-
KDE Plot을 통한 데이터 분포 비교
두 개의 KDE Plot을 통해 고등학생 남학생들과 다양한 나이대의 남학생들의 키 데이터 분포를 비교한다.
파란색 그래프는 다양한 나이대의 남학생들로 인해 더 넓게 퍼져 있고, 주황색 그래프는 고등학생들만 포함하여 더 좁게 퍼져 있다.
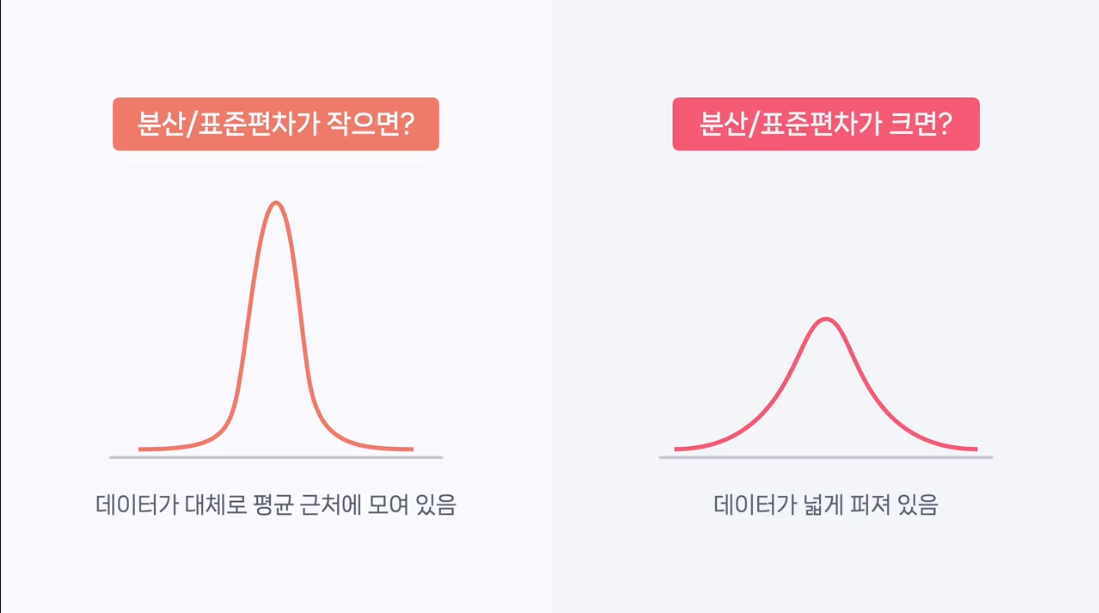
분산과 표준 편차의 개념과 중요성분산(Variance)과 표준 편차(Standard Deviation)는 데이터가 얼마나 넓게 퍼져 있는지를 나타내는 중요한 통계적 지표이다.
분산을 구하려면 각 데이터의 편차의 제곱을 평균 내고, 표준 편차는 이 값의 제곱근을 이용한다.
데이터의 편차 계산 방법데이터의 평균을 구하고, 각 값에서 평균을 빼서 편차를 구한다.
편차를 제곱하는 이유는 편차가 큰 값들을 더 부각시키기 위해서이다.
모집단과 표본에서의 분산 계산 차이모집단에서는 데이터 개수로 나누지만, 표본에서는 (데이터 개수 - 1)로 나누어 분산을 계산한다.
이는 표본이 모집단을 대표할 수 있도록 편차의 정도를 조정하기 위함이다.
Pandas와 Numpy의 분산/표준 편차 계산 차이Pandas는 기본적으로 n-1을 사용하여 계산하고, Numpy는 n을 사용한다.
두 방법 모두 데이터의 대략적인 특징을 파악하는 데 큰 차이는 없다.
