*중복
duplicated()는 중복되는 값들 중 첫번째 값은 중복이 아니라고 판단하고 그 다음 값 부터 중복이라고 판단함.
**airbnb_df.duplicated()** // 모든 데이터가 중복일때 중복되는 데이터에 True.중복되는 값들 중 첫번째는 False
**airbnb_df.duplicated().sum()** //중복값의 갯수
**airbnb_df[airbnb_df.duplicated()]** // 중복되는 열의 값만 보여줌
**airbnb_df[airbnb_df.duplicated(subset='id')]** // column중 id 값만 중복되는 값을 보여줌
**airbnb_df[airbnb_df.duplicated(subset=['id','n_reviews','price'])]** //id , price column이 중복되는 열을 보여줌.
**airbnb_df[airbnb_df.duplicated(subset='id', keep='first')]** // keep의 기본값은 first. 중복값중 첫번째 값을 False로 한다.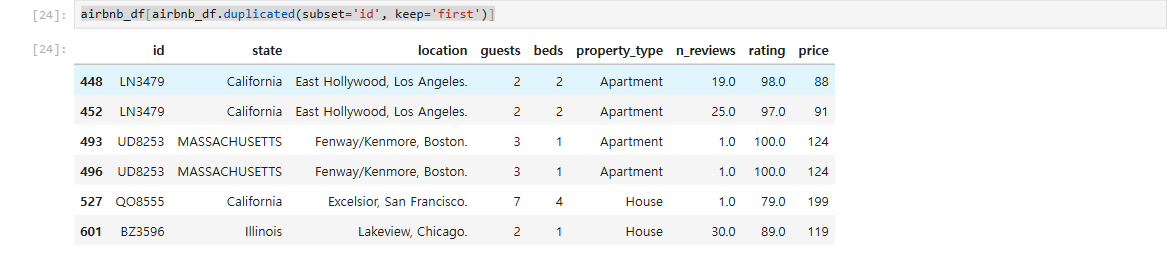
**airbnb_df[airbnb_df.duplicated(subset='id', keep='last')]**//중복값중 마지막 값을 False로 한다.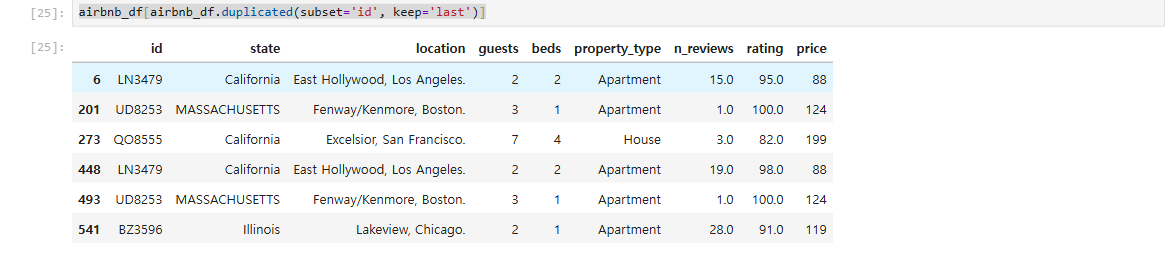
**airbnb_df[airbnb_df.duplicated(subset='id', keep=False)]**// 어느 컬럼이든 겹치는 값은 모두 보여준다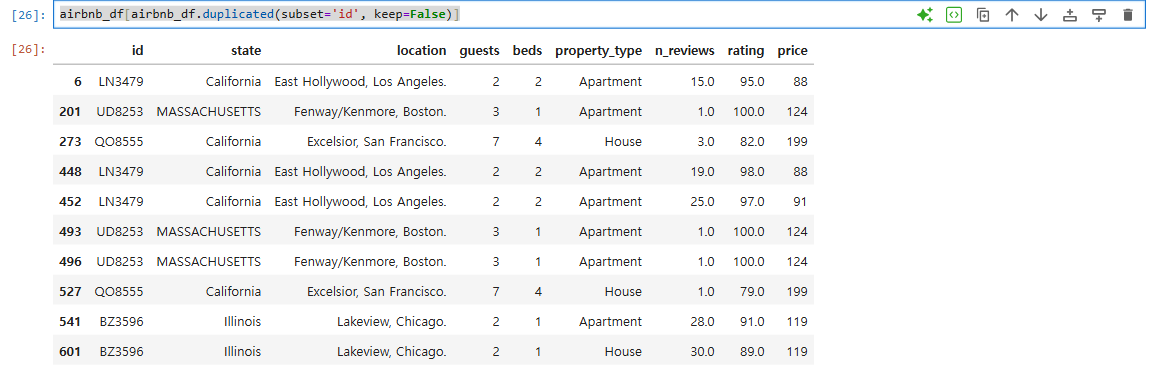
*중복 삭제
데이터프레임에서 중복값을 식별하고 제거하는 데 사용되는 Pandas 함수인 drop_duplicates
핵심 주제
데이터프레임에서 중복값을 식별하고 제거하는 데 사용되는 Pandas 함수인 drop_duplicates의 기능과 사용 방법에 대해 설명한다.
