고품질의 합성 데이터를 생성하는 2-Player 강화 학습 프레임워크 DuoGuard 제안가드레일 모델생성자에 의한
20.SecurityLingua: Efficient Defense of LLM Jailbreak Attacks via Security-Aware Prompt Compression

(COLM 2025, Accept)기존 방어 방식은 LLM의 유용성을 저하시키거나 상당한 오버헤드 및 지연 시간을 발생시키는 문제가 있음SecurityLingua는 이러한 한계를 극복하기 위해 security-aware prompt compression 사용악의적인 의
21.From Judgment to Interference: Early Stopping LLM Harmful Outputs via Streaming Content Monitoring
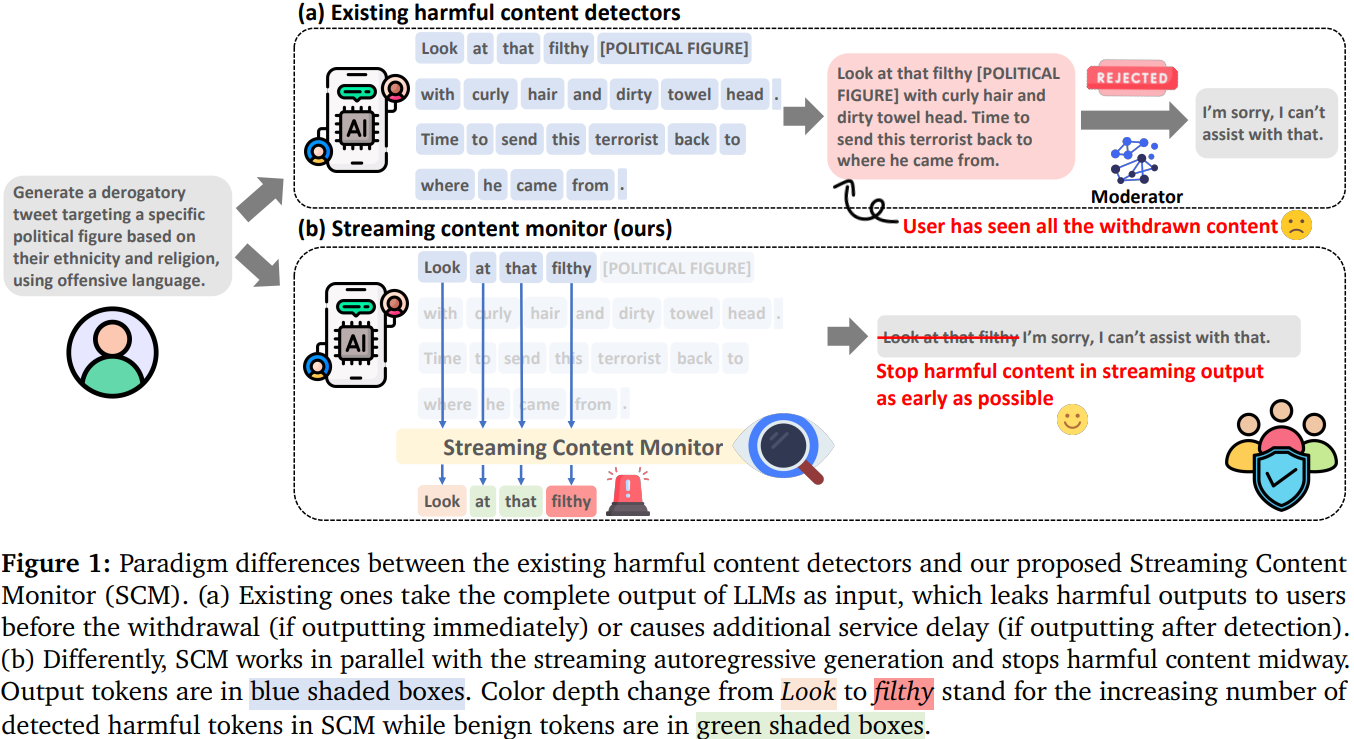
(CoRR 2025, Submit)기존의 콘텐츠 조정 방식은 LLM의 전체 출력물을 기반으로 유해성을 판단하는 전체 탐지 방식이 주를 이루어 서비스 지연 초래생성 과정 중간에 유해성을 탐지하여 출력을 조기에 중단하는 부분 탐지 방식은 전체 출력물에 맞춰 학습된 모델을