*분산
df['height'].var()*표준편차
df['height'].std()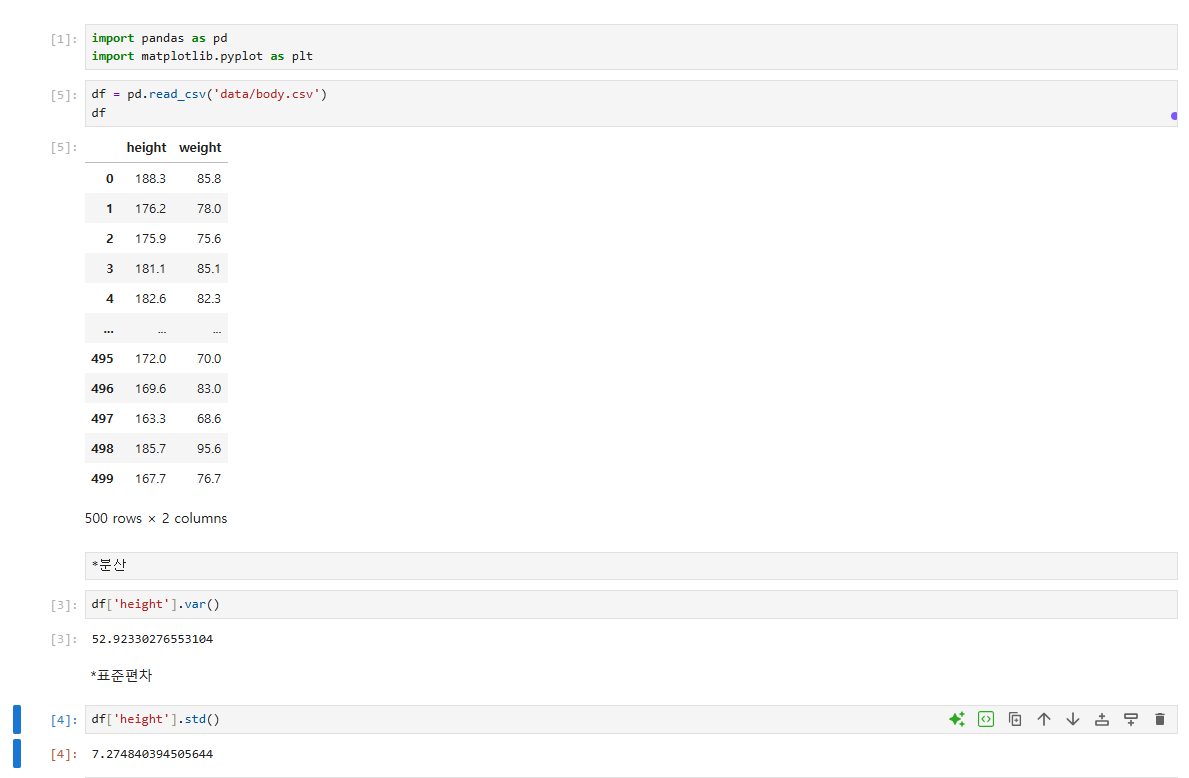
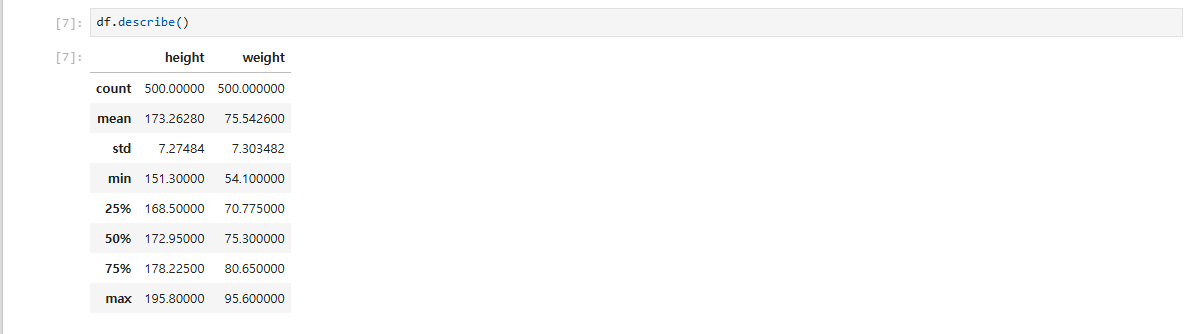

개발자