CNN(Convolution Neural Network)의 기본구조
해당내용은 참조블로그에 기반하여 정리를 하였다.
진행 순서
Convolution layer
Pooling layer
FC layer
Convolution Layer
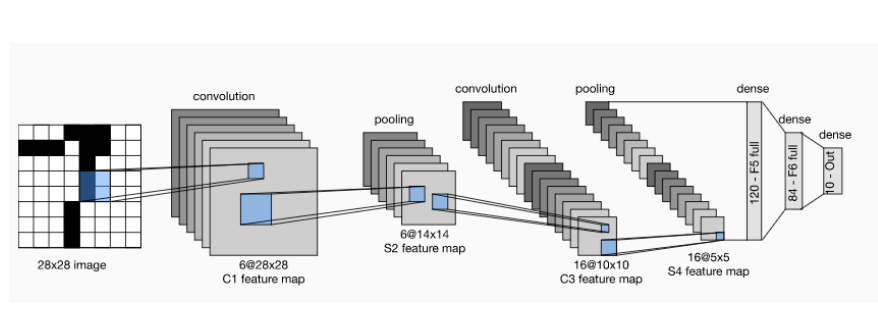
CNN에서 핵심이 되는 부분은 convolution layer이다.
보통 convolution layer에서 filter를 이용해 이미지를 classification하는데 필요한 feature 값만 추출한다.
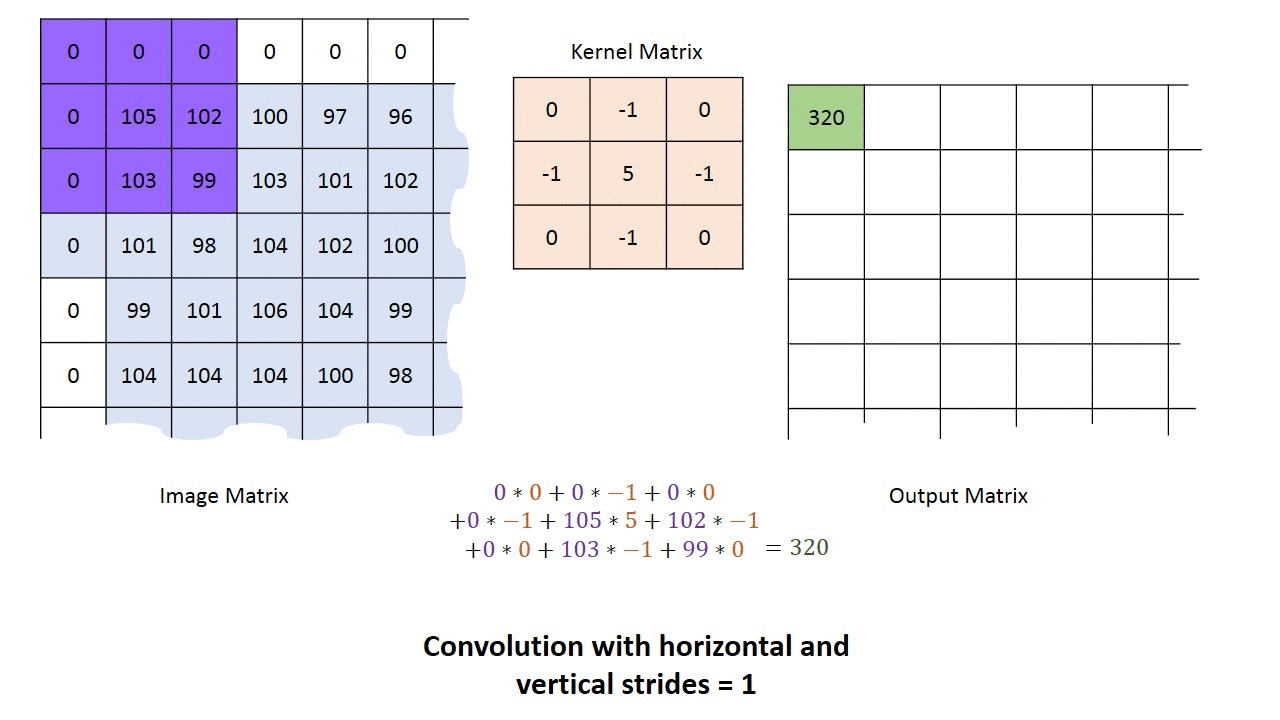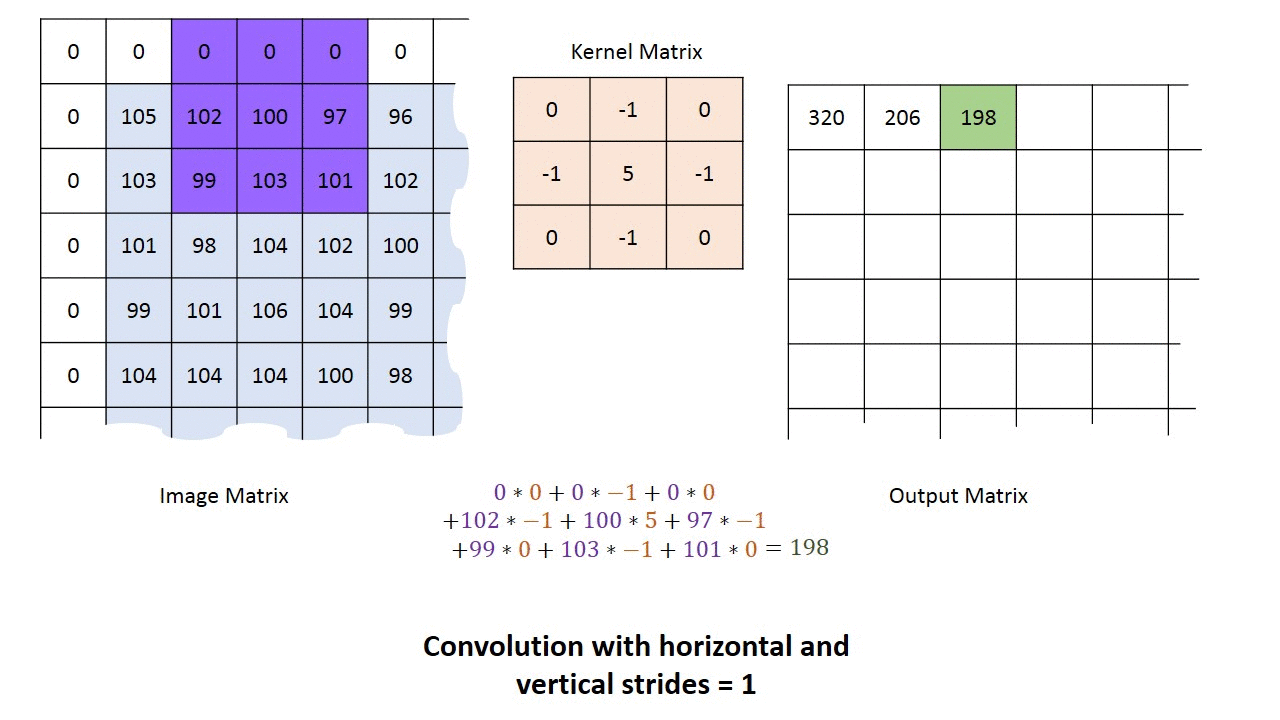