- 날짜와 시간 데이터의 중요성: 데이터 분석에서는 날짜와 시간 정보를 포함한 데이터를 자주 다루며, 이를 효과적으로 처리하기 위해 적절한 데이터 타입이 필요.
- datetime 타입으로 변환: Pandas의 to_datetime 함수를 사용하여 문자열로 저장된 날짜와 시간 데이터를 datetime 타입으로 변환.
- Timestamp와 datetime 차이: Timestamp는 특정 시점의 날짜와 시간을 표현하며, 여러 Timestamp로 이루어진 Series의 데이터 타입은 datetime.
- 데이터 불러오기 시 datetime 지정: 데이터를 불러올 때 parse_dates 파라미터를 사용하여 특정 컬럼을 미리 datetime 타입으로 지정할 수 있다.
- 날짜 정보 추출 및 활용: datetime으로 변환된 데이터를 통해 간단하게 연도, 월, 일, 시간 등의 특정 정보를 추출하고, .dt 속성을 사용해 요일 같은 유용한 정보도 얻을 수 있다.
- 데이터 로드 후 날짜 타입으로 변경
import pandas as pd
order_df = pd.read_csv('data/order.csv')
order_df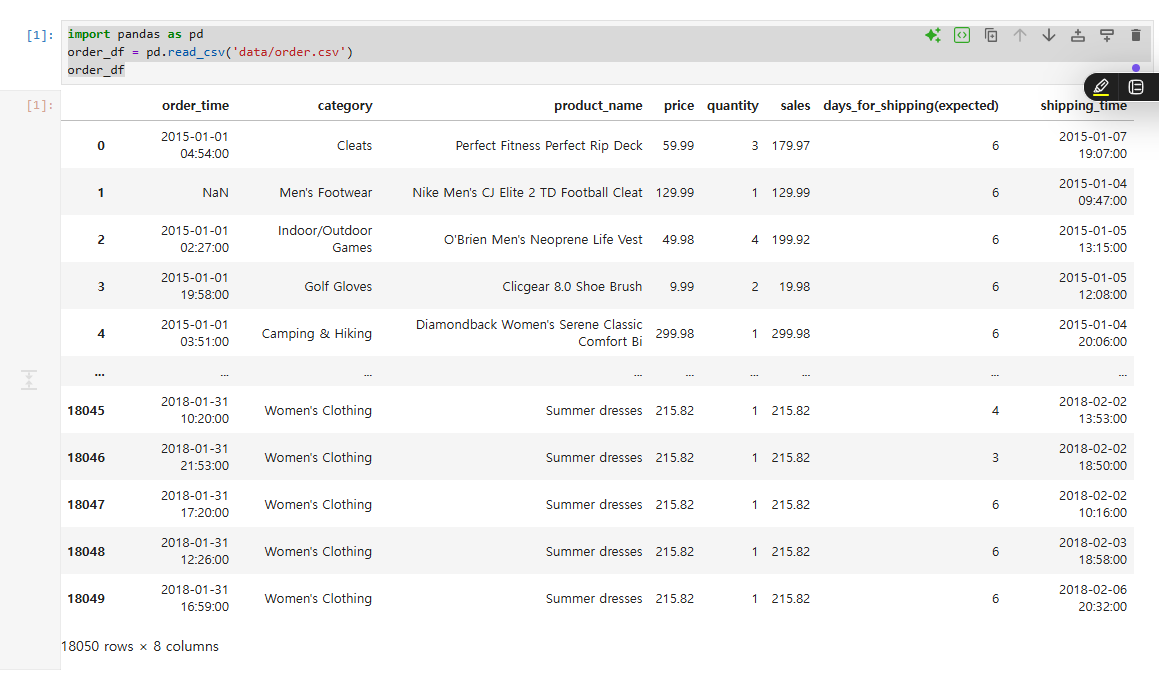