- 중복값 삭제의 필요성: 데이터프레임에서 중복값이 있을 때 일반적으로 하나의 값만 남긴다.
- drop_duplicates 함수 사용: 중복값을 삭제할 때 drop_duplicates 함수를 사용하며, 기본적으로 모든 컬럼 값이 동일해야 중복으로 간주된다.
- subset 파라미터 활용: 특정 컬럼에 대해서만 중복값을 검토하고자 할 경우, subset 파라미터에 해당 컬럼명을 지정할 수 있다.
- keep 파라미터 설명: 중복값 중 남길 값을 결정하기 위해 keep 파라미터를 활용, 기본값은 'first'이며 'last'로 변경 가능하다.
- 데이터프레임 업데이트 필요: 중복값 제거 후에는 데이터프레임에 결과를 저장해서 업데이트해야 중복값이 사라진다.
**airbnb_df.drop_duplicates()** //삭제. 기본적으로 모든 컬럼 값이 동일해야 중복으로 간주된다.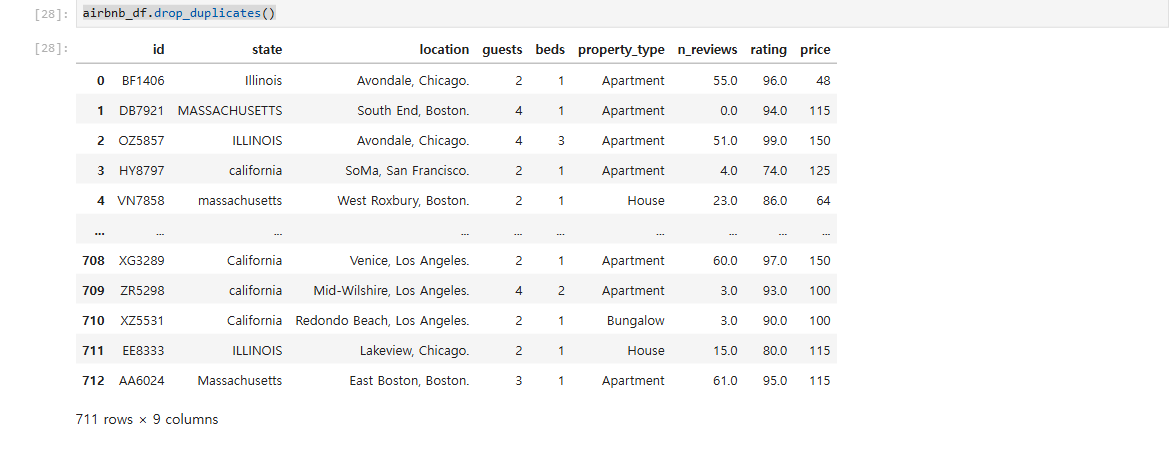

개발자