데이터 기본 정보 확인: DataFrame의 기본적인 정보를 확인하고, 결측값이 없는지 info 함수를 통해 점검.
통계 정보 요약: describe 함수를 사용하여 상영 시간과 평점 등 숫자 데이터의 기본 통계 정보를 확인.
그룹별 통계 분석: groupby 함수를 이용해 장르별로 데이터 그룹을 나누고, .count(), .size(), .min(), .max(), .mean(), .sum() 등을 통해 통계 정보를 세부적으로 분석.
특정 컬럼에 대한 분석: groupby의 결과에서 특정 컬럼(e.g., score)에 대해서만 통계 정보를 확인하는 방법.
데이터 타입별 연산 처리: 문자 데이터와 숫자 데이터를 구분하여 적합한 연산을 수행하고, numeric_only 파라미터를 활용하여 숫자 데이터만 대상으로 통계 분석을 수행.
import pandas as pd
netflix_df = pd.read_csv('data/netflix.csv')
netflix_df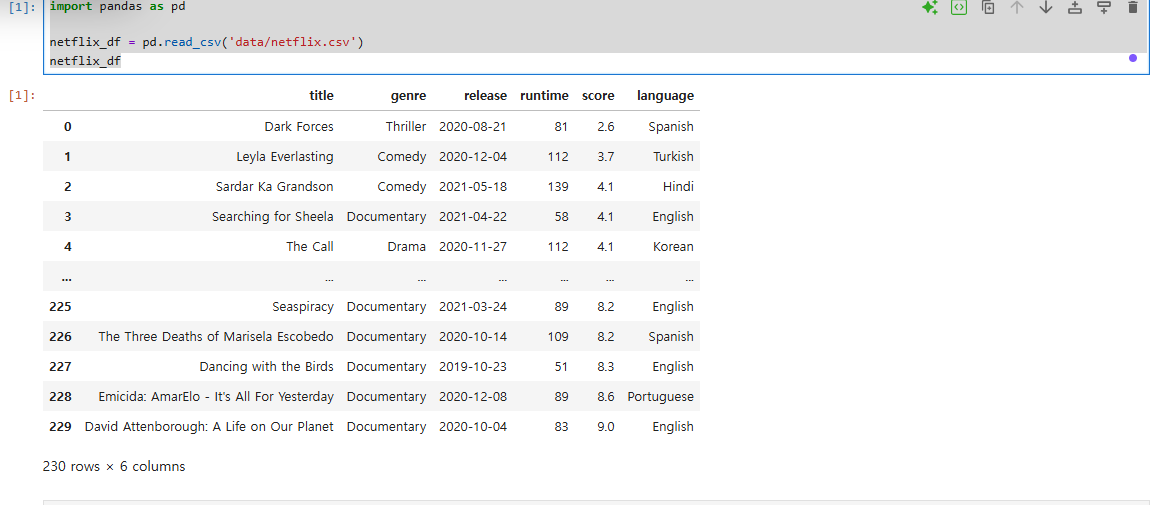
#장르별로 그룹을 묶어보겠다
netflix_df.groupby('genre')
