
Introduction
2024년 9월 구글은 AI agents 소개, agent의 구성, 동작방식, 예제를 통해 알아보는 현실세계 적용방안까지 포괄적으로 포함한 AI Agent Whitepaper를 발간 및 공개하였다.
이에 따르면 생성형 AI 모델과 추론(Reasoning), 논리성(logic) 그리고 외부 정보로의 접근(Access to external information) 능력을 포함하여 이들이 모두 결합되고 상호작용하는것이 agent의 핵심 개념이라고 설명하고 있다.
본 블로그 글에서는 2024 Google AI agent Whitepaper에 소개된 목차 순서대로 내용을 요약하여 정리하고자 하였다.
What is an agent?
에이전트란 무엇인가?
- Generative AI Agent의 근본적 정의 : 세상을 관찰하고 tools을 사용하여 행동함으로써 목표를 달성하려는 애플리케이션
- 넓은 의미에서 위와같이 설명되는 Agent의 특징으로는 크게 아래 3가지 특징이 있다.
- Autonomous(자율성) : 인간의 개입 없이도 동작한다
- Act Independently : 목표를 달성하기 위해 계획하고 행동을 실행한다
- Proactive : 명시적인 지침 없이도 다음 행동을 결정한다
- 이러한 Agent의 behavior/actions/decision making 과정을 구성하는 핵심적인 구성요소들은 어떻게 구성되어지는가? 크게 3가지 필수 components로 구성되며, 일반적인 Agent의 아키텍처는 아래 그림과 같다.
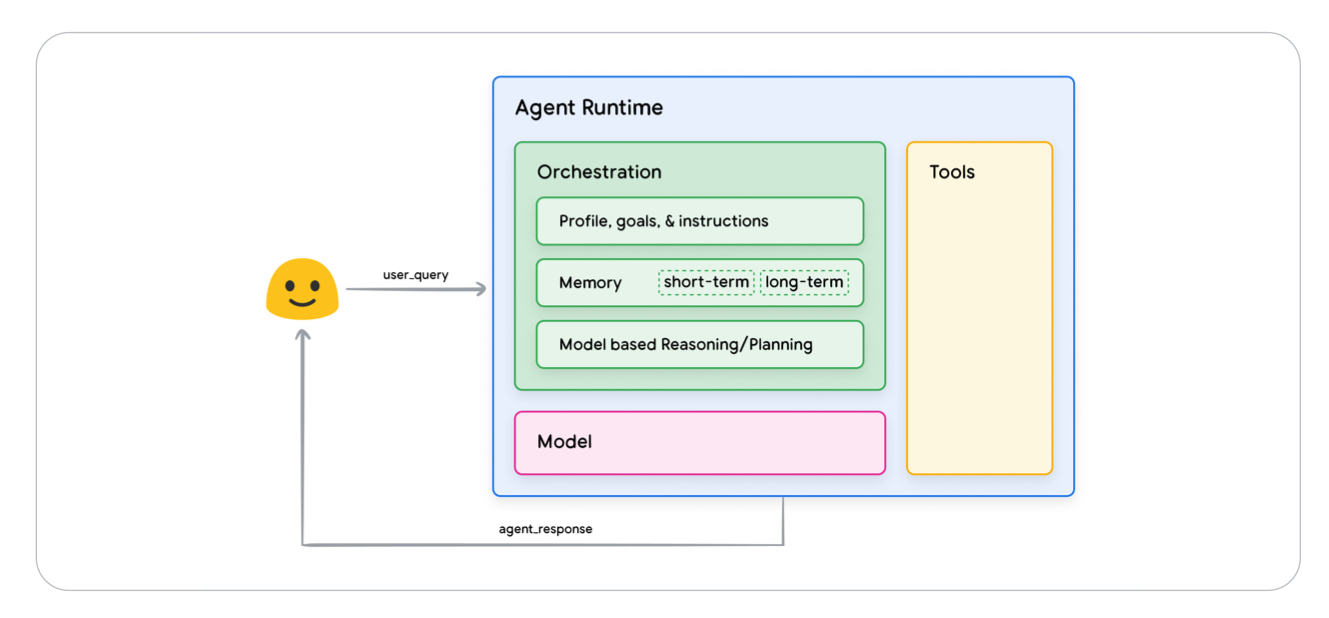
이 3가지 핵심 구성요소들은 mixing & mathcing 과정을 통해 위의 일반적인 아키텍처 형태 뿐 아니라, 여러가지 형태의 아키텍처로 만들어질 수 있다.
