Introduction
- LLM을 Time-series에 맞추어 Fine-tuning하는데는 많은 데이터가 필요하고, 도메인 어그노스틱한 모델을 개발하기가 어려움
- Time-series를 텍스트로 취급하거나 Multivariate Time-series를 Univariate로 취급하는 것은 일정하지 못한 결과물을 도출하는 점, 입력 시퀸스가 길면 이전 Unvariate를 잊어버린다는 점 등의 문제가 있음
- 임베딩 레이어 대신 Text Prototypes Align을 통해 Time-series를 임베딩하고 소프트 프롬프트를 통해 Instruction을 전달하여 Fine-tuning 없이도 Time-series 도메인에 LLM을 활용하는 방법 TEST 제안
Methodology
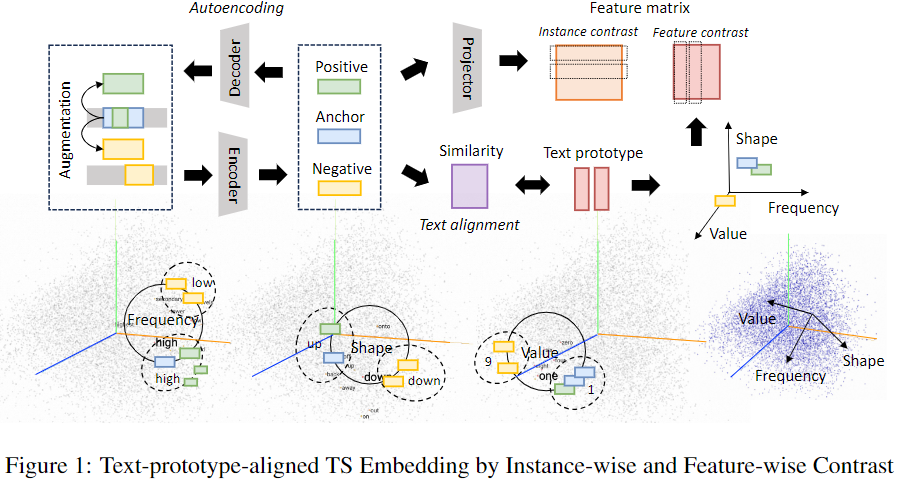 TEST는 크게 Time-series Embedding, Instance-wise/Feature-wise CL, Text-prototype-aligned CL, Learnable Prompt Embedding 등 4개 기능으로 구성됨
TEST는 크게 Time-series Embedding, Instance-wise/Feature-wise CL, Text-prototype-aligned CL, Learnable Prompt Embedding 등 4개 기능으로 구성됨
Time-series Embedding
- 다변량 Time-series 를 오버랩 없는 k개의 타임 윈도우로 나누어 를 구함
- 를 앵커 인스턴스로 할 때, 지터와 스케일링을 적용한 와 지터와 퍼뮤테이션을 적용한 를 각각 구하고 이들을 로 함
- 외의 다른 인스턴스를 로 함
- AutoEncoder를 통해 임베딩한 후 Linear 레이어로 Projection
a. AutoEncoder는 복원 손실로 훈련됨
b. 디코더는 훈련 시에만 사용되며 테스트 및 추론 시에는 사용되지 않음
c. 후속 훈련 과정을 AutoEncoder가 직접하는 게 아닌 별도의 Linear 레이어 를 통해 수행하여 AutoEncoder의 임베딩 공간이 붕괴되는 위험을 회피 - Instance-wise 및 Feature-wise Contrastive Learning(CL) 각각 진행
임베딩 차원 붕괴란?
