Introduction
- 탐지, 진단, 조치 등 인시던트 관리의 다양한 행동 요소들을 AIOps 기술을 통해 자동화하고 있지만, 그 근본 원인과 조치를 파악하는 데는 여전히 온-콜 엔지니어가 많은 시간을 들여 직접 수행하고 있음
- GPT-3.x와 같은 대규모 언어 모델을 사용하여 과거 인시던트 데이터를 기반으로 새로운 인시던트에 대한 근본 원인 및 조치 방법 등을 자동으로 추천할 것을 제안함
Methodology
- 인시던트는 코드 버그, 종송석 문제, 인프라 장애, 구성 오류 등 다양한 문제로 인해 발생할 수 있기에 이러한 근본 원인을 파악하고 조치 방법을 결정하는 데는 전문적인 지식과 경험이 필요

→ 인시던트 생성 시 작성자가 입력한 제목과 그 외 정보 요약문을 바탕으로 LLM을 통해 인시던트의 근본 원인과 조치 방법 생성
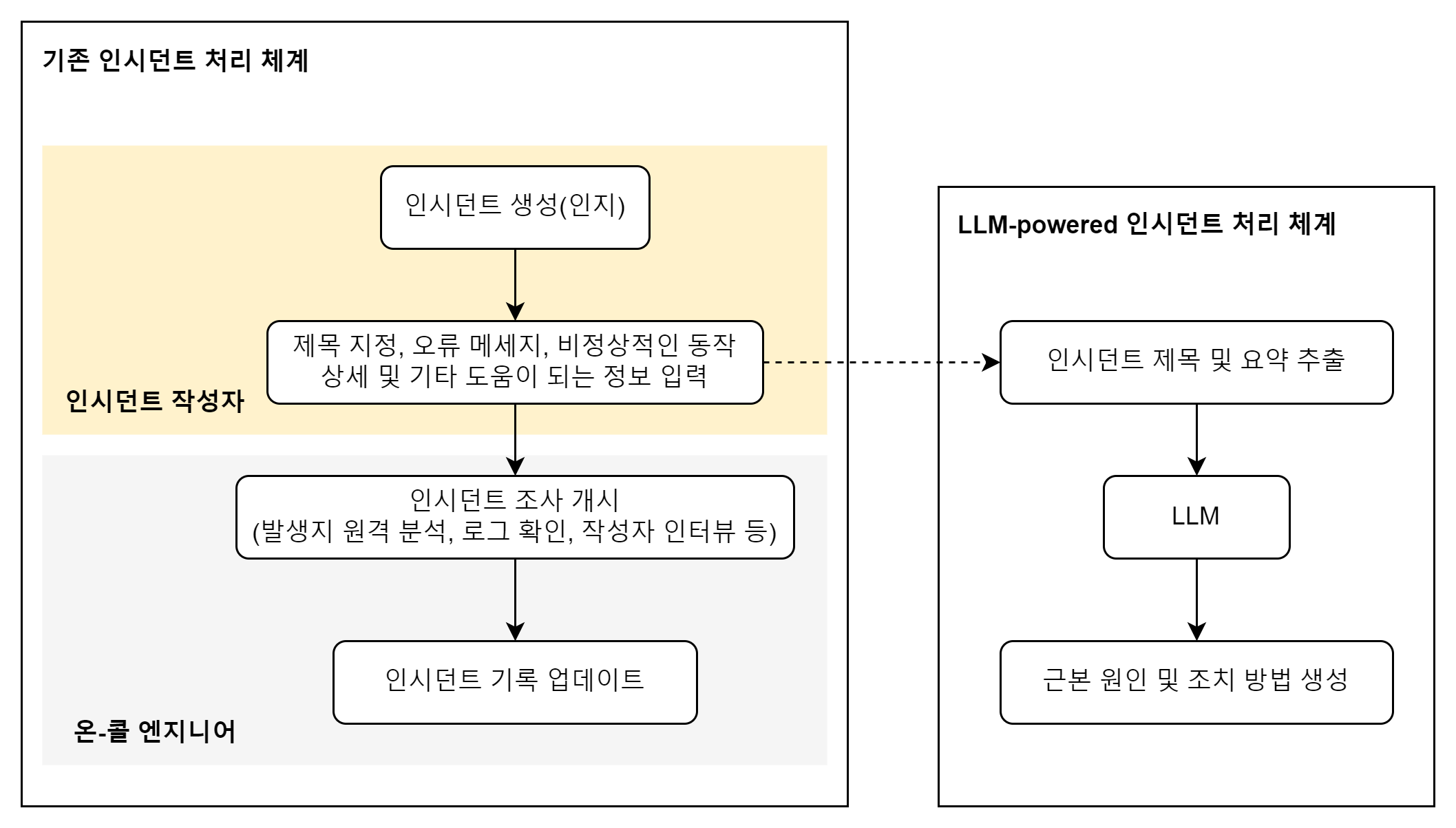
- 인시던트 요약문의 경우 LLM의 미세 조정 단계를 고려하여 표 및 이미지를 삭제하여 전처리
- 근본 원인과 조치 방법의 경우 단순 인시던트는 사후 조사에 의한 조치 방법의 검증은 진행되지 않으므로, 심각도 0~3의 중요 인시던트에 대해 중복을 제거하고 최대 100개 토큰으로 조정하여 전처리
- 상기 데이터를 바탕으로LoRA를 통해 근본 원인 탐색 및 조치 방법 생성 등 각각의 다운스트림 작업에 대해 RoBERTa, CodeBERT 및 GPT 모델 미세 조정
