Introduction
- Relevant Passage를 성공적으로 Retrieve 해왔을지라도, 정답 생성에 방해가 되는 (Distracting) 문장들이 존재할 수 있음
- 일반적으로 정답을 생성하기 위해 필요한 정보는 Passage 중 일부에만 존재
- 이 문제를 해결하기 위해 FILCO(FILtering COntext) 방법을 제안
Method
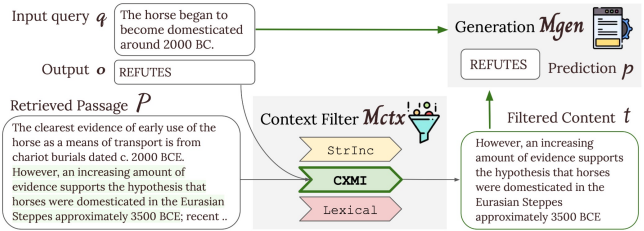
쿼리와 관련된 Passage 가 주어졌을 때, 모델에서 를 다시 필터링된 콘텐츠 를 생성하고 이를 쿼리와 함께 모델로 전달하여 최종 답변 생성
Oracle Filtered Content
String Inclustion, Lexical Overlap, Conditional Corss-Mutual Information (CXMI) 등 3개 필터링 방법으로 구성된 함수 에 쿼리 , 정답 Output , Passages 를 입력하여 Best Span 도출
- String Inclusion: Text Span 가 Output 를 텍스트 그대로 포함하고 있는지 여부를 판단하여 를 포함하는 첫 번째 를 로 반환
- Lexical Overlap: Example 와 간의 Unigram F1 Score를 측정하고 Threshold 보다 크고, 가장 값이 큰 를 로 도출
- Knowledge-grounded Response Generation 태스크일 때: fuf1(t,o) ∈ 0,1
- Fact Verification 태스크일 때:
- Conditional Cross-Mutual Information (CXMI): Input에 Text Span이 있는 경우와 없는 경우에 대한 정답 Output 생성 확률의 차이 측정하여 CXMI Score가 Threshold 보다 크고, 가장 값이 큰 를 로 도출