order_df.dtypes
pd.to_datetime(order_df['order_time'])
pd.to_datetime(order_df['order_time'])[0]
order_df['order_time'] = pd.to_datetime(order_df['order_time'])
order_df['shipping_time'] = pd.to_datetime(order_df['shipping_time'])
order_df.dtypes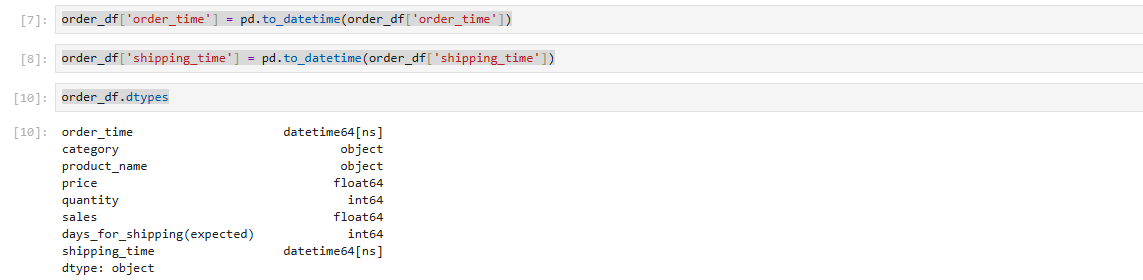
*처음과 비교했을 때 order_time 과 shipping_time 의 데이터 타입이 object -> datetime64[ns] 로 변경되었음을 확인할 수 있다. 여기서 ns는 nanoseconds 임.
- 초기에 데이터 로드 시점에 날짜 데이터로 지정.
order_df = pd.read_csv('data/order.csv', parse_dates=['order_time', 'shipping_time'])
order_df.dtypes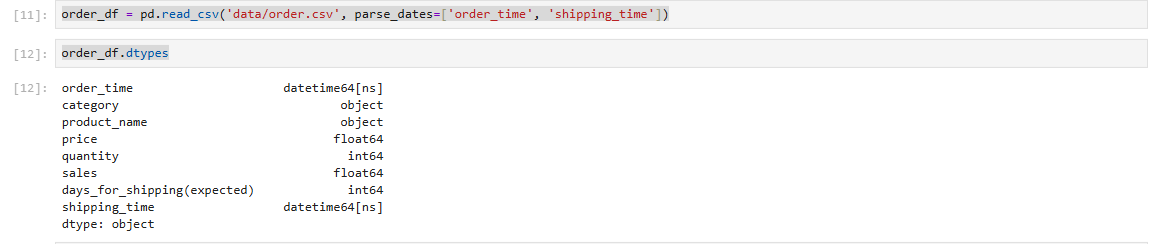
날짜 데이터 중 NaT는 날짜 타입의 결측값
