딥러닝 학습을 위해서는 막대한 양의 데이터셋이 필요합니다.
LAION-400M은 무료 공개된 대규모 데이터셋으로,
높은 퀄리티의 image-text pair 데이터를 제공하고 있습니다.
Multi modal 인식을 위한 모델 학습 시 400M 개 정도의 데이터를 유용하게 사용할 수 있습니다.
이 데이터를 다운받는 방법에 대해 간단히 정리해 보았습니다.
링크: https://laion.ai/laion-400-open-dataset/
-
데이터셋 설치를 위한 패키지 설치
pip install img2dataset #aria2로 설치할 경우는 아래 패키지도 설치해야 하지만, 링크의 방법에서는 설치할 필요 없다. sudo apt-get install aria2 -
메타데이터 다운로드
#공식 문서 다운로드 링크는 아래와 같다. wget -l1 -r --no-parent https://the-eye.eu/public/AI/cah/laion400m-met-release/laion400m-meta/ #그러나 certificate 문제가 일어날 경우 아래와 같이 --no-check-certificate 를 추가해 준다. wget -l1 -r --no-check-certificate --no-parent https://the-eye.eu/public/AI/cah/laion400m-met-release/laion400m-meta/ #디렉토리를 옮겨 준다. mv the-eye.eu/public/AI/cah/laion400m-met-release/laion400m-meta/ .
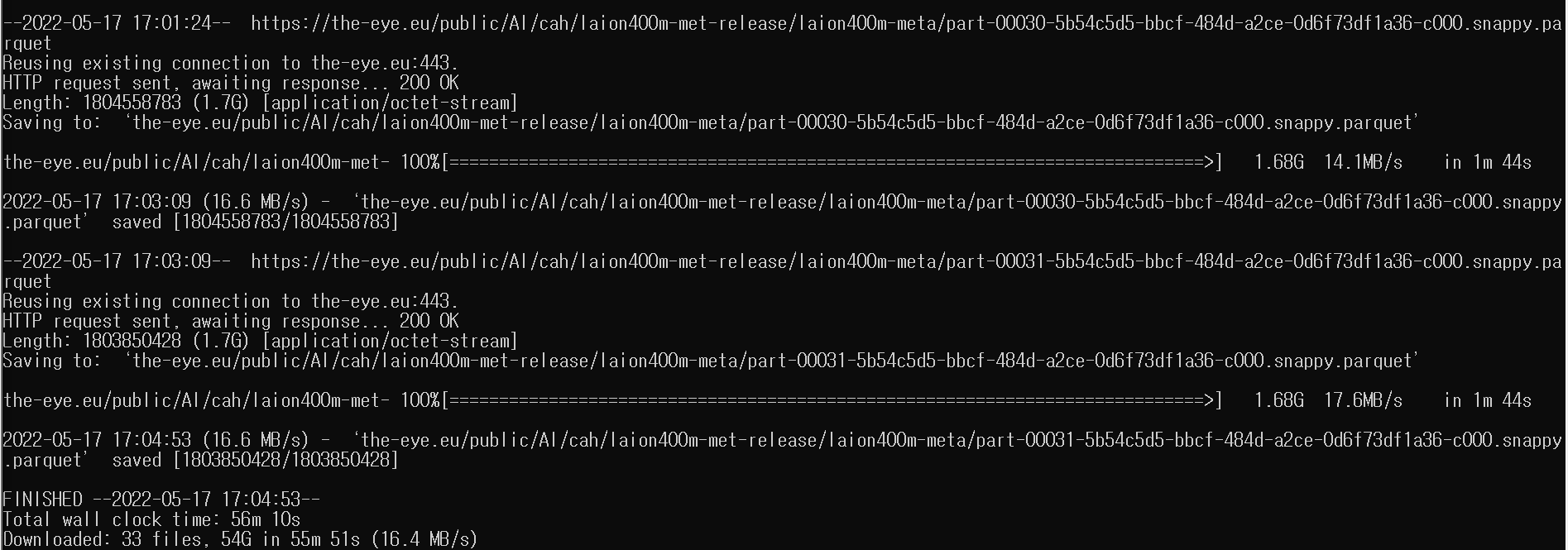
- 메타데이터 다운로드가 완료된 모습.
