pandas의 category 타입은 범주형 데이터를 더 효율적으로 관리하며, 특히 각 범주에 순서를 지정할 수 있는 기능을 통해 데이터 정렬 및 시각화에서 유용하게 활용할 수 있다.
category 타입 개요: 범주형 데이터를 나타내는 pandas 데이터 타입으로, 메모리 사용량 절감과 범주별 순서 지정 가능.
범주형 데이터 예시: 옷 사이즈, 혈액형, 연령대 등 제한된 범위의 값으로 이루어진 데이터.
순서 지정의 필요성: 기본적으로 텍스트는 object 타입이며, 알파벳 순으로 정렬되지만, category 타입을 사용하면 원하는 순서로 정렬 가능.
Categorical() 함수 사용법: 데이터와 원하는 범주 순서를 제공하여 category 타입으로 변환.
데이터 분석 및 시각화의 향상: category 타입을 활용해 정렬과 그룹핑 기준이 달라져, 결과물을 더욱 직관적이고 명확하게 해준다.
import pandas as pd
import seaborn as sns
clothes_df = pd.DataFrame({
'size': ['L', 'S', 'XS', 'L', 'S', 'XL', 'L', 'S', 'M', 'XS',
'M', 'M', 'XS', 'L', 'XL', 'XS', 'M', 'S', 'L', 'XL'],
'sales': [130, 200, 120, 120, 140, 160, 190, 90, 110, 100,
150, 180, 100, 200, 80, 140, 150, 90, 80, 130]
})
clothes_df
clothes_df.groupby('size').mean()
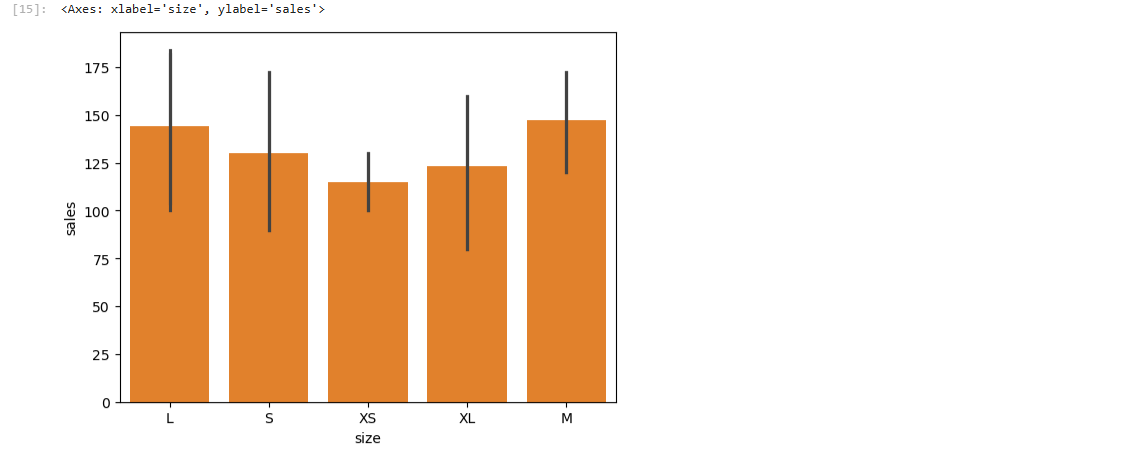
sns.barplot(data=clothes_df, x='size', y='sales')
---------------------------------------------------------------------------
pd.Categorical(clothes_df['size'], ordered=True, categories=['XS', 'S', 'M', 'L', 'XL'])
clothes_df['size'] = pd.Categorical(
clothes_df['size'],
ordered=True,
categories=['XS', 'S', 'M', 'L', 'XL']
)
clothes_df.sort_values(by='size')
clothes_df.groupby('size').mean()
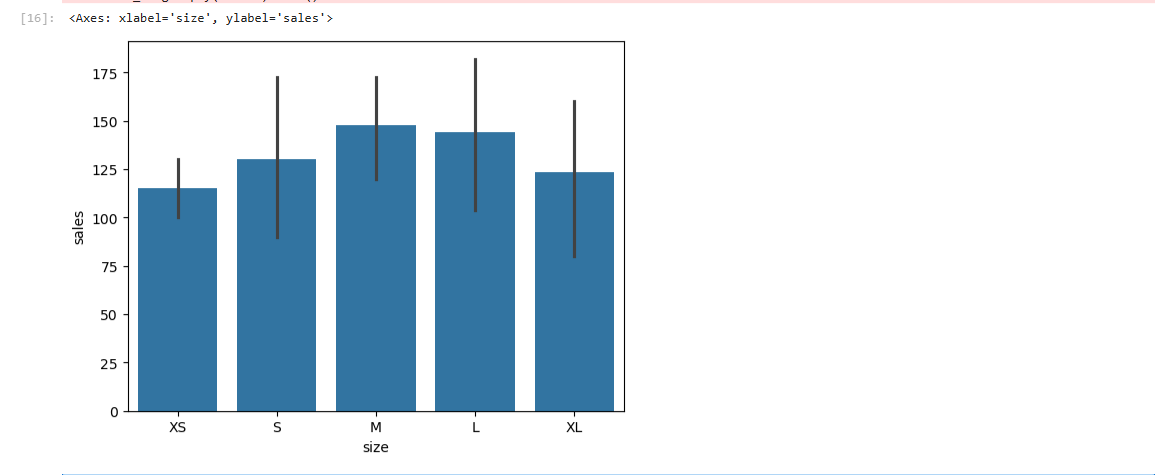
sns.barplot(data=clothes_df, x='size', y='sales')
- Categorical 사용 전
- Categorical 사용 후

개발자