< 3 essential components >
- Model
- Tools
- Orchestration
이제 각 구성요소별 세부 내용을 설명한다.
The Model
- Agent의 관점에서 모델이란? Agent의 전체 process 과정에서 가장 핵심적이고 중앙집권적 방식의 Decision Maker 파트라고 볼 수 있다.
- 종류 : one or multiple의 small/large 사이즈 LM(Language Model)
- 일반적 목적의 Multimodal Model, 특정 도메인에 특화되어진 fine-tuned 모델 등
- agent 관점에서의 모델은 아래의 추론 framework에 기초하여 효율적으로 의사결정을 수행하게 된다.
- ReAct
- Chain-of-Thought
- Tree-of-Thougt 등…
- 모델으로부터 Best production results를 얻으려면?
- agent의 최종 application 단계에 가장 적합한 모델을 활용하는것이 가장 좋음(Object Detection, 3D Modeling, Image Generation 등…활용목적별로 여러가지 End Application 형태가 존재함)
- 이상적으로는, agent의 아키텍처 구상 및 계획 단계에서 사용예정인 tools과 연관된 data signatures로 학습되어진 모델을 사용하는 것이 모델의 performance 측면에서 가장 이상적이다!
The Tools
앞서 설명한 Model은 Outside world, 즉 모델이 학습과정에서 학습한 training data 외에 현실세계와의 상호작용이 제한된다는 측면에서 한계점이 존재한다.
Agent를 구성하는 Tools는, 모델이 그 자체로 혼자 동작할때보다 Tools를 활용함으로써 외부 데이터 및 서비스 정보와 상호작용할 수 있게되어 모델과 현실세계 간 Gap을 줄이고 모델의 가능성을 더욱 확장시킬 수 있다.
이러한 Tools는 정말 다양한 형태로 존재하지만, 대표적으로는 Web API Methods(GET / POST / PATCH / DELETE 등…)가 있음!
- Tool의 활용 예시
실시간 여행지 추천을 위해 날씨 데이터를 업데이트
➡️ OpenWeatherMap에서 제공하는 api를 통해 전세계 지역 날씨 정보를 실시간으로 받아와서 활용할 수 있음
The Orchestration Layer
Orchestration Layer 는 아래 그림과 같이 Agent에서 정보를 받아들이고, 내부 추론과정을 거친 후 다음 행동/결정을 판단하고 수행하며 Feedback 과정을 거치는 반복적인 Cyclical process를 포함한다.
+---------------------------+
| Information Intake |
+---------------------------+
↓
+---------------------------+
| Internal Reasoning |
+---------------------------+
↓
+---------------------------+
| Action Execution |
+---------------------------+
↓
+---------------------------+
| Feedback |
+---------------------------+
↺ 반복Orchestration Layer에서 이러한 loop 과정은 Agent가 사전에 설정된 목표에 도달하거나 또는 특정 stopping point가 되었을때까지 과정을 계속해서 반복하게 된다.
Agents vs Models
본 Whitepaper에서는 Agents와 Models 간 차이점을 아래 표로 정리하여 설명하고 있다.
