Python의 Pandas 라이브러리를 사용하여 데이터 프레임을 그룹화(grouby)하고 멀티 인덱스를 활용하여 데이터를 확인하고 인덱싱하는 방법
Groupby 함수 소개 및 활용: Pandas의 groupby 함수를 사용하는 방법을 배우고, 장르 및 연도 정보를 기준으로 데이터를 그룹화하는 방법을 알아봅니다.
Datetime을 활용한 연도 추출: release 컬럼을 datetime 타입으로 변환하고, 연도 정보를 추출하여 새로운 컬럼을 생성하는 과정을 설명합니다.
멀티 인덱스 생성: 복수의 컬럼을 기준으로 groupby를 사용할 때, 멀티 인덱스가 생성되는 과정을 보여주고, 컬럼의 순서에 따라 멀티 인덱스가 달라지는 점을 설명합니다.
멀티 인덱스를 활용한 데이터 접근: 멀티 인덱스 구조에서 데이터를 필터링하고 인덱싱하는 다양한 방법을 실습합니다. 단일 인덱스와 여러 인덱스 값을 동시에 사용하는 방법을 배우게 됩니다.
정렬 및 전체 값 추출: 인덱스 값을 정렬하고, 특정 인덱스 값을 상징적으로 표현하여 관련 데이터를 한꺼번에 추출하는 방법을 알아봅니다.
import pandas as pd
netflix_df = pd.read_csv('data/netflix.csv')