- 데이터셋은 근본 원인을 포함하는 훈련, 테스트 및 검증 데이터 각각 35820, 3000, 2000개 및 조치 방법을 포함하는 데이터 각각 5455, 2000, 500개로 구성됨
- 미세 조정하는 다운스트림 작업은 원론적인 답변보다 다양성 및 창의성이 나타나는 답변을 요구하므로 0.5~0.7 수준으로 Temperature 파라미터 업데이트
Result
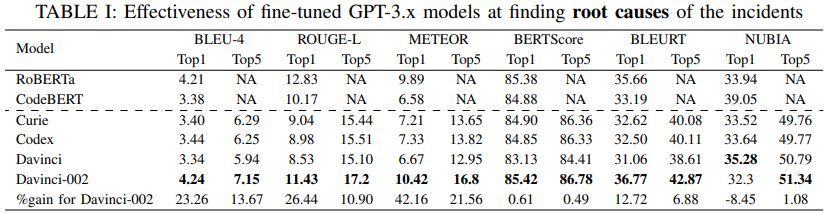
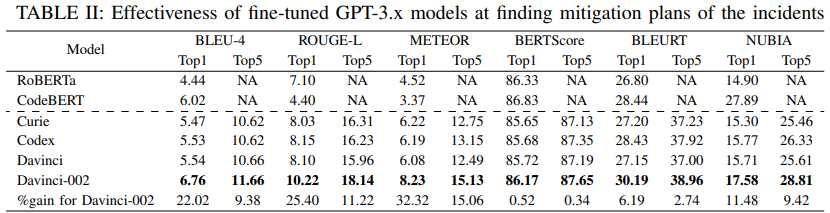
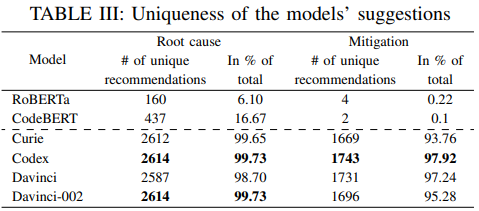

- 전반적으로 GPT-3.x 모델이 근본 원인 탐색 및 조치 방법 생성 등에서 우수한 성능을 보임
- 특히 근본 원인 탐색으로 얻은 정보를 조치 방법 생성 시 전달하면 GPT-3.5 기준 모든 지표에서 평균 26%의 성능 개선을 이룰 수 있었음
- 25명의 인시던트 오너에게 GPT-3.x 모델이 생성한 결과물에 관해 정확성 및 가독성 점수(1~5점 척도, 5점이 최고) 평가를 요청한 바 70% 이상이 3점 이상을 주었으며, 결과물에 대해 긍정적인 의견을 표명
- 단, 결과의 일반화가 어려울 수 있는 점, 블랙 스완에 대한 대책이 어려운 점, 사람을 대상으로 한 모델의 성능 검증은 표본 크기 부족으로 인해 통계적 유의성을 확보하기 어려운 점 등의 한계가 있음