- 총 소요시간: 56m 10s / 총 다운로드 용량: 33files, 54G
- 모델 학습을 위한 본 데이터(이미지, 캡션 텍스트) 다운로드
img2dataset --url_list laion400m-meta --input_format "parquet"\ --url_col "URL" --caption_col "TEXT" --output_format webdataset\ --output_folder laion400m-data --processes_count 16 --thread_count 128 --image_size 256\ --save_additional_columns '["NSFW","similarity","LICENSE"]' --enable_wandb True
- 다운로드 진행 중인 화면. 아래와 같이 진행 상태를 보여준다. 메타 데이터의 링크를 통해 데이터를 다운받기 때문에, 다운로드 실패도 많이 있다.
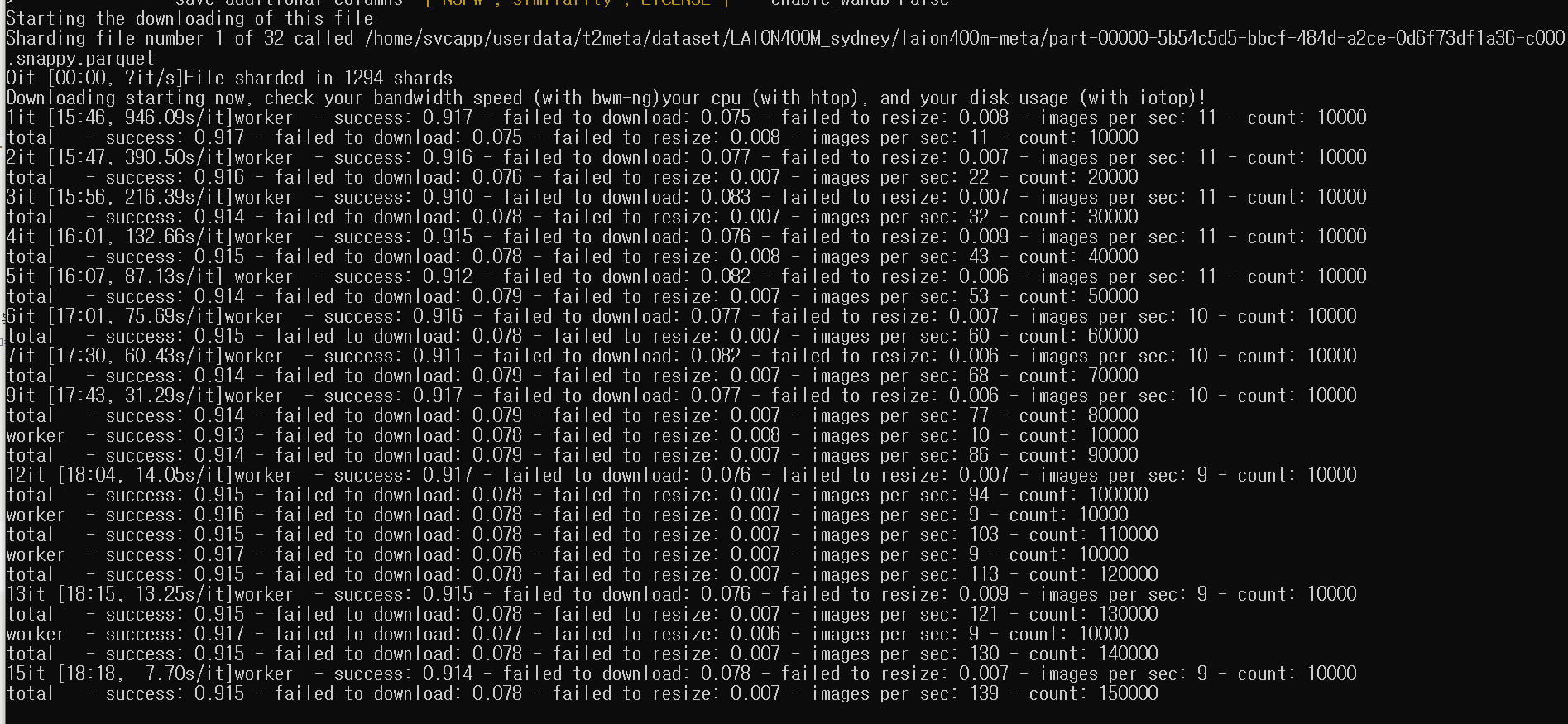
-
다운로드된 데이터 확인
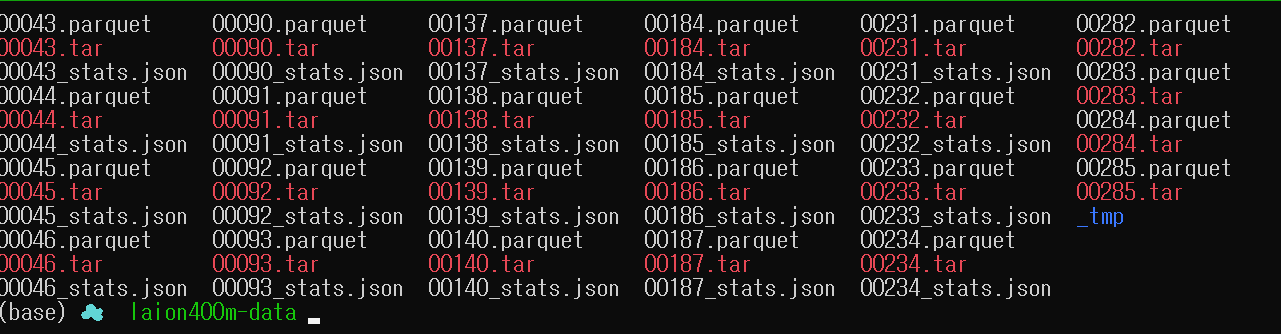
- 아래와 같이 데이터셋 한 개마다 1) 해당 데이터 다운로드 로그를 담고 있는 json파일, 2) RDB형태의 내용을 담고 있는 parquet 파일, 3) 데이터가 압축된 tar 파일 이 다운 받아집니다.
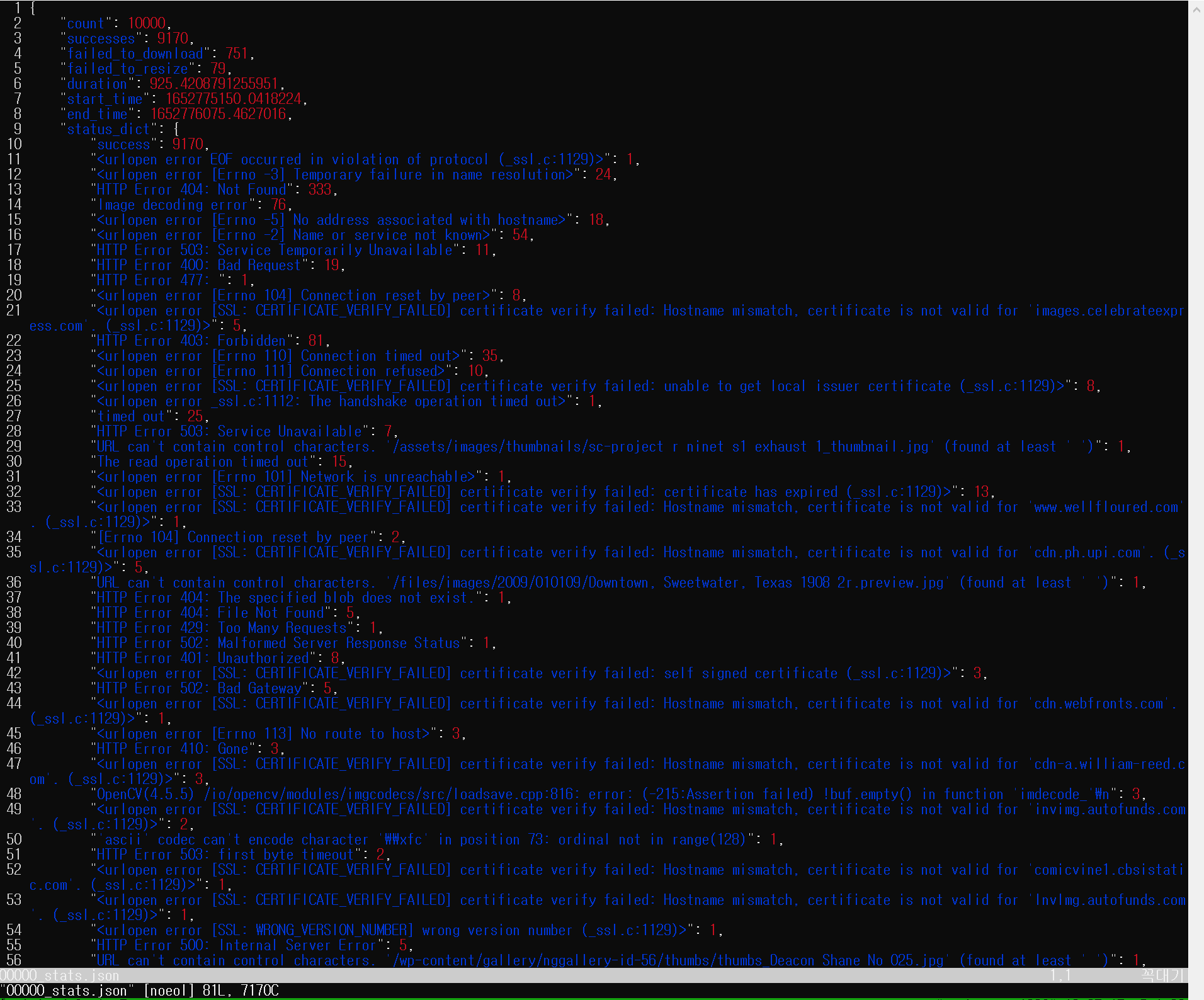
- JSON 파일은 다운로드 과정의 로그와 전체 데이터셋 개요를 보여줍니다. 메타데이터에 있는 URL에서 이미지를 다운 받을 때 url이 더이상 유효하지 않거나, resizing에 실패했다는 기록이 남아 있습니다.