임베딩 공간의 엔티티들이 다른 의미를 가지고 있음에도 불구하고 서로 유사하거나 동일해지는 상황을 임베딩 차원 붕괴라 함
Contrastive Learning에서는 손실 함수의 설계에 한계가 있거나 대조되는 데이터 쌍에 불균형이 있는 경우, 증강된 데이터의 다양성이 부족한 경우에 발생할 우려가 있음
Instance-wise CL
앵커 인스턴스가 강 증강 인스턴스 및 약 증강 인스턴스 등 포지티브 페어와는 가깝도록, 같은 배지 내 앵커 인스턴스가 아닌 인스턴스 등 네어티브 페어와는 멀도록 훈련: 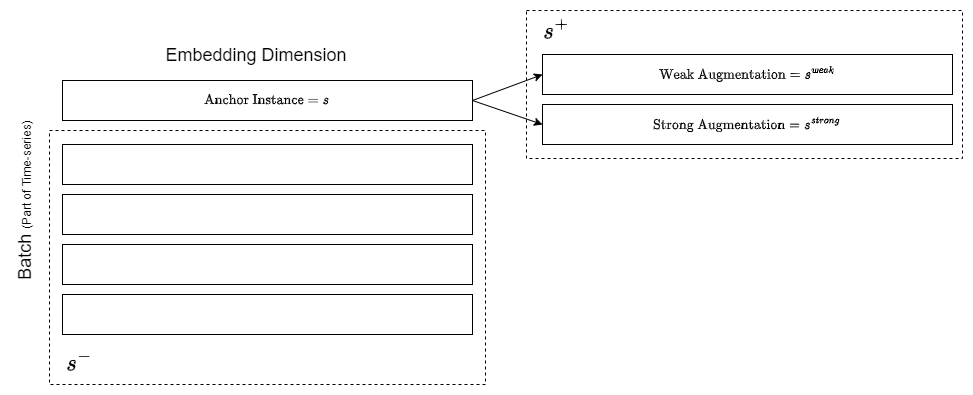
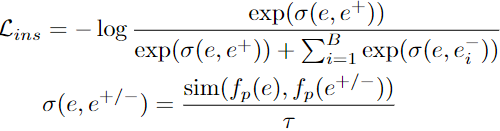 → Contrastive Learning을 통해 인스턴스 별 고유 Time-series 패턴을 추상화
→ Contrastive Learning을 통해 인스턴스 별 고유 Time-series 패턴을 추상화
Feature-wise CL
특정 인스턴스를 배지 길이 만큼 복사하여 만든 앵커 매트릭스에서 i번째 열이 배지 매트릭스의 i번째 열과 가깝도록, i번째 이외의 열과는 멀도록 훈련: 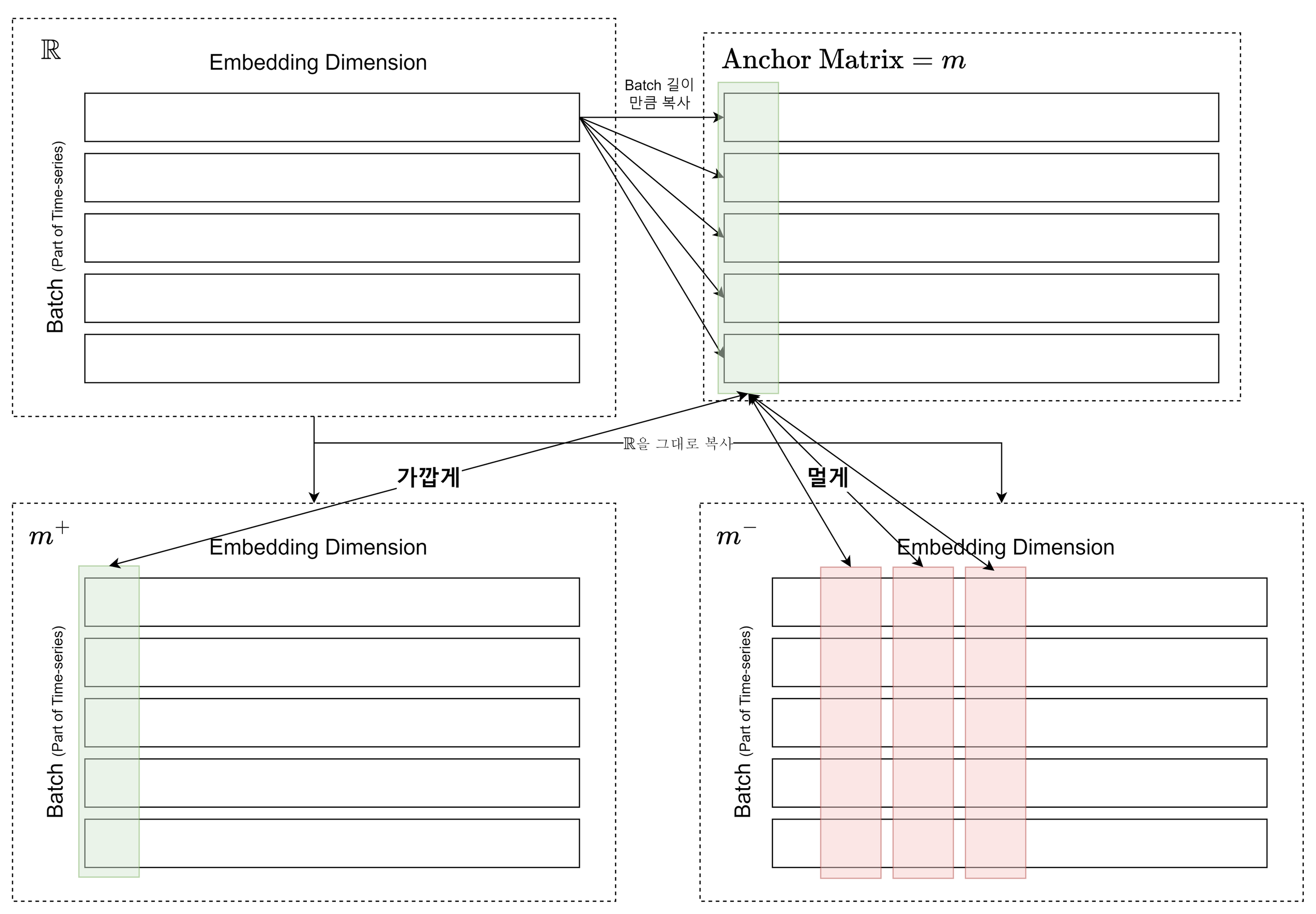
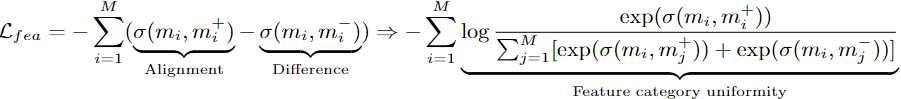 → 인스턴스 간의 표현에 대해서만 Contrastive Learning을 진행하는 독립성을 넘어서, 특징 차원 간의 표현에 대해서도 Contrastive Learning을 진행하여 풍부한 패턴 정보 추상화