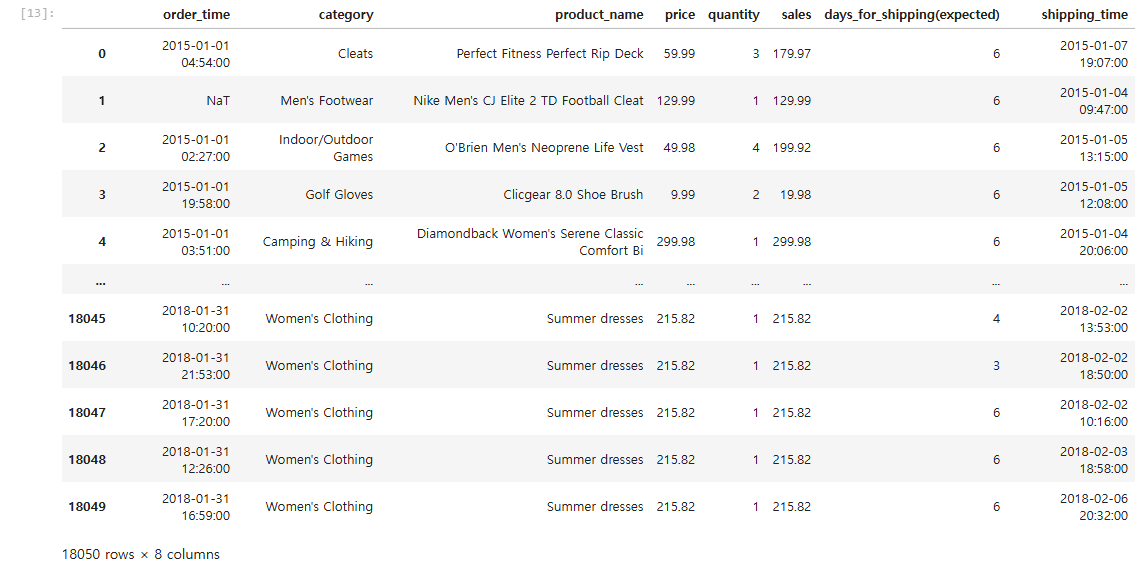
- 결측값 제거
#isna().sum()로 컬럼별로 결측값이 몇개인지 확인 후 dropna()로 결측값이 있는 row제거
order_df.isna().sum()
order_df = order_df.dropna()
order_df.isna().sum()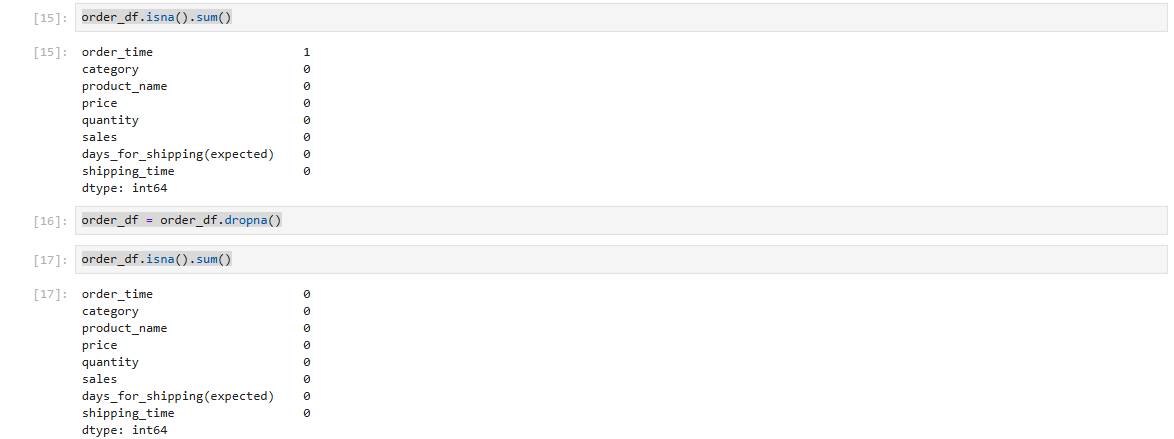
#날짜 타입 데이터 가공
order_df['order_time'].dt.date
order_df['order_time'].dt.year
order_df['order_time'].dt.month
order_df['order_time'].dt.day
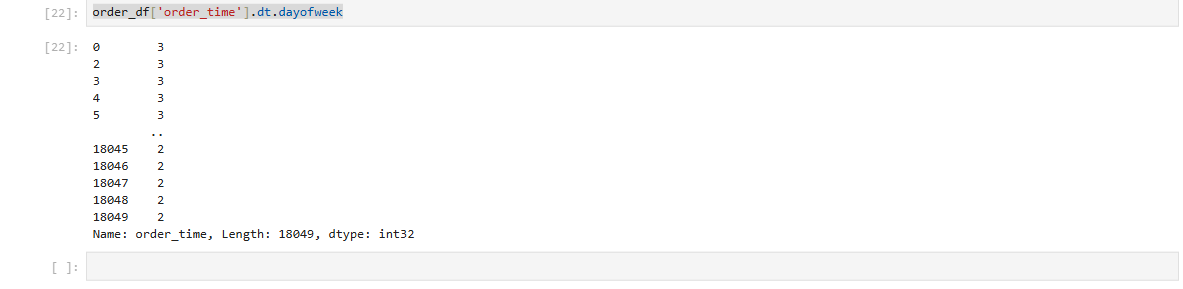
order_df['order_time'].dt.dayofweek #요일 0~6까지의 값이고 0이 월요일 6이 일요일.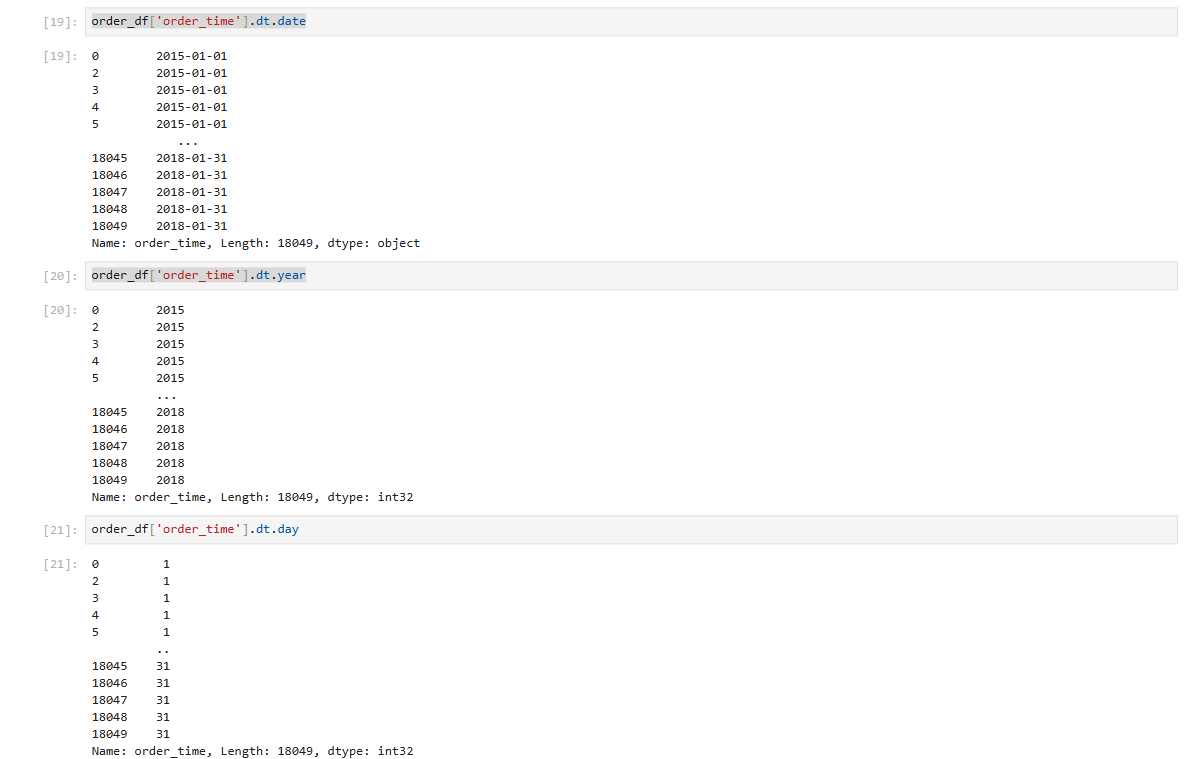
-
날짜 형식 지정하여 데이터 불러오기
read_csv() 사용 시 parse_dates 파라미터를 통해 다양한 날짜 형식의 데이터를 datetime으로 변환할 수 있다.
dayfirst 파라미터를 사용해 일/월/연도 형식을 인식할 수 있도록 설정할 수 있으며, 명확하지 않은 경우에도 명확한 파라미터 설정을 추천. -
데이터 타입 변환 시 형식 지정
to_datetime() 함수를 사용하여 다양한 형태의 문자열 데이터를 datetime으로 변환 가능하며, yearfirst 및 format 파라미터 사용으로 세부 형식을 지정할 수 있다. -
datetime 포맷 지정하여 문자열로 변환
strftime() 함수를 통해 datetime 객체를 원하는 형식의 문자열로 변환할 수 있음. 이 과정에서 다양한 시간 표현 코드를 사용할 수 있음. -
시간대 설정 및 변환
tz_localize() 함수를 사용해 특정 지역의 시간대 정보를 추가할 수 있으며, tz_convert()를 통해 이미 설정된 시간대를 다른 시간대로 변환 가능. pytz 모듈을 사용하여 다양한 시간대 정보를 확인 가능. -
유용한 파라미터 및 함수들
parse_dates, dayfirst, yearfirst, format, strftime, tz_localize, tz_convert 등 다양한 파라미터와 함수를 활용하여 다양한 날짜 및 시간 데이터를 효과적으로 다룰 수 있다.