- parquet 파일은 메타데이터와 마찬가지로 전체 내용을 column을 가진 Relational database와 같은 형식으로 갖고 있습니다. parquet-tools 도구를 설치하여 내용을 확인할 수 있습니다.pip install parquet-tools parquet-tools inspect _.parquet #전체 개수와 column 정보 리턴 parquet-tools show --head 5 _.parquet #parquet 파일의 첫 5줄만 확인 -
tar 파일 안에는 실제로 학습에 사용하기 위한 image와 caption text, 그리고 메타정보를 담은 json 파일이 들어 있습니다.

- 다운받은 이미지 jpg 파일
- 다운받은 캡션 텍스트 txt 파일
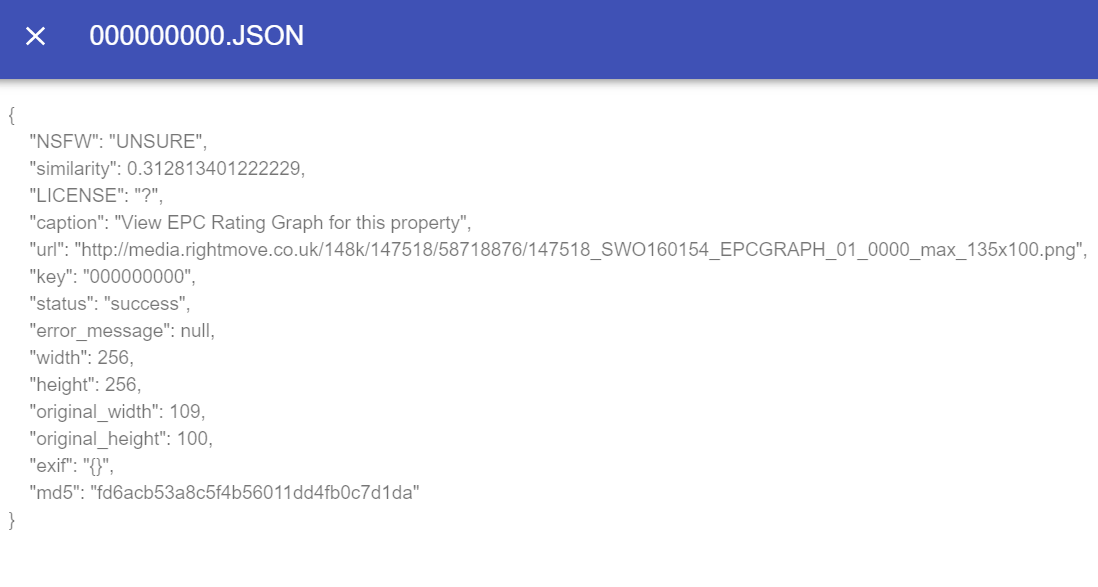
- 다운로드된 데이터에 대한 메타 정보 JSON
이제 다운받은 대용량의 메타데이터와 image, caption text 정보를 통해 딥러닝 모델을 학습하면 됩니다.
parquet 파일에는 unsafe tag, watermark tag, cosine similarity 등의 정보가 있으므로 일부 정보만 필요할 경우 이를 통해 파일을 필터링하여 사용할 수 있습니다.
