- cut() 함수 사용으로 데이터 구간화(binning)
데이터 구간화는 연속적인 숫자 데이터를 특정 기준에 따라 여러 개의 구간으로 분류하는 작업이다.
.
1. 데이터 구간화(Binning)의 정의와 활용: 연속적인 숫자 데이터를 기준에 따라 그룹으로 분류.
2. pandas의 cut 함수 활용: 데이터 구간화를 위한 다양한 방법과 설정.
3. 데이터 구간 정의: 시작점과 끝점을 직접 설정하거나, 자동으로 구간을 나누는 방법.
4. 구간 경계 설정: 구간의 포함 여부를 조정하는 옵션(right 파라미터).
5. 구간 레이블 설정: 구간의 이름을 설정하여 가독성 및 인덱싱 편의성 향상.
pd.cut(patient_df['age'] , bins=[20, 30, 40, 50, 60, 70])
또는 pd.cut(patient_df['age'] , bins=6)- pd.cut() 함수에서 bins가 labels보다 항상 한 개 더 많아야 함. 그 이유는 bins가 구간의 경계값을 정의하기 때문. 예를 들어, 3개의 구간을 만들고 싶다면 4개의 경계값이 필요. 이렇게 해야 각 구간이 시작점과 끝점을 가질 수 있음.
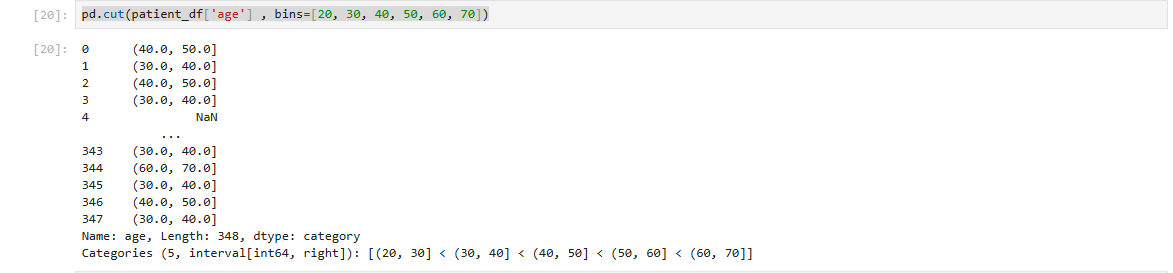
patient_df['age'] = pd.cut(patient_df['age'] , bins=[20, 30, 40, 50, 60, 70])
patient_df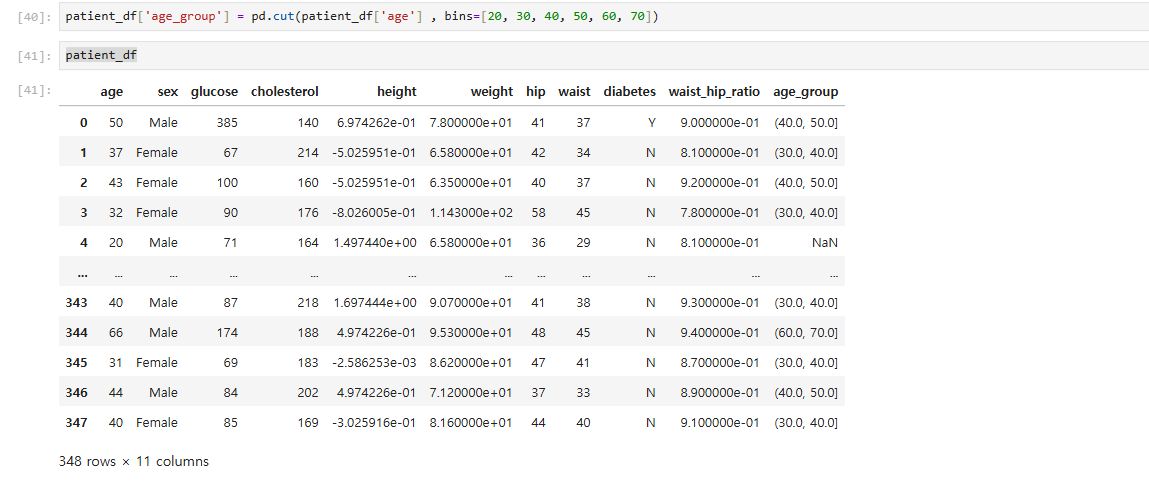
위에서 결측값 발생(NaN). age_group을 확인 해 보면 [50, 60)이런식으로 표현되어 있는데 '[' 나 ']'는 초과 '(' 나 ')'는 이하로 50은 미포함 60은 포함되는 구간임. 이 떄문에 20인 경우는 그 전 구간이 없어 NaN발생.