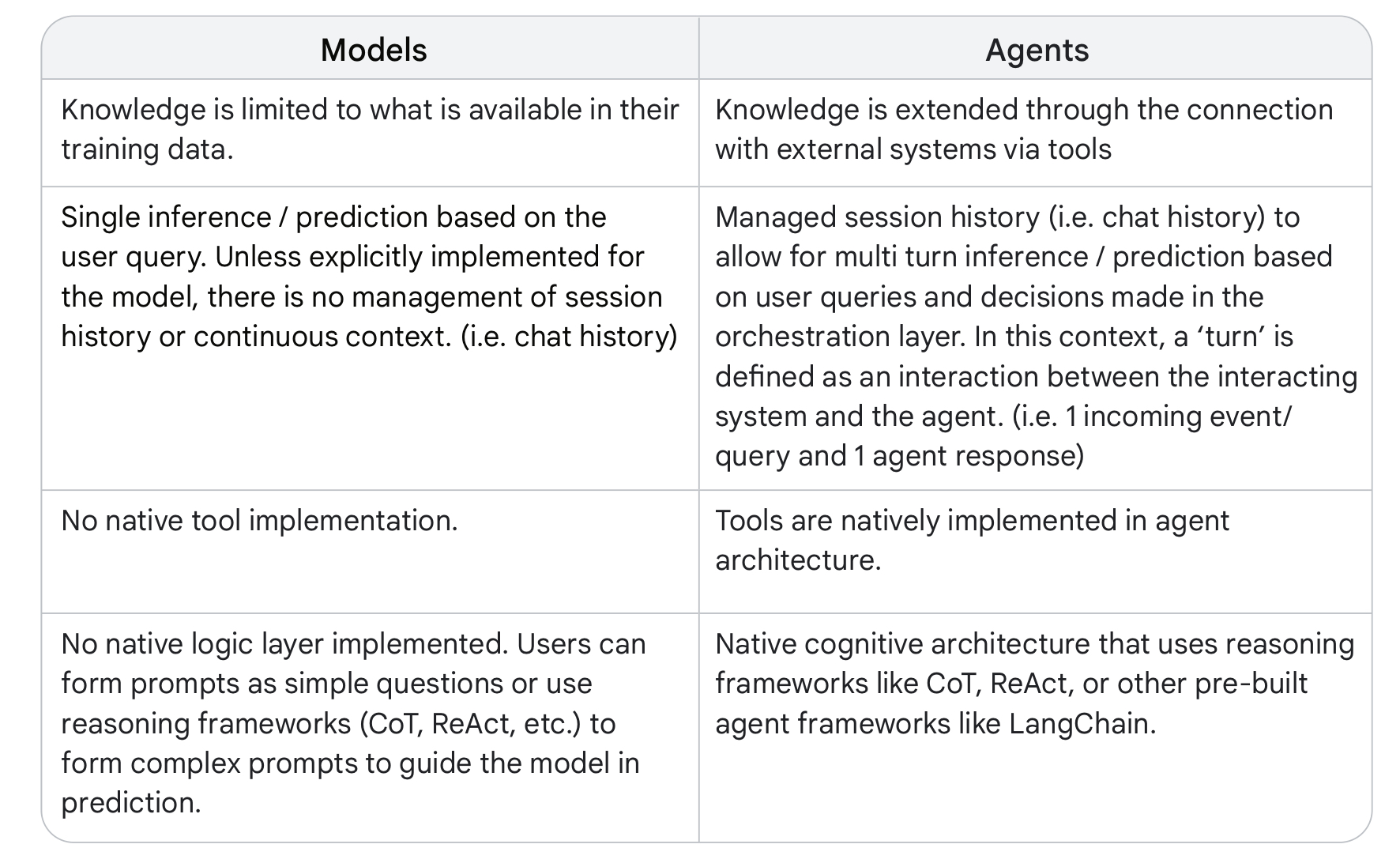
표에서 비교한 Model ↔️ Agent 간 차이점을 간단히 요약하면,
- Model : Agents를 구성하는 Tool과 Orchestration layer가 존재하지 않기 때문에, Model을 학습시킨 training data 외에 다른 Knowledge의 확장이 제한됨.
