- CSV 파일로 내보내기
to_csv() 함수를 사용하여 DataFrame을 CSV 파일로 저장할 수 있습니다.
기본적으로 인덱스 값은 컬럼으로 저장됩니다.index라는 파라미터 값의 기본값이 True로 되어 있기 때문.
index 파라미터를 False로 설정하면 인덱스를 제외한 데이터만 저장할 수 있습니다.
loan_df.to_csv('data/loan1.csv')
loan_df1.to_csv('data/loan2.csv')
loan_df1.to_csv('data/loan2.csv', index=False) # DataFrame에서 인덱스는 제외- CSV 파일 불러오기
read_csv() 함수를 사용하여 CSV 파일을 DataFrame으로 다시 불러올 수 있습니다.
인덱스에 따라 불필요한 컬럼이 추가될 수 있습니다.
인덱스에 있던 숫자값들이 컬럼으로 추가되었습니다. 인덱스에 따로 이름이 없었기 때문에 컬럼명은 Unnamed: 0 이런 식으로 설정.
loan_df1 = pd.read_csv('data/loan1.csv')
loan_df2 = pd.read_csv('data/loan2.csv')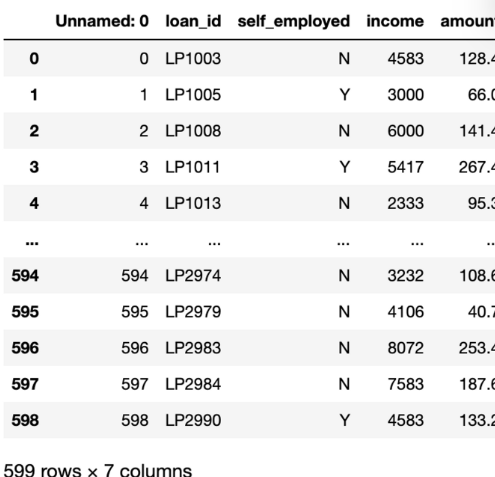
- 엑셀 파일로 내보내기
to_excel() 함수를 사용하면 DataFrame을 엑셀 파일로 저장할 수 있습니다.
기본적인 저장 옵션 외에도 시트 이름과 시작 위치(row, column)를 설정할 수 있습니다.
loan_df1.to_excel('data/loan1.xlsx')
loan_df1.to_excel('data/loan1.xlsx', sheet_name='loan', startrow=1, startcol=1)sheet_name은 말 그대로 데이터가 저장된 시트 이름.
startrow는 데이터가 몇 번째 로우부터 기록될 건지, startcol은 몇 번째 컬럼부터 기록될 건지를 의미.두 파라미터의 기본값은 원래 0인데 두 값을 다 1로 주면 데이터가 컬럼과 로우 모두 한 줄씩 띄고 두 번째 줄부터 기록되도록 만들 수 있다.
- 엑셀 파일 내보내기 확장 옵션
sheet_name, startrow, startcol 파라미터를 사용하여 시트 이름과 저장 위치를 조정할 수 있습니다.

개발자