Introduction
- 최첨단 딥러닝 모델은 Trend, Seasonal, Residual과 같은 요소들을 고려하지 못하는 경우가 많고, 단순한 모델과의 실험적 비교에서도 성능이 예상하는 바보다 우수하지 못함
- LLaMA 및 CLIP 등 NLP 및 CV에서 부상하는 파운데이션 모델의 활용은 시계열 예측에서 사전 학습된 모델의 잠재력을 시사함
Methodology
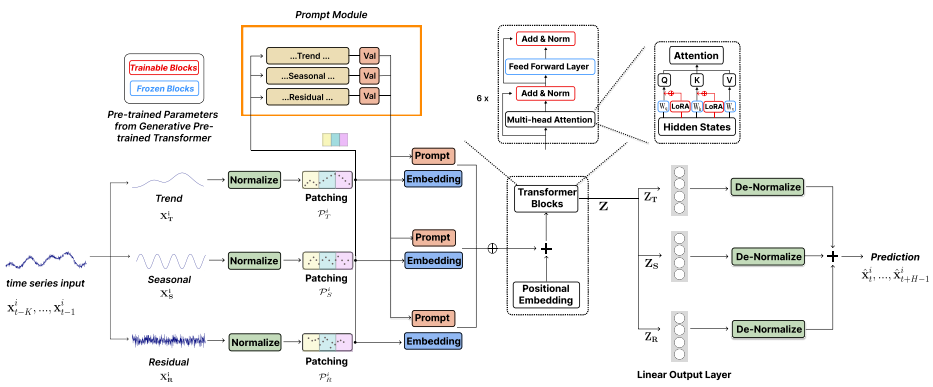
본 논문에서는 파운데이션 모델로써 LLM을 활용해 Time-series 예측하고, 덧붙여 STL Decomposition과 Prompt Pool을 이용해 예측 성능 향상을 도모함
Workflow
- STL Decompsition을 통해 Input Time-series를 Trend, Seasonal, Residual로 분해
- RevIN 및 Patching 수행
- Patched Time-series와 Prompt Pool의 Key를 코사인 유사도 기반으로 매칭 스코어를 구하여 매칭
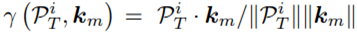 Score-matching Process
Score-matching Process
- Top-k Key의 Value를 임베딩된 Patched Time-series와 Concat
- 위 단계를 거치며 전처리된 Trend, Seasonal, Residual의 샘플의 Concat하여 베이스라인 LLM에 입력
- 예측된 Trend, Seasonal, Residual을 De-nomalization 후 복원
STL Decomposition
- 복잡한 Time-series를 Trend 및 Seasonal 성분과 같은 의미 있는 성분으로 분해하여 표현하면 최적의 정보를 추출하는 데 도움이 될 수 있음