→ 인스턴스 간의 표현에 대해서만 Contrastive Learning을 진행하는 독립성을 넘어서, 특징 차원 간의 표현에 대해서도 Contrastive Learning을 진행하여 풍부한 패턴 정보 추상화
Text-prototype-aligned CL
- 클러스터링을 통해 LLM의 Vocab에서 P개의 Text Prototypes 추출 후 Time-series 임베딩을 Text 임베딩에 매핑:
- Time-series 임베딩이 의미론적으로 유사한 Text Prototype과 가깝고 그 외 Text Prototype과 멀도록 훈련:
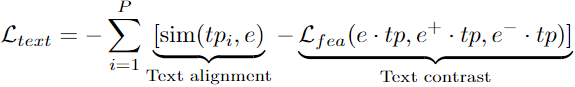 → 가 Instance-wise/Feature-wise CL을 통해 Time-series의 패턴을 잘 추상화하였다고 가정하고, 이 패턴을 Text 임베딩에 매핑한 후 Text 임베딩의 Representation Space에서 이 패턴이 잘 유지되도록 훈련
→ 가 Instance-wise/Feature-wise CL을 통해 Time-series의 패턴을 잘 추상화하였다고 가정하고, 이 패턴을 Text 임베딩에 매핑한 후 Text 임베딩의 Representation Space에서 이 패턴이 잘 유지되도록 훈련
Learnable Prompt Embedding