- Agent : Agents에서는 Model과 Tool, orchestration layer간 끊임없는 상호작용을 통해 Knowledge의 확장이 이루어지며 이전에 User가 수행한 작업들(session history 등)에 대한 피드백 또한 적절히 반영하여 작업을 수행할 수 있음
Cognitive architectures: How agents operate
현실세계에서 발생가능한 구체적인 상황예시를 통해, Agents의 각 구성요소들이 어떻게 상호작용하며 동작하는지를 설명한다.
[Example] 바쁜 주방에서 일하는 셰프가 있다.
- Goal : 식당에서 계획(Planning) ➡️ 실행(Execute) ➡️ 평가(Adjustment) 과정을 반복하며 맛있는 음식을 만드는 것
- 주문내용, 팬트리 또는 냉장고에 어떤 재료들이 있는지 등에 대한 여러가지 정보 확인
- 1️⃣번 과정에서 얻은 정보들을 바탕으로 어떤 요리나 맛을 만들어낼 수 있는지에 대한 내부 추론(Internal reasoning) 수행
- 2️⃣번 과정이 완료되면 요리를 만드는 Action을 수행
- 이후 음식을 맛본 소비자들의 평가, 가지고 있는 재료들에 대한 업데이트, 만든 요리에 대한 평가 등을 모두 포함한 종합적인 평가 결과를 얻음
위 예시처럼 현실 세계의 문제에서도 1~4번 과정이 반복적으로 수행되는데, 이러한 반복 과정의 핵심인 Orchestration layer에서 Memory, State, Reasoning, Planning 과정을 전반적으로 관리하게 된다. Orchestration Layer는 최근 대두되고 있는 Prompt Engineering, 그리고 관련 framework를 활용하여 Reasoning/Planning 단계를 지원하며 Agent가 더욱 효과적으로 외부 환경과 상호작용하고 목표를 완벽히 달성하도록 한다.
아래는 널리 사용되는 Framework 및 추론 Techniques의 일부이다.
ReAct
- 언어 모델에서 사용자의 의도 또는 생각 process를 user query로 제공하는 prompt engineering framework.
- ReAct Framework를 활용함으로써, 모델이 User의 의도대로 추론(Reasoning)하고 실행(Take Action)하게 하여 몇몇 SOTA baselines을 능가하는 성능을 확인할 수 있으며 LLM 모델의 신뢰성을 향상시킬 수 있다.
Chain-of-Thoughts
- 단계적 스텝을 통해 추론 능력을 가능하게하는 prompt engineering 프레임워크
- self-consistency, active-prompt, multimodal CoT 등 다양한 형태의 CoT 기술들이 있지만, 특정 활용분야에 따라 각각의 장/단점이 존재함.
Tree-of-Thoughts
- 탐색, 전략적 장기 목표 달성에 적합한 prompt engineering 프레임워크
- 일반화된 CoT prompting 이라고 볼 수 있으며 언어 모델이 다양한 thought chains 을 가지며 단계적으로 문제를 해결하고 탐색하게함.
Tools : Our keys to the outside world
앞서 언급했지만 tool은 Agent 내 모델 ↔ Outside World 간 상호작용을 할 수 있도록 하는 매개체 역할을 함
이러한 tool의 역할 덕에, agent가 학습된 데이터에 국한되지 않고 더욱 다양하고 폭넓은 task를 수행할 수 있고 더 높은 정확도와 신뢰도를 가지게됨
- examples : 스마트홈 세팅 조정, 캘린더 정보 업데이트, DB에서 정보 패치, 실시간 이메일 보내기 등의 작업 수행 가능...
여기서 소개하는 3가지 주요 tools은 아래와 같다.
Extension
- agent(tool) ↔ API 간 연결 역할
- 입력한 user query에서 필요한 api로 연결가능하도록 코드 구현
- extension을 사용해 손쉽게 원하는 외부 기능들을 agent가 사용할 수 있도록 구현가능
Functions
- 다양한 작업 등을 수행하기 위해 제작된 모듈과 같음
- agent는 함수를 통해 매개변수를 만들고 api를 호출하며, 함수의 실행은 client side에서 실행된다.