- 고정 윈도우 크기를 사용하여 로컬 분해를 수행하며 N-BEAT에 근거하여 학습 가능한 파라미터 도입
Prompts Pool
- 프롬프트 길이, 프롬프트 크기 및 Top-k 수 등은 하이퍼 파라미터로 결정
- 유사한 Time-series 들은 동일한 Key로 묶여 해당 Key와 매칭되는 Value와 함께 LLM의 입력으로 제공됨
- 시간에 따라 변화하는 Time-series에서 동일한 key-value 반복되는 패턴이 나타나면 LLM이 Time-series의 Temporal한 특징을 보다 쉽게 이해할 수 있을 것임
- 특히 Trend, Seasonal, Residual 마다 이러한 패턴을 추상화하여 특징을 풍부하게 함
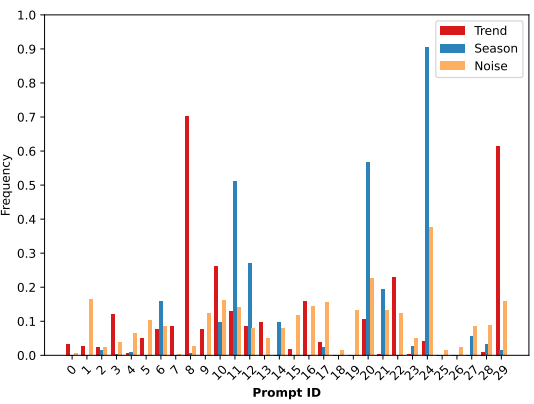 Trend, Seasonal, Residual 별 프롬프트 선택 분포
Trend, Seasonal, Residual 별 프롬프트 선택 분포
- Prompt Pool의 key-value pairs 값은 파라미터로 초기 랜덤한 값으로 정해지고 학습됨
- Key는 일종의 클러스터링의 Centroid와 같은 존재로 비슷한 Time-series를 묶기 위한 기준이 되고, Value는 각 클러스터를 설명하기 위한 정보를 포함하는 역할을 하며 각각 학습되는 것으로 추정
Zero Shot Long-term Result
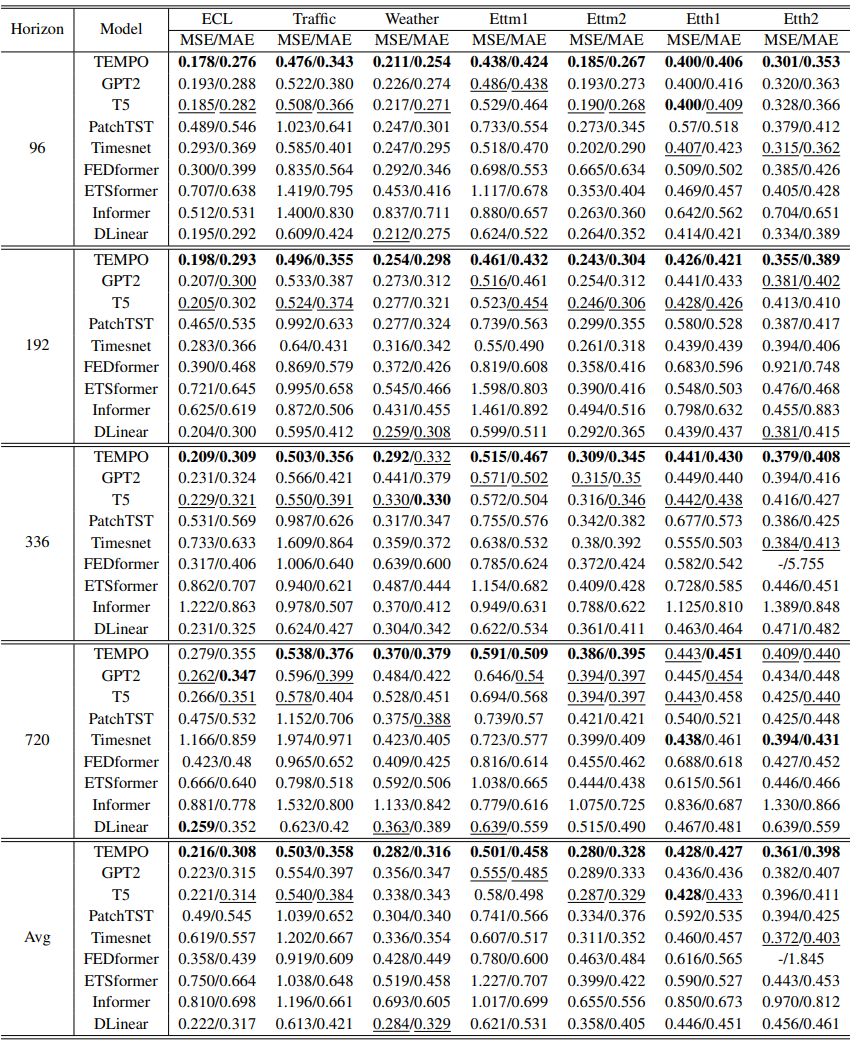
- 파운데이션 모델에 기반한 만큼 Zero Shot 케이스에서 기존 SOTA에 비해 더 우수한 성능을 보임
- TEMPO와 유사한 기타 파운데이션 모델 기반 Time-series 예측 모델과의 성능 비교는 논문에서 다루지 않는 관계로 별도 확인이 필요함
