import pandas as pd
patient_df = pd.read_csv('data/patient.csv')
patient_df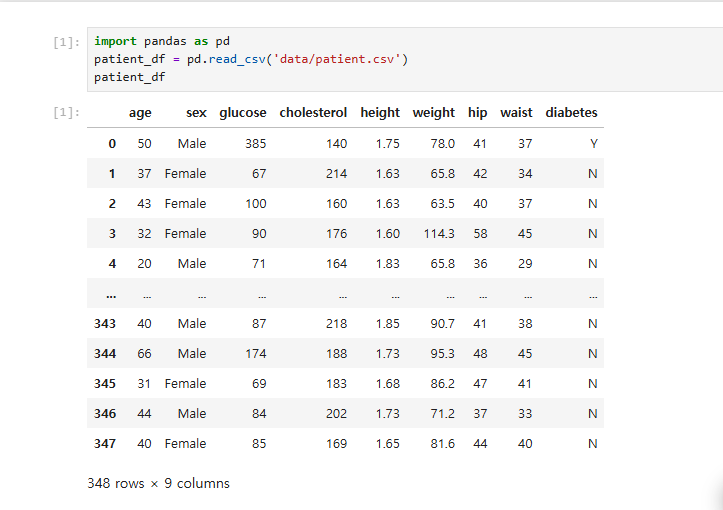
patient_df['waist'] / patient_df['hip']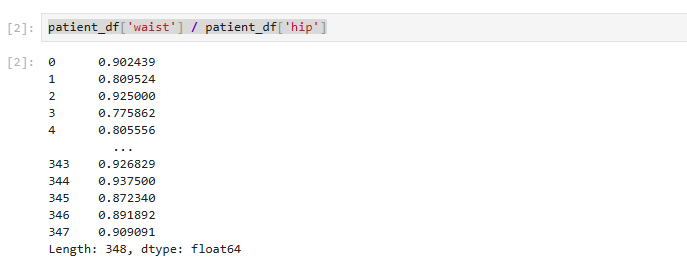
- round()
round(patient_df['waist'] / patient_df['hip'] , 2) #소수점 둘째 자리까지 반올림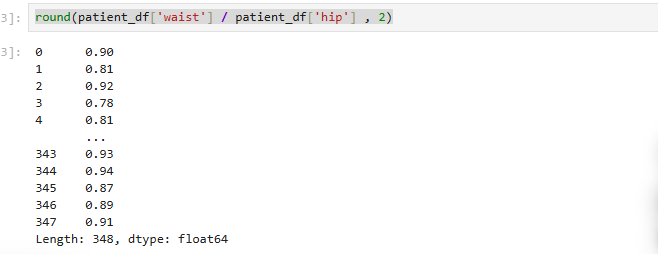
patient_df['waist_hip_ratio'] = round(patient_df['waist'] / patient_df['hip'] , 2)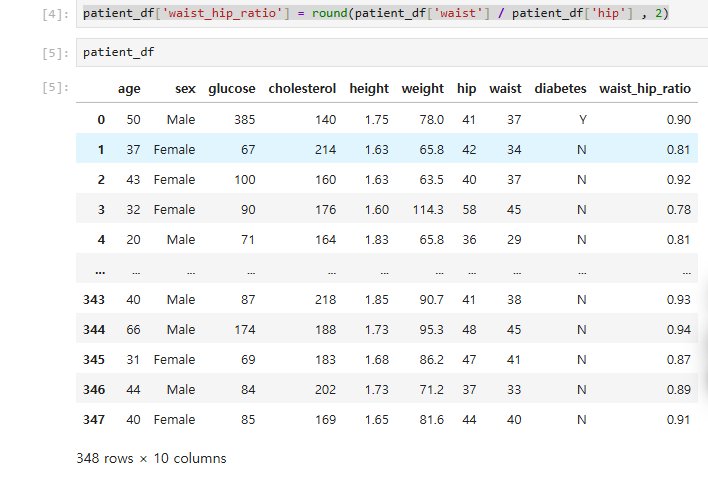
- 예제
import pandas as pd
patient_df = pd.read_csv('data/patient.csv')
#patient_df에 있는 각 환자의 BMI 값을 계산해서 bmi라는 컬럼에 저장.
#단, BMI 값은 소수 첫째 자리까지 반올림
patient_df['bmi'] = round(patient_df['weight'] / (patient_df['height']**2) , 1)
patient_df- 정규화
Scaling
숫자 데이터의 단위나 범위를 일정하게 맞추는것
정규화와 표준화로 나뉜다.정규화 방법
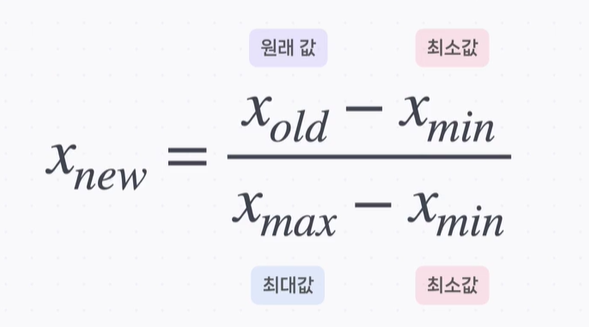

(patient_df['height'] - patient_df['height'].min()) / (patient_df['height'].max() - patient_df['height'].min())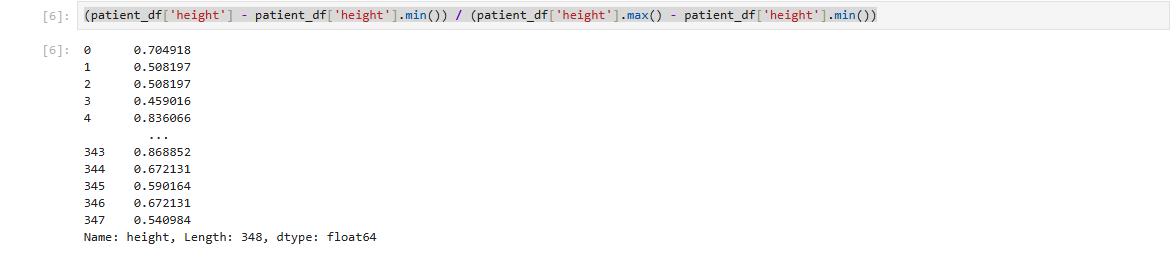
#줄바꿈 추가(\ - python 문법. 줄바꿈 시 마지막에 \추가)
patient_df['height'] = (patient_df['height'] - patient_df['height'].min()) /\
(patient_df['height'].max() - patient_df['height'].min())
patient_df['height'].describe()

개발자