이를 해결하기 위해 right=False 옵션 추가. 이는 구간에 오른쪽 값을 포함 여부. default는 True.
patient_df['age_group'] = pd.cut(patient_df['age'], bins=[20, 30, 40, 50, 60, 70], right=False)
patient_df 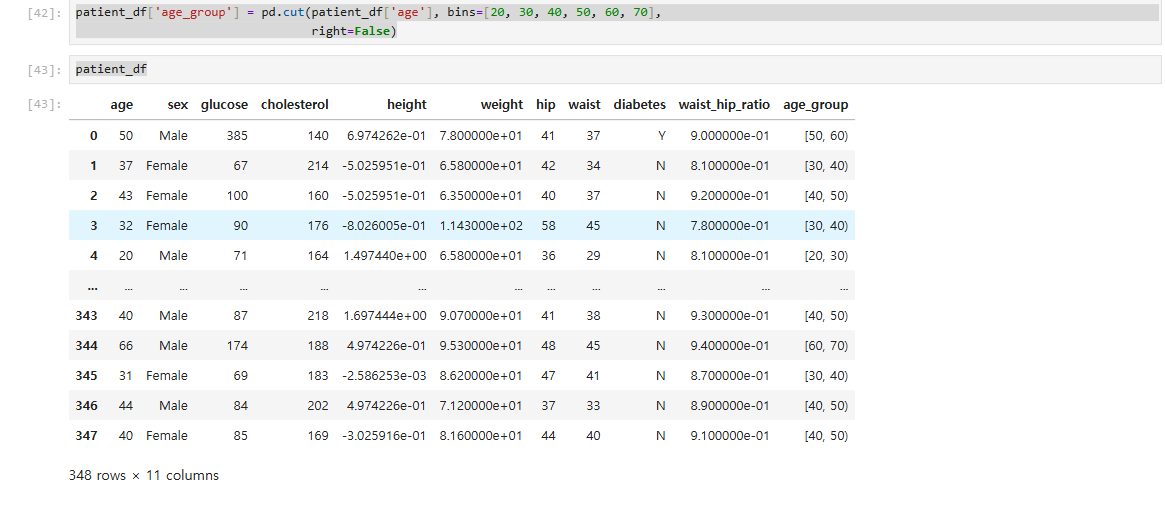
- 구간 이름 변경
위 처럼 구간이 되어있으면 구분이 어려운 부분이 있어 구간명을 변경. labels 옵션 추가.
patient_df['age_group'] = pd.cut(patient_df['age'], bins=[20, 30, 40, 50, 60, 70],
right=False,
labels=['20s','30s','40s','50s','60s'])
patient_df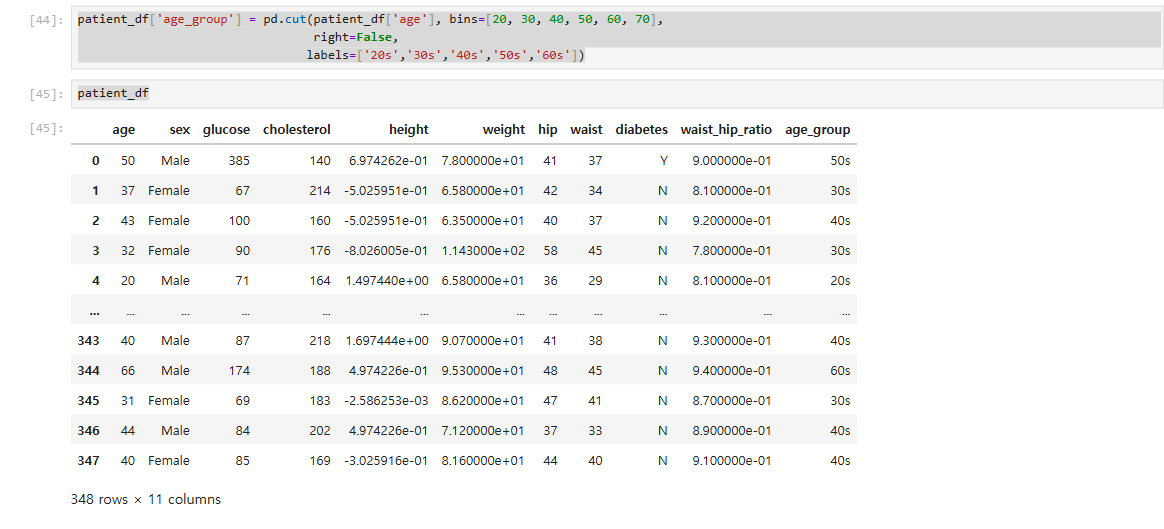
- 예제
환자들의 비만도를 BMI 값에 따라 분류하려고 합니다. 아래 기준에 따라 비만도를 분류해서 obesity라는 컬럼에 저장해 주세요.
18.5 미만(저체중): under
18.5 이상 25 미만(정상): healthy
25 이상 30 미만(과체중): over
30 이상(비만): obese
import pandas as pd
import numpy as np
patient_df = pd.read_csv('data/patient.csv')
patient_df['bmi'] = round(patient_df['weight'] / patient_df['height']**2, 1)
#데이터에 따라 혹시 더 큰 값이 있다면 잘못 분류될 수 있으니, patient_df['bmi'].max() + 1을 사용
#분류 기준이 '이상'과 '미만'으로 나뉘므로, right=False 파라미터를 추가
patient_df['obesity'] = pd.cut(patient_df['bmi']
, bins=[0, 18.5, 25, 30, patient_df['bmi'].max() + 1]
, right=False,labels=['under','healthy','over','obese'])
patient_df

개발자