import pandas as pd
order_df = pd.read_csv('data/order.csv')
order_df.head()order_time과 shipping_time 컬럼에 날짜와 시간 값이 들어 있는데, 두 컬럼 모두 날짜가 연도-월-일 형태로 되어 있다. 이게 바로 pandas datetime의 기본 형식이라고 할 수 있다. 그래서 아래와 같이 read_csv()의 parse_dates 파라미터에 두 컬럼의 값을 넘겨주면, pandas는 문제 없이 두 컬럼의 타입을 datetime으로 불러올 수 있다.
order_df = pd.read_csv('data/order.csv', parse_dates=['order_time', 'shipping_time'])order_df = pd.read_csv('data/order1.csv')
order_df.head()
위 코드를 조회해 보면 이전 데이터와 다르게 년/월/일 형식으로 출력되는데 이런 경우에도 read_csv()로 데이터를 불러올 때 parse_dates에 order_time과 shipping_time을 넘겨주면 pandas가 알아서 값을 인식해서 데이터를 불러온다
order_df = pd.read_csv('data/order1.csv', parse_dates=['order_time', 'shipping_time'])
order_df.head()월/일/년 형식도 parse_date 옵션을 사용하면 년-월-일 형태로 변경되어 출력된다.
order_df = pd.read_csv('data/order2.csv', parse_dates=['order_time', 'shipping_time'])
order_df.head()일/월/연도 형식의 데이터는 dayfirst라는 파라미터를 True로 설정하면 된다. 이건 말 그대로 일자 값이 앞에 온다는 것을 의미하는데 원래 기본값은 False로 되어 있어서, 따로 설정해 주지 않으면 월/일/연도 순서로 값을 인식하게 된다.
따로 이 파라미터를 설정하지 않아도 20/01/2015 이런 식으로 가장 앞에 있는 값이 월이 아니라 일이라는 것이 명확하면 pandas가 알아서 일/월/연도 형식으로 판단하여 데이터를 불러오기는 한다 왜냐하면 20이라는 월은 존재하지 않기 때문. 하지만, 10/01/2015처럼 월/일/연도인지, 일/월/연도인지 명확하지 않은 경우도 많기 때문에 따로 파라미터 값을 명확하게 설정해 주는 것이 좋다.
order_df = pd.read_csv('data/order3.csv', parse_dates=['order_time', 'shipping_time'], dayfirst=True)
order_df.head()년이 두자리인 경우 아래 코드와 같이 to_datetime()에서 yearfirst라는 파라미터 값을 True로 설정.
order_df['order_time'] = pd.to_datetime(order_df['order_time'], yearfirst=True)
order_df['shipping_time'] = pd.to_datetime(order_df['shipping_time'], yearfirst=True)
order_df.head()dayfirst와 yearfirst가 모두 True인 경우에는 yearfirst에 더 우선순위를 둔다고 합니다. 즉, 연도/일/월 순서.
to_datetime사용 시 오류가 발생하는 경우 데이터 형식에 맞게 날짜와 시간을 표현하는 문자열을 만들어서 format이라는 파라미터에 넘겨줘야 함.
%Y는 연도(4자리), %m은 월(2자리), %d는 일(2자리), %H는 시간(24시간 기준), %M은 분, %S는 초를 의미
order_df['order_time'] = pd.to_datetime(order_df['order_time'], format='%Y년 %m월 %d일 %H시 %M분 %S초')
order_df['shipping_time'] = pd.to_datetime(order_df['shipping_time'], format='%Y년 %m월 %d일 %H시 %M분 %S초')
order_df.head()datetime 값을 원하는 형태의 문자열로 바꿔서 표현하는 것도 가능.
order_df['order_time'] = order_df['order_time'].dt.strftime('%d %b %Y, %I:%M %p')
order_df['shipping_time'] = order_df['shipping_time'].dt.strftime('%d %b %Y, %I:%M %p')
order_df.head() strftime() 함수는 날짜와 시간을 원하는 형식으로 표현하는 역할.여기서 주의할 점은 datetime과 strftime() 사이에 dt를 써서 이 함수가 날짜와 시간 정보에 접근할 수 있도록 해 줘야 한다.그리고 이 함수 안에는 문자열로 원하는 형식을 넣으면 되고, 이때 날짜와 시간과 관련된 코드 값을 활용하면 됨.