- ex) 스키 여행 계획 시 추천 도시 목록을 모델에서 JSON 형식으로 만들고, 이를 client side(UI) 쪽에서 함수를 통해 google placees api 호출 후 최종 결과값을 user에게 반환
Data Stores
- 개발자는 Data Store를 통해 agent에게 데이터 변환, 모델 재학습 혹은 fine-tuning 등의 작업 없이도 추가적으로 원본 데이터를 제공가능하다.
- Data Store에서는 input으로 들어온 자료들을 embedding 하여 vector database로 저장하고, agent는 필요할때 이 정보들을 vector database에서 추출하여 사용.
- 언어모델에서 Data Store 사용의 가장 대표적인 예는 RAG(Retrieval Augmented Generation)이다. RAG에서는 모델에게 아래와 같은 다양한 포맷 형태의 데이터를 제공함으로써 모델이 최초에 학습하였던 데이터 외에도 더 폭넓고 깊은 지식으로 확장될 수 있게 한다.
- Website 자료
- pdf, docs, csv 등 정형화된 데이터 형태
- html, pdf, txt 등 비정형화된 데이터 형태
User가 query를 통해 Data Store에 접근하고 결과값을 받는 전체 과정은 아래 그림과 같다.
정리하자면 RAG는 그 자체보다 ReAct 프레임워크 등을 통한 agent의 추론 및 계획 수행 과정에서 RAG에 저장된 자료들을 참고하여 동작함!
Enhancing model performance with targeted learning
일반적인 task에서의 모델 성능향상 대신, 특정 지식이나 전문적인 task를 수행하는 모델의 성능향상을 위한 방법엔 어떤 방법이 있을까?
- In-context learning : 일반화된 모델에 적절한 prompt, tools, 몇개의 예시들을 제공하여 모델이 specific task를 수행하게 함. ReAct framework가 대표적이다.
- Retrieval-based in-context learning : 모델이 RAG와 같이 외부 메모리에 저장된 데이터들을 검색 및 활용하게 함
- Fine-tuning based learning : 수행하고자 하는 specific task에 맞는 일부 dataset을 모델에 학습시켜 파라미터값 조정
위 방식들은 속도, 비용, 지연시간 등의 측면에서 장단점이 명확하므로 이 특성을 알고 수행하고자 하는 task에 맞게 적절히 조합하여 사용하는 것이 중요하다고 본 백서에서는 강조하고 있다.
Agent quick start with LangChain
LangChain / LangGraph 라이브러리를 통해 빠르고 쉽게 agent prototype을 구현할 수 있음!
이는 앞서 언급한 logic, reasoning, tool 등을 순서대로 체인 형태로 연결하여 구성한 형태로, 입력한 User query가 의도한 특정한 task를 해결하기 위해 LangChain/LangGraph로 연결된 Model, Orchestration layer, Tool 모두 상호작용하며 유기적으로 동작한다.
구현 코드는 백서내용을 참고.
Production applications with Vertex Ai agents
이러한 agent를 활용한 실무 Application 개발단계에서 Google에서 제공하는 Vertex AI 플랫폼을 통해 agent를 구성하는 핵심 component(Model, Orchestration layer, Tool) 뿐 아니라 UI, 프레임워크 평가, 지속적인 성능향상 매커니즘까지 모두 통합하여 구성할 수 있다.
또한 자연어를 통해 User Interface를 생성하고, agent의 목표, task 지시, 활용할 tools, 예제 등 까지도 빠르게 정의할 수 있으며 Vertex AI 플랫폼에서는 agent의 테스트, 평가, 성능측정, 디버깅 등에 활용되는 tool까지 제공함
아래 그림이 전체적인 플랫폼 아키텍처를 간단히 나타낸다.