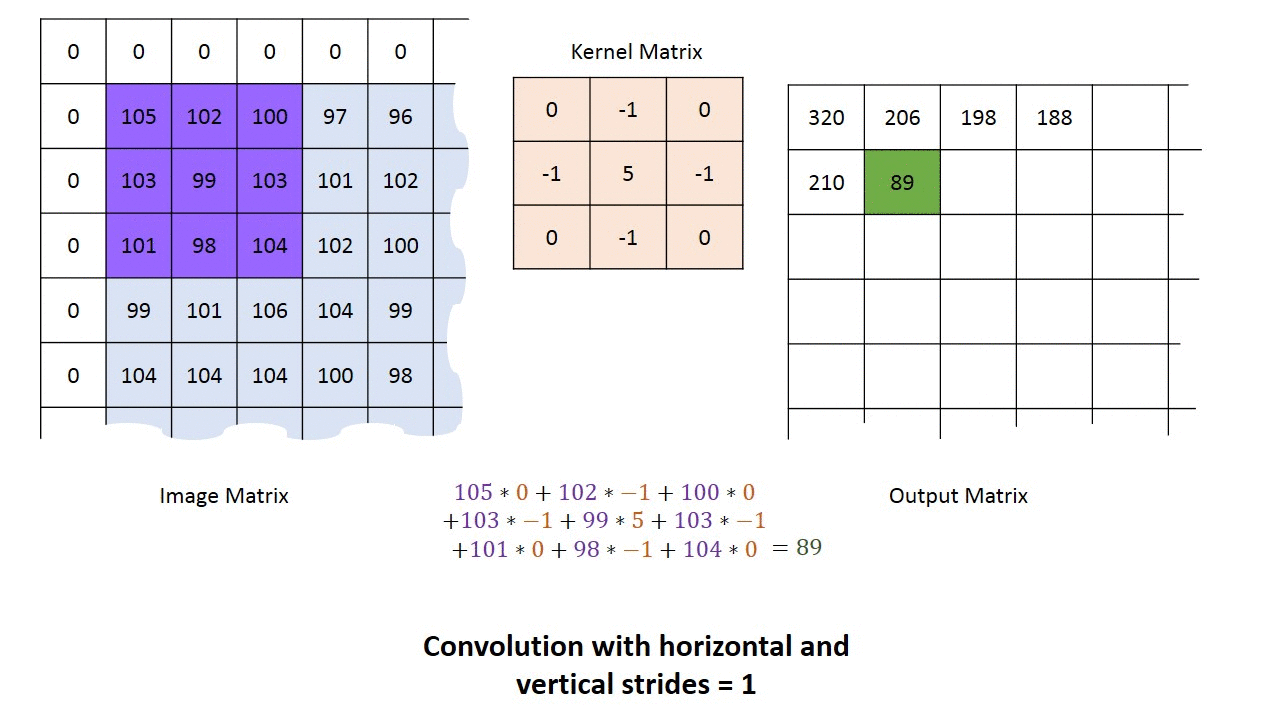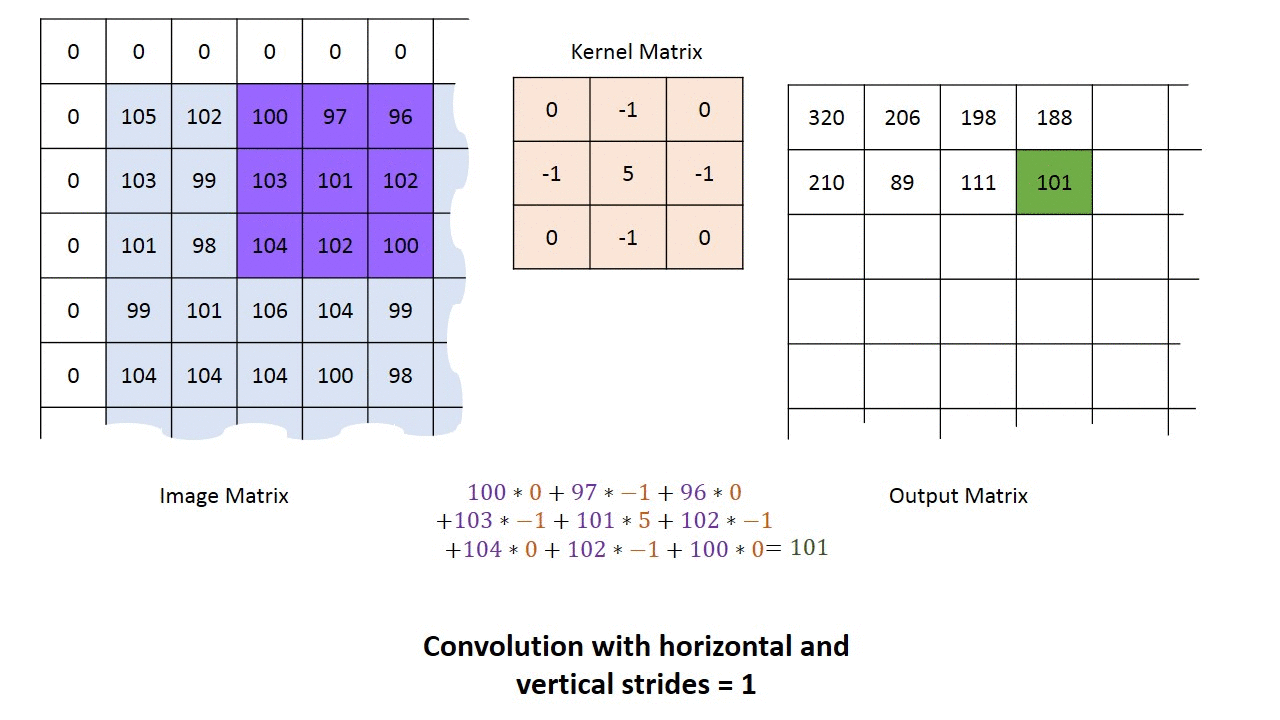
convolution filter는 전체이미지를 차례대로 움직이면서(window sliding)특징값을 추출해낸다.전체 이미지에서 특정 filter의 모양과 일치하면 큰 값을 갖게 된다.