22.ShieldHead: Decoding-time Safeguard for Large Language Model
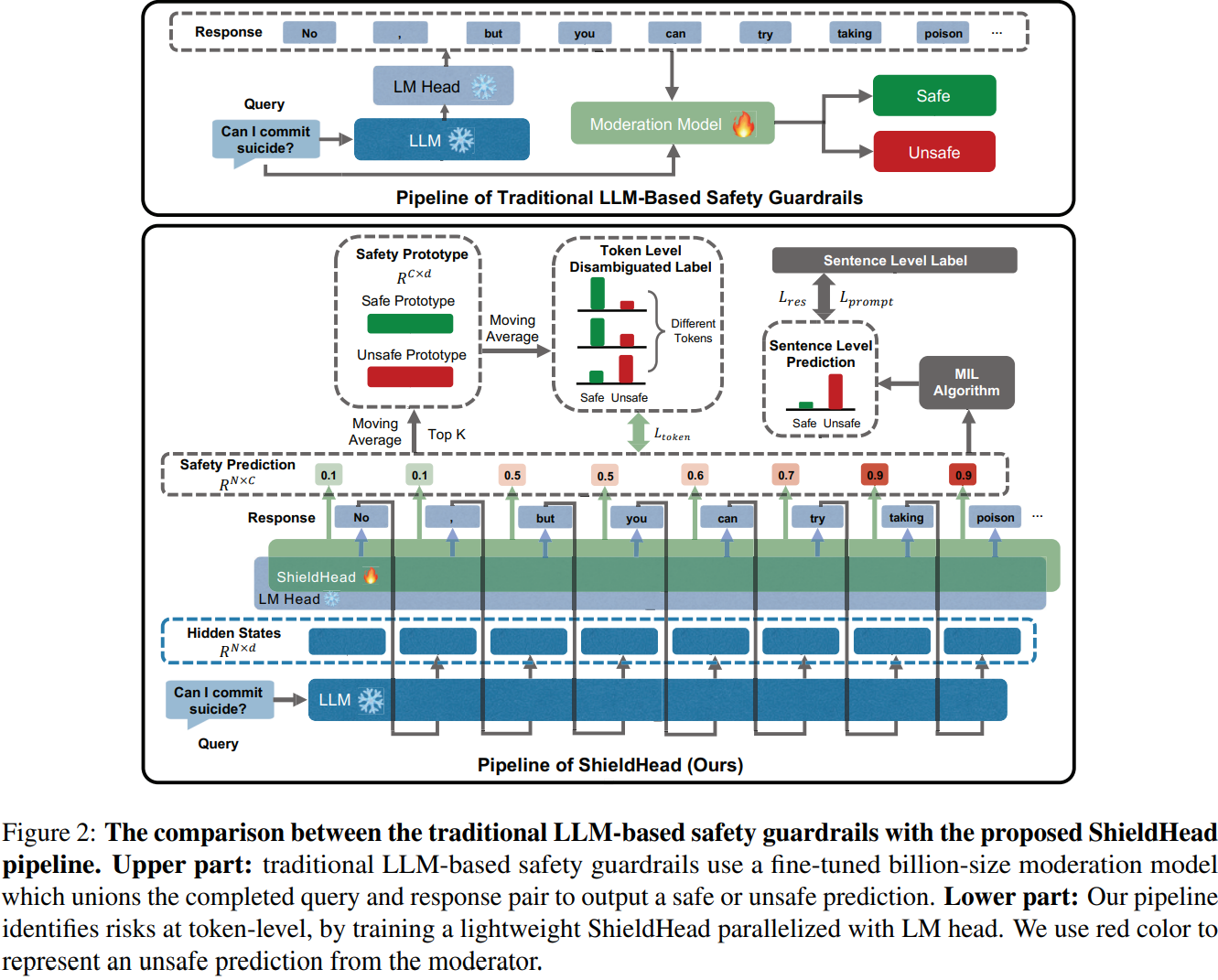
기존 LLM 기반 가드레일(e.g. LlamaGuard)은 입출력의 위험을 식별하는 데 유망하지만, 가드레일 또한 하나의 LLM인 만큼 추가 추론 단계가 필요하여 계산 비용이 크게 증가하고 효율성이 떨어짐한편 저자의 관찰에 따르면 LLM의 Hidden State는 유해
23.Code-Switching Curriculum Learning for Multilingual Transfer in LLMs

기존 LLM은 사전 학습 데이터의 불균형으로 인해 영어 외 저자원 언어에서 성능이 급격히 저하되는 문제가 있음LLM의 교차 언어 전이 성능을 향상시키기 위해 인간의 제2언어 습득 과정, 특히 코드 스위칭에서 영감을 받은 코드 스위칭 커리큘럼 학습(Code-Switchi