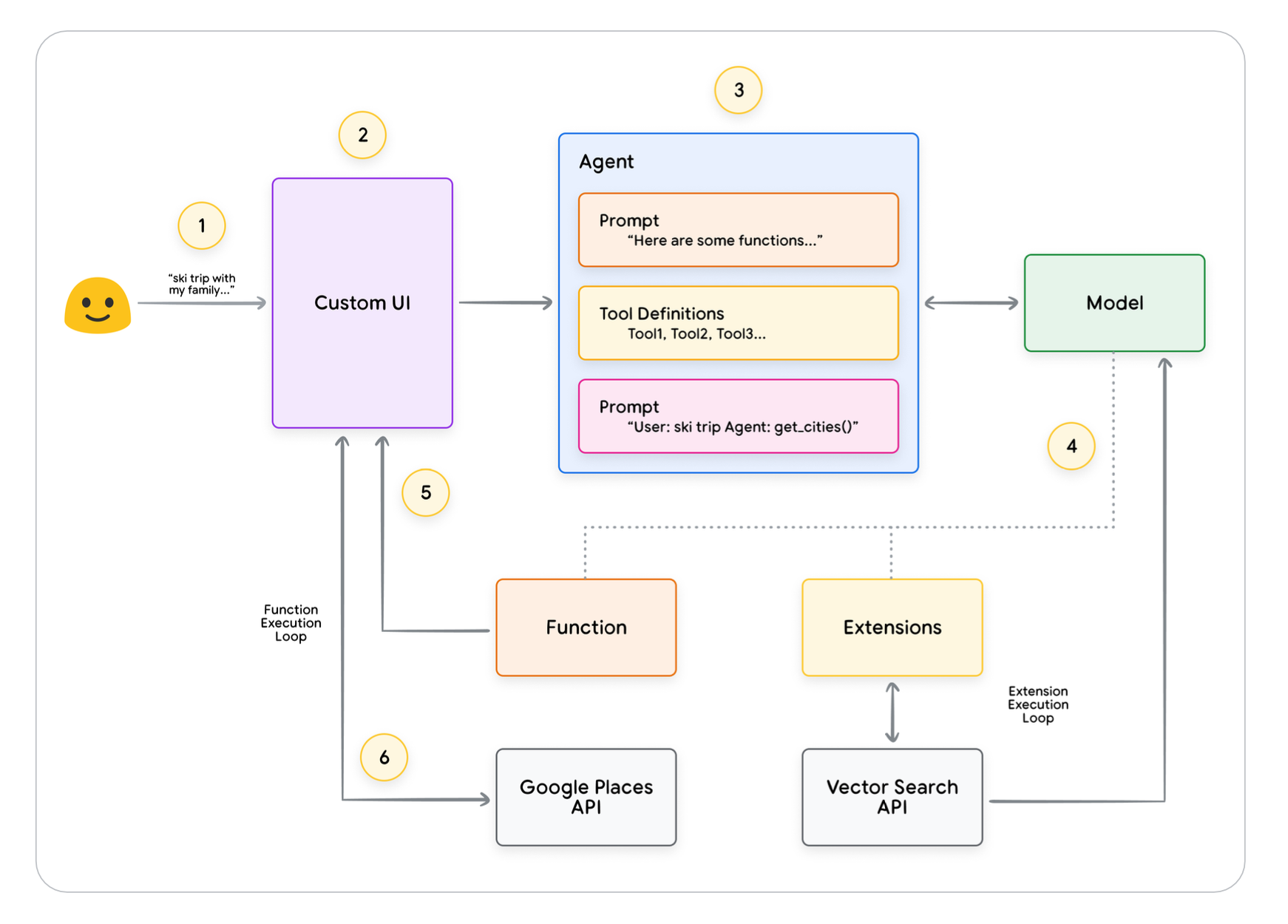
지금까지 구글에서 제공한 Agent 관련 백서의 내용을 요약하였고, 조만간 소개된 Vertex AI 플랫폼을 활용해서 이 백서에 언급된 예제들을 실제로 구현 및 배포하는 작업을 해볼 예정이다!
References