#년도 추출 전 데이터 타입으로 변경해서 year라는 새 컬럼에 저장. **dt 필수. 미 기입 시 오류.**
netflix_df['year'] = pd.to_datetime(netflix_df['release']).dt.year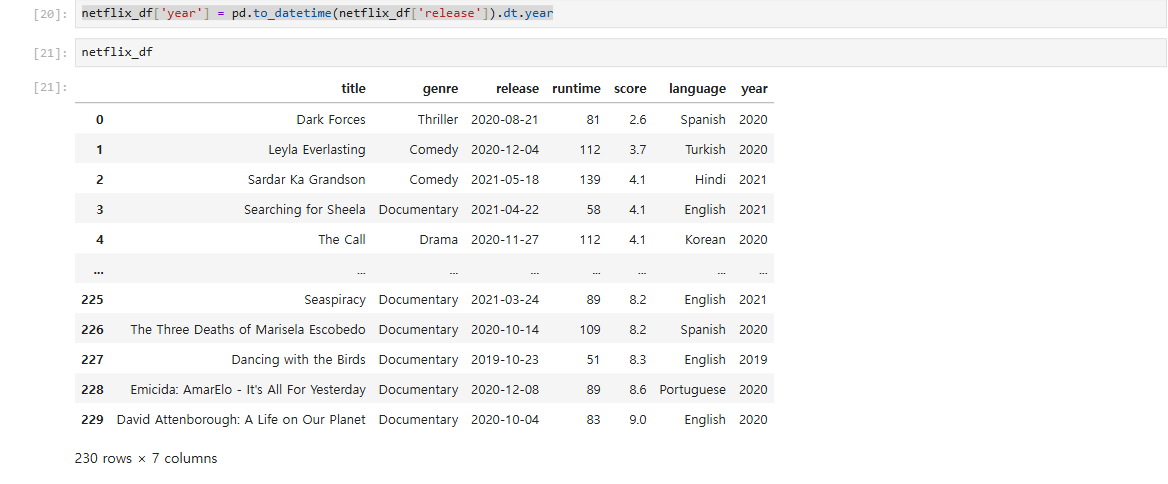
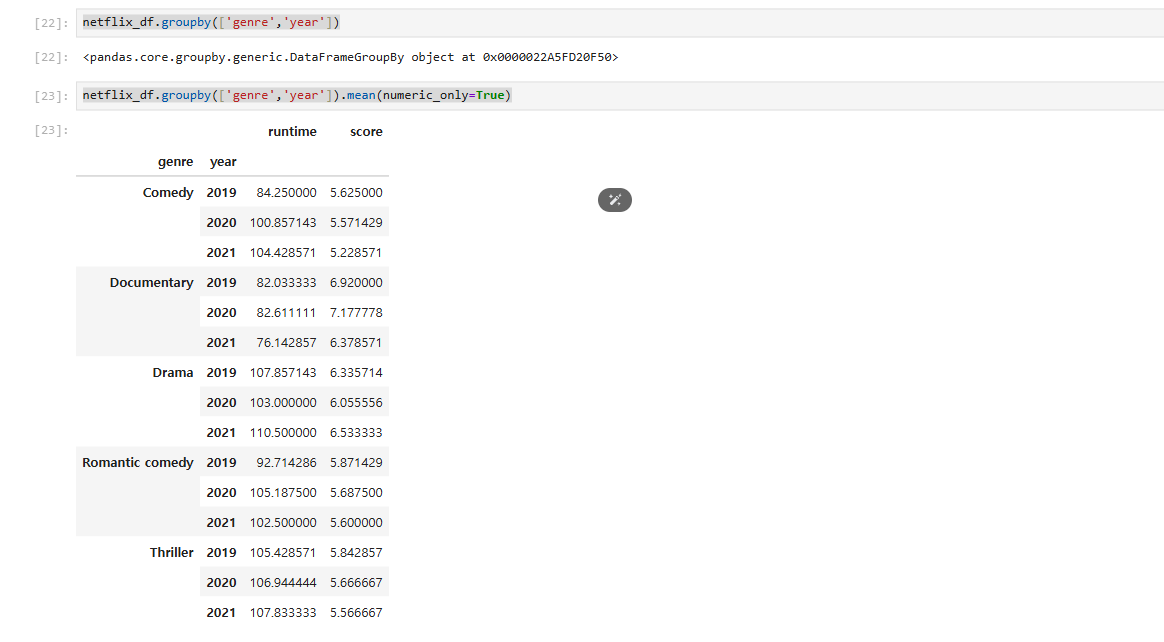
#'genre','year' 기준 그룹으로 묶음.
netflix_df.groupby(['genre','year'])
#평균
netflix_df.groupby(['genre','year']).mean(numeric_only=True)
netflix_df.groupby(['year','genre']).mean(numeric_only=True)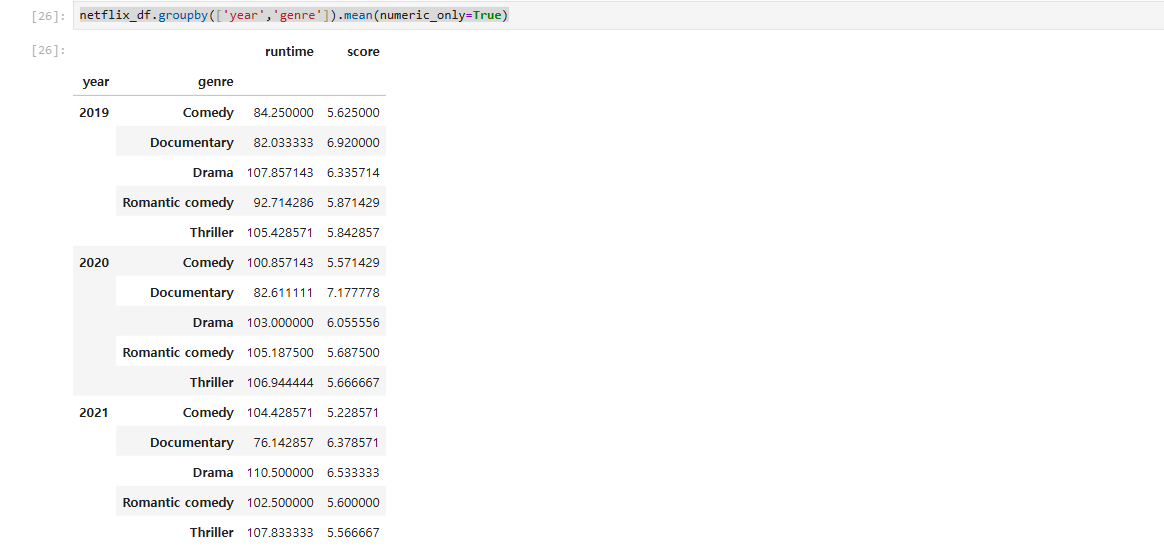
#특정년도만
netflix_df.groupby(['year','genre']).mean(numeric_only=True).loc[2020]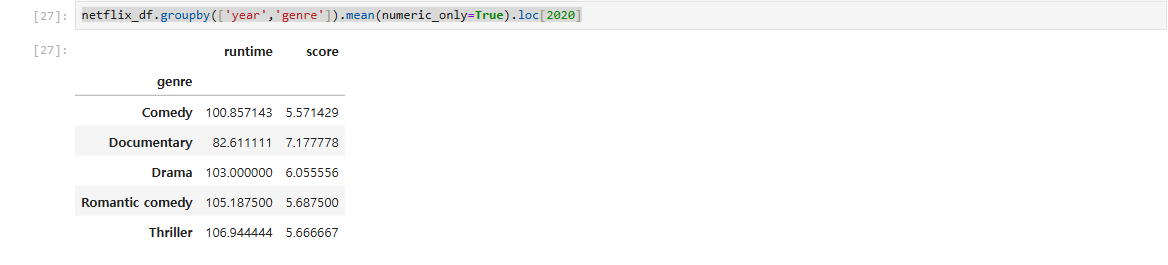
netflix_df.groupby(['year','genre']).mean(numeric_only=True).loc[(2020,'Drama')]