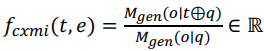
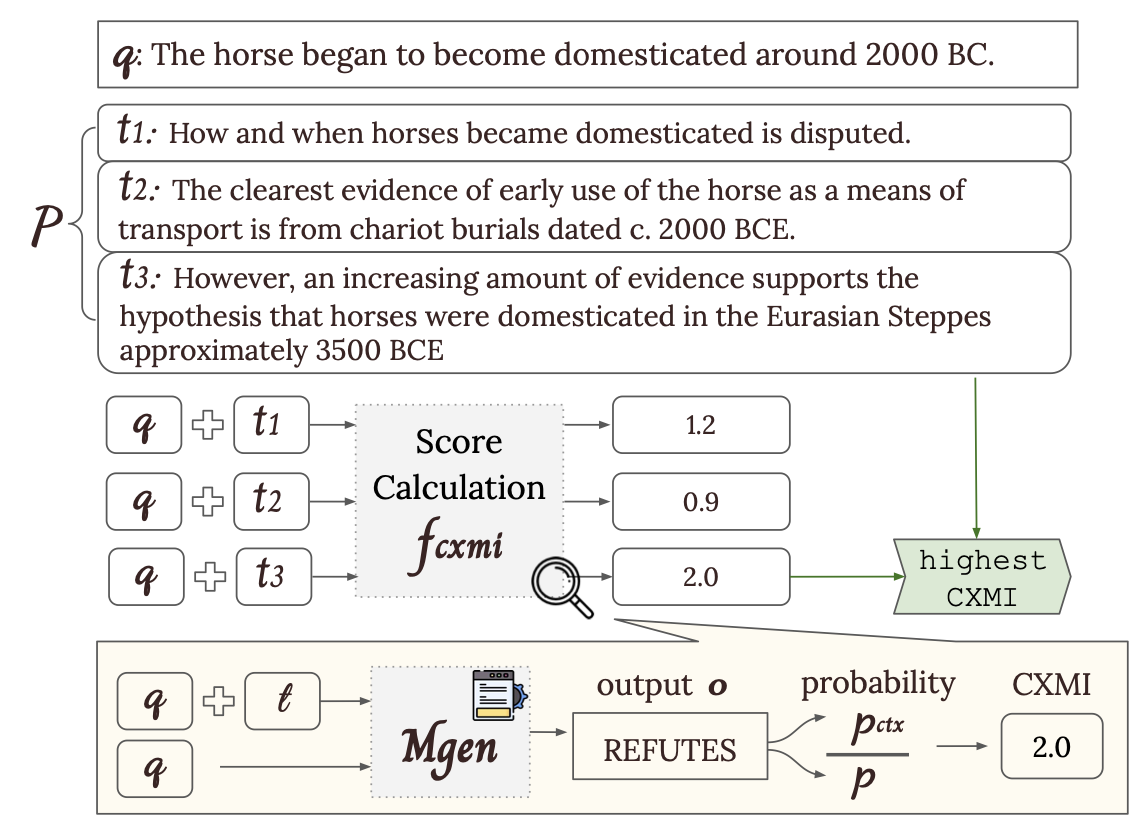
실험 시 데이터셋 특징 및 라벨 형태에 따라 각각 다른 추출 방법 적용
- Open-Domain Question Answering (ODQA):
NaturalQuestions(NQ) / TriviaQA(TQA) - String Inclusion 사용 - Fact Verification:
FEVER - Lexical Overlap 사용 - Multi-hop QA, Long-form QA, Knowledge-grounded Dialog Generation:
HotpotQA, ELI5, WoW - CXMI 사용
및 학습
- 주어진 데이터셋에 대하여 Oracle Filtered Content 도출
- 와 를 학습 샘플로 하고 를 라벨로 하여 LLM 기반 콘텐츠 필터링 모델 Fine-tuning
- 와 를 학습 샘플로 하고 를 라벨로 하여 LLM 모델 Fine-tuning
Result
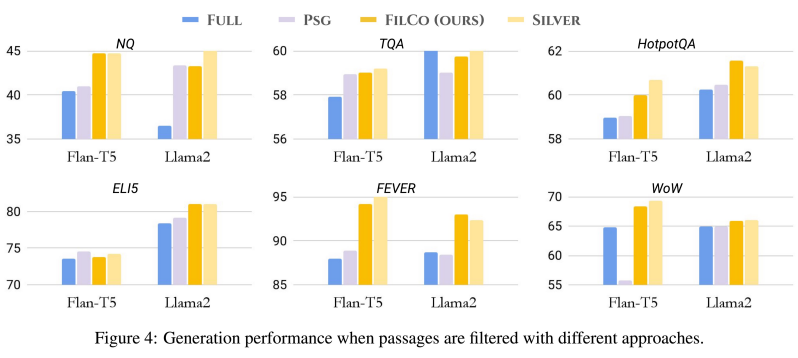
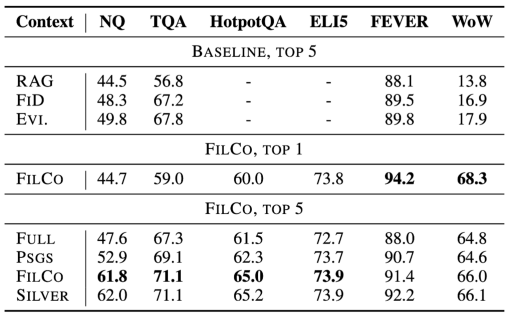
- FILCO 방법은 6개 데이터셋에서 모두 기존 Full-context 및 Passage-wise 필터링 방법보다 우수한 성능을 보임
- 특히 FEVER와 WoW와 같은 추상적 생성 태스크에서 큰 성능 향상을 보임 (FEVER: +6.2%, WoW: +3.5% F1 증가)
- 입력 길이를 44-64% 줄이면서도 성능 향상을 달성하여 계산 효율성 개선
- Retrive된 Passage가 정답을 포함하지 않는 경우에도 가 이를 필터링하며 Context의 품질을 개선하는 것으로 나타남
- 와 의 Fine-tuning이 모두 필요하고, 추론 시에도 두 모델이 모두 필요하여 초기 계산 비용이 높고 지연 시간이 김