%d는 일자, %B는 영어로 된 월 이름, %Y는 연도(4자리), %I는 시간(12시간 기준), %M은 분, 마지막으로 %p는 오전/오후(AM/PM).
- 시간대 설정하기
order_df = pd.read_csv('data/order1.csv', parse_dates=['order_time', 'shipping_time'])
order_df.head()order_df['order_time'].dt.tz_localize('Asia/Seoul')
0 2015-01-20 21:52:00+09:00
1 2015-02-07 22:53:00+09:00
2 2015-02-08 13:15:00+09:00
3 2015-02-24 03:25:00+09:00
4 2015-03-09 03:56:00+09:00
...
95 2017-09-13 21:23:00+09:00
96 2017-10-11 14:20:00+09:00
97 2017-10-19 15:23:00+09:00
98 2018-01-01 04:04:00+09:00
99 2018-01-18 15:47:00+09:00
Name: order_time, Length: 100, dtype: datetime64[ns, Asia/Seoul]
결과를 보면, 시간 뒤에 +09:00이라는 값이 추가되고 아래 dtype 부분에도 Asia/Seoul이 추가되어 있는 걸 확인할 수 있다. 여기서 +09:00은 UTC(Coordinated Universal Time)이라는 국제 표준시를 사용해서 서울의 시간대를 표현하는 방법. 간단히 설명하자면, UTC는 영국의 그리니치 천문대를 기준점(UTC+0)으로 삼아 각 지역의 상대적인 시간대를 표현하는 방식. 예를 들어, UTC+3는 UTC+0보다 3시간 빠르다는 걸 의미하고, UTC-5는 UTC+0보다 5시간 느리다는 걸 의미. 지금 나와있는 +09:00은 UCT+9라고 보면 되고, 즉 Asia/Seoul 시간대는 UTC+0에 비해 9시간 더 빠른 시간대라고 할 수 있다.
order_df['order_time'] = order_df['order_time'].dt.tz_localize('Asia/Seoul')
order_df['shipping_time'] = order_df['shipping_time'].dt.tz_localize('Asia/Seoul')이미 설정해 둔 것을 수정할 경우
order_df['order_time'].dt.tz_convert('America/New_York')
0 2015-01-20 07:52:00-05:00
1 2015-02-07 08:53:00-05:00
2 2015-02-07 23:15:00-05:00
3 2015-02-23 13:25:00-05:00
4 2015-03-08 14:56:00-04:00
...
95 2017-09-13 08:23:00-04:00
96 2017-10-11 01:20:00-04:00
97 2017-10-19 02:23:00-04:00
98 2017-12-31 14:04:00-05:00
99 2018-01-18 01:47:00-05:00
Name: order_time, Length: 100, dtype: datetime64[ns, America/New_York]이때 주의할 점은 아직 시간대가 설정되어 있지 않은 상태의 datetime에 바로 tz_convert()를 쓰면 오류가 발생. tz_convert()는 반드시 시간대가 설정되어 있는 데이터에만 사용 가능. 반대로, 이미 시간대가 설정되어 있는 데이터에 tz_localize()를 써도 오류발생. 간단히 정리하자면, 아직 시간대 정보가 없는 데이터에는 tz_localize()를, 이미 시간대가 설정되어 있는 데이터의 시간대를 바꿀 때에는 tz_convert()를 사용하면 됨.
지금은 서울과 뉴욕의 시간대 정보를 사용했는데, 다른 시간대를 설정하려면 아래 코드를 실행하면, 두 함수에 사용 가능한 모든 시간대 값들이 나오니까 참고.
import pytz
for tz in pytz.all_timezones:
print(tz)