netflix_df.groupby('genre').count()
netflix_df.groupby('genre').size()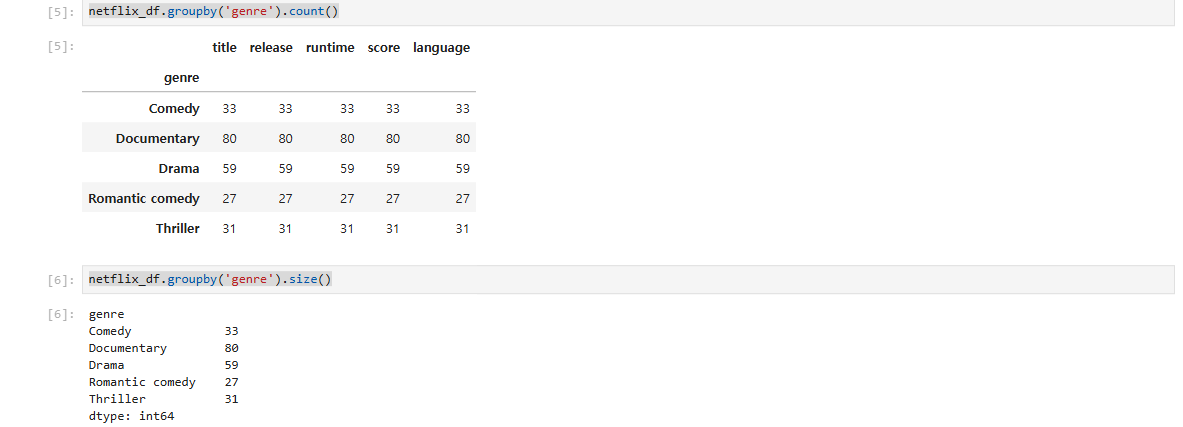
netflix_df.groupby('genre').min()
#숫자 데이터만 대상
netflix_df.groupby('genre').min(numeric_only =True)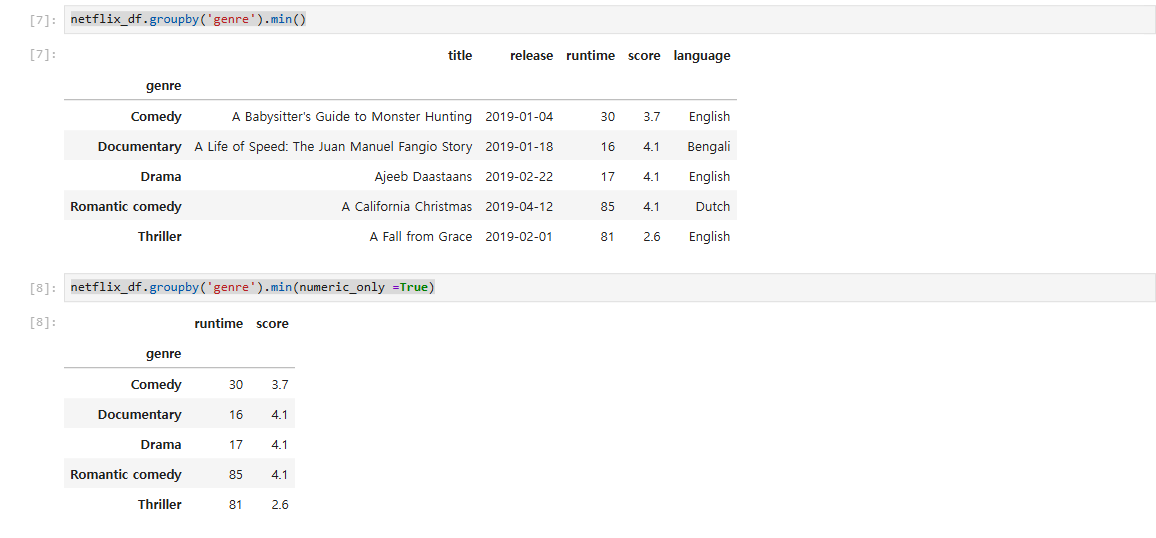
netflix_df.groupby('genre').max(numeric_only =True) # 최대값
netflix_df.groupby('genre').mean(numeric_only =True) #평균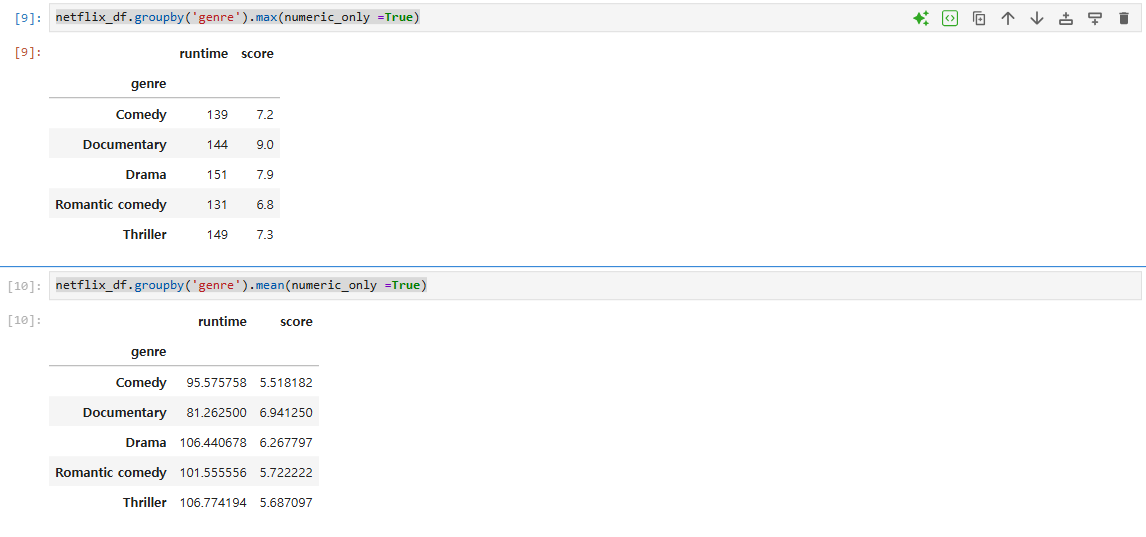
#score컬럼에 대해서만 조회하겠다.
netflix_df.groupby('genre')['score'].mean()
#조회 컬럼을 지정하겠다.
netflix_df.groupby('genre')[['score','runtime']].mean() #list형태로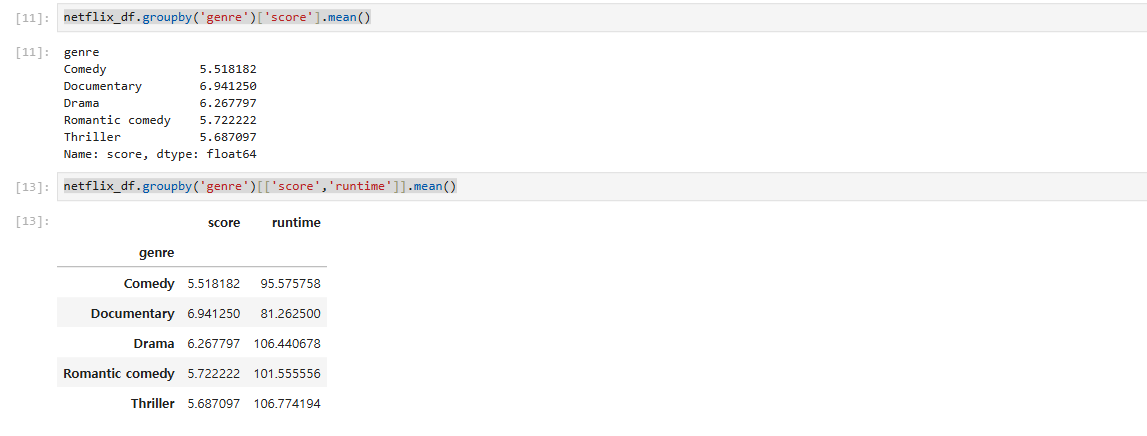

개발자