훈련 가능한 파라미터로 구성된 소프트 프롬프트와 임베딩 출력을 Concat 후 LLM에 입력을 전달하였을 때 출력과 Ground Truth 간의 손실이 최소화되도록 훈련: 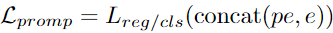 → 미세 조정되지 않은 LLM이 제안하는 방법론으로부터 입력을 받아 다운스트림을 수행하기 위해서는 다운스트림에 대한 적정한 Instruction이 필요하므로, LLM 출력 결과와 Ground Truth 간의 차이를 손실로 하는 학습 가능한 파라미터를 이용해 Soft Prompt를 구축하여 다운스트림 종류별(Regression, Classification 등)로 Instruction 주입
→ 미세 조정되지 않은 LLM이 제안하는 방법론으로부터 입력을 받아 다운스트림을 수행하기 위해서는 다운스트림에 대한 적정한 Instruction이 필요하므로, LLM 출력 결과와 Ground Truth 간의 차이를 손실로 하는 학습 가능한 파라미터를 이용해 Soft Prompt를 구축하여 다운스트림 종류별(Regression, Classification 등)로 Instruction 주입
Result
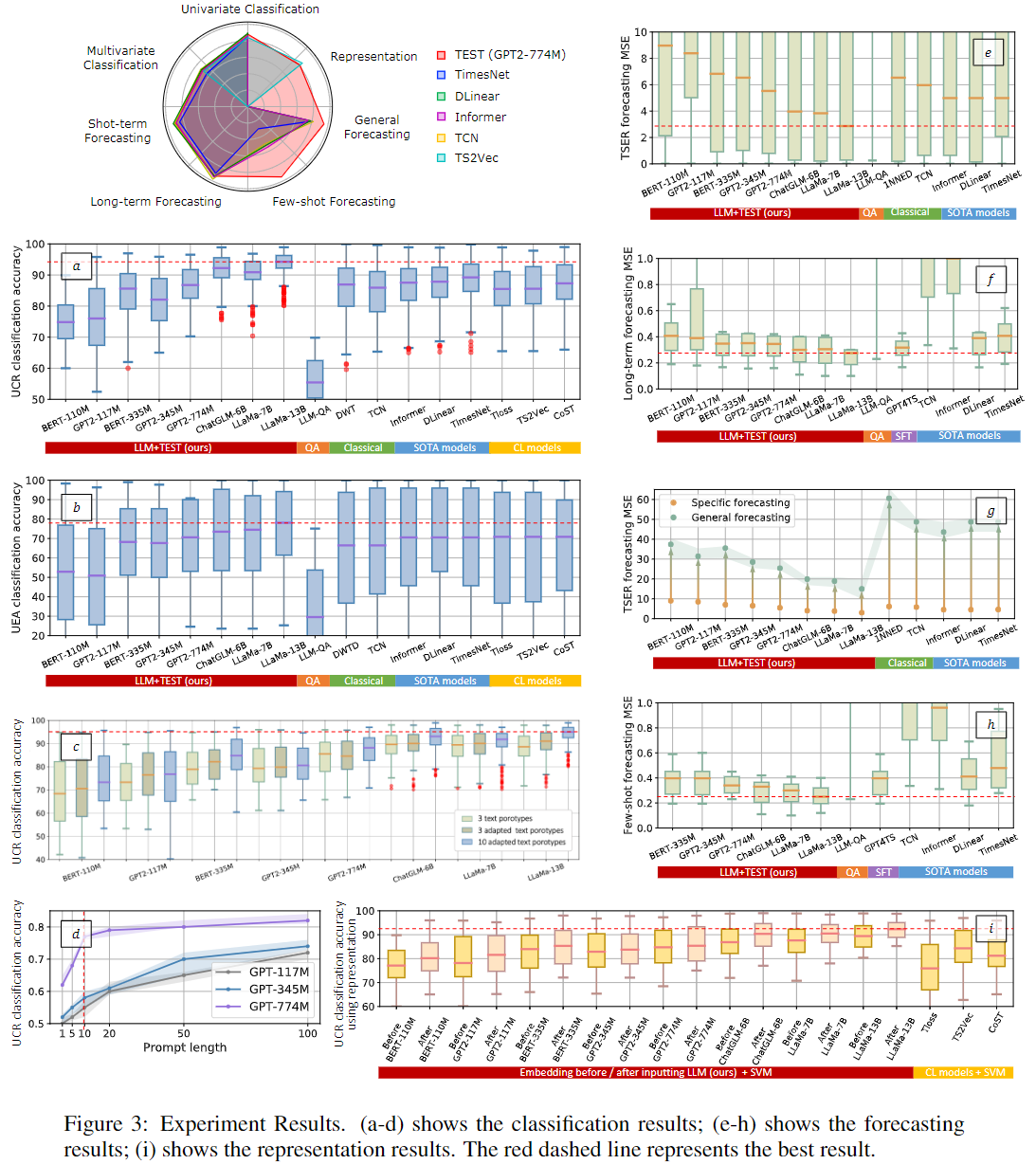
- Time-series 다운스트림 작업에서 LLM의 Fine-tuning을 진행하지 않고도 Fine-tuning을 진행한 모델과 유사한 성능 달성
- 단 전반적으로 Fine-tuninig을 진행한 편이 제안하는 방법론에 비해 더 우수한 성능을 보여주기는 하였음
- Fine-tuning을 진행한 모델에 비해 상대적으로 적은 데이터 사용