netflix_df.groupby(['year','genre']).mean(numeric_only=True).loc[(2020,['Drama','Comedy'])] # 이렇게 작성하면 에러발생. index와 컬럼을 구분할 : 를 추가해야 함.
netflix_df.groupby(['year','genre']).mean(numeric_only=True).loc[(2020,['Drama','Comedy']), :]
#년도별로 구분하고 싶을때
years = sorted(netflix_df['year'].unique())
netflix_df.groupby(['year','genre']).mean(numeric_only=True).loc[(years,['Drama','Comedy']), :]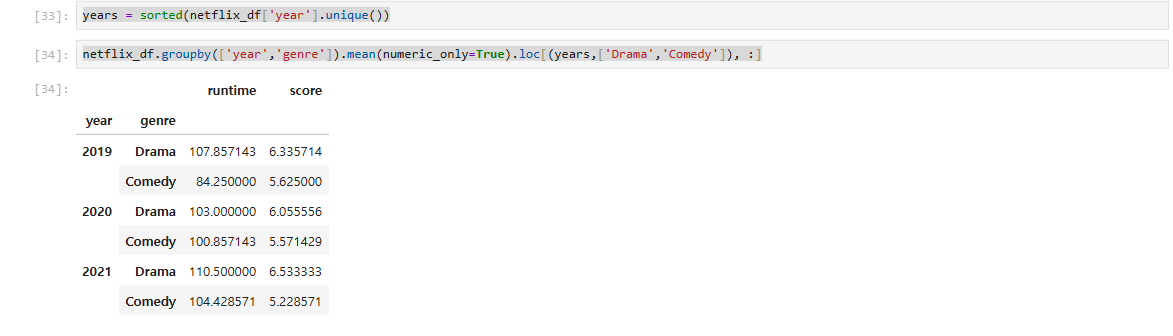
- 키와 체중의 평균을 운동 종목별, 성별 기준으로 계산
import pandas as p
olympic_df = pd.read_csv('data/olympic.csv')
olympic_df.groupby(['sport', 'sex'])[['height', 'weight']].mean()
개발자