표준화는 데이터를 평균 0, 분산 1로 변환하여 각 데이터가 평균으로부터 얼마나 떨어져 있는지를 나타내며, 데이터 분석 및 모델링에 있어 중요한 전처리 기법이다.
주요 내용
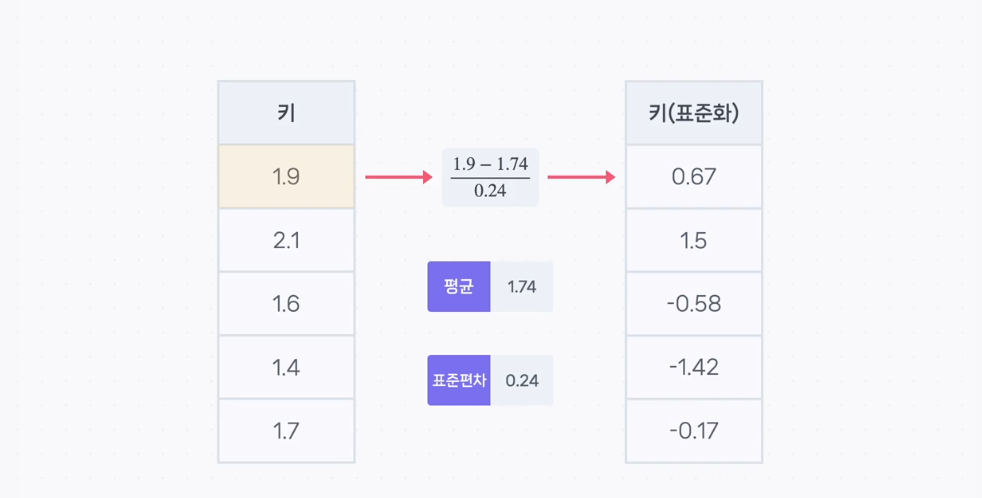
1. 표준화 정의: 표준화는 각 데이터가 평균에 비해 얼마나 크거나 작은지를 나타내기 위해 평균을 0, 분산을 1로 변환하는 과정이다.
2. 계산 방법: 각 데이터 값에서 평균을 빼고, 표준편차로 나누어 Z-Score를 계산한다.
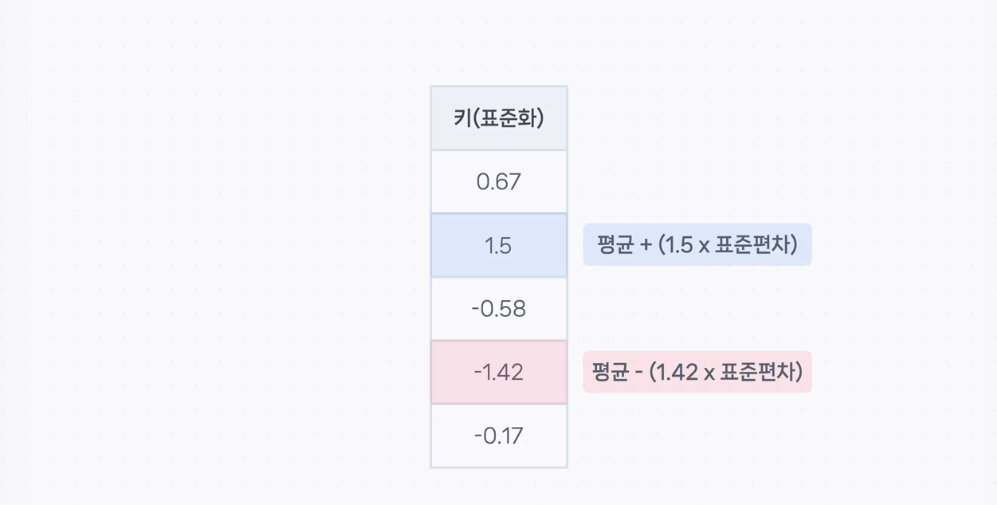
3. Z-Score 의미: Z-Score는 데이터가 평균에서 몇 표준편차 떨어져 있는지를 나타내는 값이다.
4. 코드 구현: 데이터를 불러와서 평균과 표준편차를 계산하고, 이를 이용해 데이터를 표준화한다.
5. 정규화와의 비교: 정규화는 데이터를 0과 1 사이로 조정하며, 용도에 따라 정규화와 표준화를 선택적으로 사용한다.

patient_df['height'] = (patient_df['height'] - patient_df['height'].mean()) /\
(patient_df['height'].std())
patient_df['height'].describe()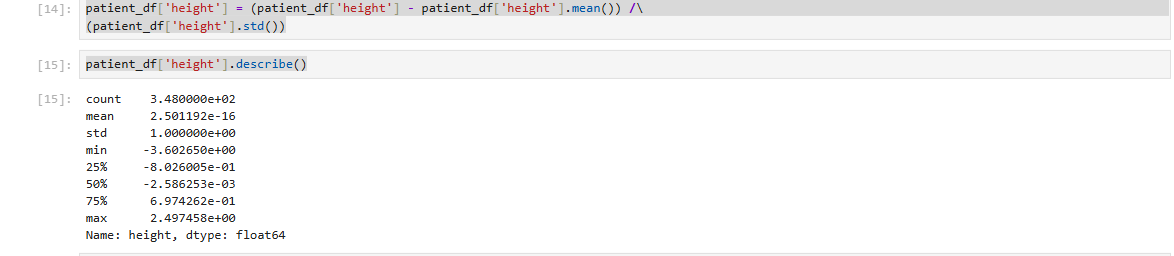
import pandas as pd
patient_df = pd.read_csv('data/patient.csv')
patient_df['weight'] = (patient_df['weight'] - patient_df['weight'].mean()) /\
(patient_df['weight'].std())
patient_df
개발자