AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
Introduction
- 시계열 도메인에서는 대규모 데이터셋 부족과 사전 학습 기법의 미흡으로 인해 파운데이션 모델 개발이 자연어나 이미지 도메인에 비해 제한적이었음

- 기존 LLM을 시계열 예측에 활용한 연구들은 대부분 고정된 길이의 시계열만을 다룰 수 있다는 한계가 있었음
- 본 연구에서는 LLM의 자기회귀적 특성을 활용하여 가변 길이 시계열 예측이 가능한 AutoTimes 모델을 제안함
Methdology
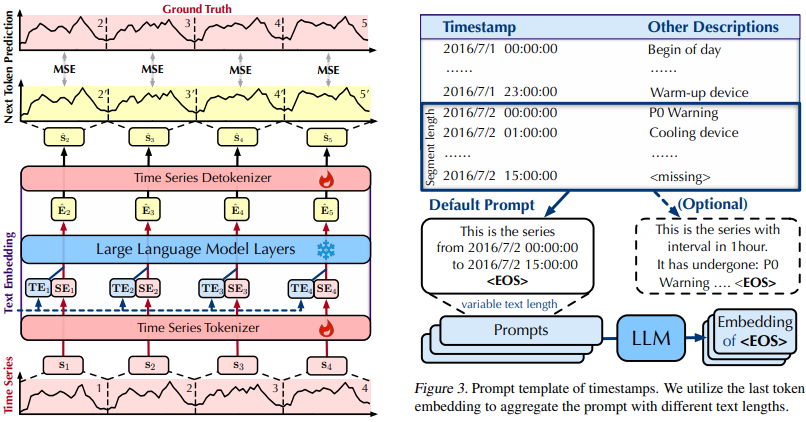
- 입력 시계열을 일정 길이의 세그먼트(Patch)로 나누고 각 세그먼트에 대해 Series Embedding(SE)과 Text Embedding(TE)을 생성
- SE와 TE를 결합하여 LLM의 입력으로 사용
- LLM의 가중치는 고정하고 시계열 토크나이저와 시계열 디토크나이저에 대해서만 다음 토큰(Patch)을 예측하도록 학습
Series Embedding (SE)
- LLM 앞 뒤에 Linear 레이어로 구성된 TimeSeriesTokenizer와 TimeSeriesDetokenizer 배치
- TimeSeriesTokenizer: 시계열 세그먼트를 LLM의 Hidden Dimension에 맞게 변환
- TimeSeriesDetokenizer: LLM의 출력을 다시 시계열 세그먼트로 복원
Text Embedding (TE)
- 자연어 형태의 각 시계열 세그먼트 타임스탬프 정보를 포함
- 필요시 세그먼트의 정성적 특징 정보도 추가 가능
- LLM의 임베딩 모델을 사용하여 텍스트를 임베딩으로 변환
Autoregressive Forecasting
- GPT-2와 같은 자기회귀 모델을 기반으로 하여 유연한 Lookback 및 Forecasting Length 지원
- 예측된 세그먼트를 다음 입력으로 사용하여 연속적인 예측 수행
In-context Forecasting
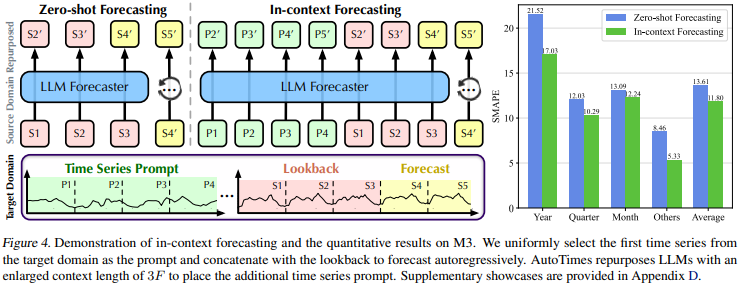
- Context와 예측하고자 하는 지점의 Lookback 데이터를 함께 LLM에 입력으로 전달하여 예측하는 기법
- 예측 길이를 F라 할 때, 각 시계열 데이터 샘플의 초기 2F 길이를 Context로 사용
- Lookback만 사용하여 예측하는 Zero-shot 대비 최대 5% 예측 성능 향상
Result
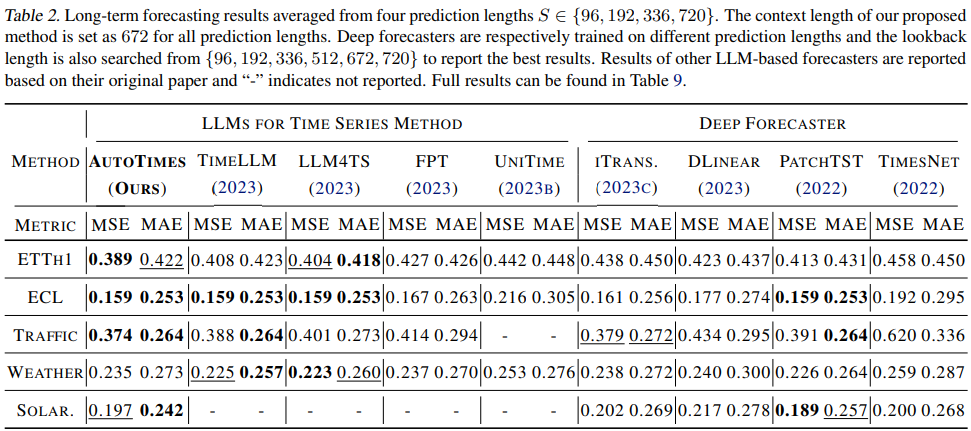
- Autotimes는 가변 길이 예측, Zero-shot, In-context learning 면에서 강점을 보임
- 백본 LLM의 크기가 증가할 수록 예측 성능 또한 향상되는 경향이 나타남
- In-context forecasting의 성능 개선이 Context라는 개념에 의한 것인지, 단순히 Lookback 길이가 증가한 데 따른 것인지에 대해서는 고려의 여지가 있음