1. First convolution layer
CNN에서 물체의 윤곽을 알아내기 위해 제일 처음 하는 작업은 edge filter를 사용하는 것이다.Convolution filter는 모든 layer에서 같은 크기(3x3)로 고정되어있다.
따라서 처음 들어오는 이미지 크기는 convolution filter크기에 비해 상대적으로 크기 때문에 filter에 통과되는 이미지 부분이 선과 같은 단순한 정보며, 이러한 단순한 모양을 edge라고 부른다.
아래 그림처럼 7x7 conv filter를 이용해 쥐 이미지를 window sliding 방식으로 천천히 이동하게 되면 conv filter의 edge부분과 일치하는 영역에서 높은 값을 도출하게 된다.
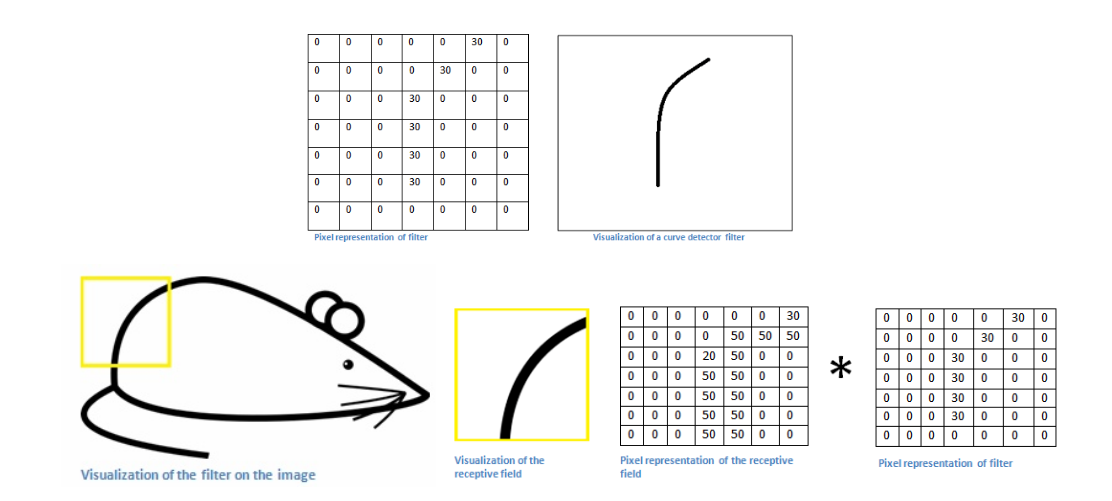
아래 그림에서 45번째 convolution filter를 적용해 보면 오른쪽 부분 녹색 네모박스부분이 45번째 convolution filter가 적용된 결과를 보여준다.
아래 그림 왼쪽 부분에서 45번째 conv filter를 보면 좌측에서 우측으로 갈 수록 밝아지는 걸 볼수 있는데,사람 이미지에 차례로 적용이 되면 좌측에는 어두운 부분, 우측에는 밝은 부분이 표시가 될 것이다.또한 gray sclae에선 흰식이 높은 값을 갖게 되므로 밝은 영역을 지닌 부분이 흰색으로 표시가 된다.
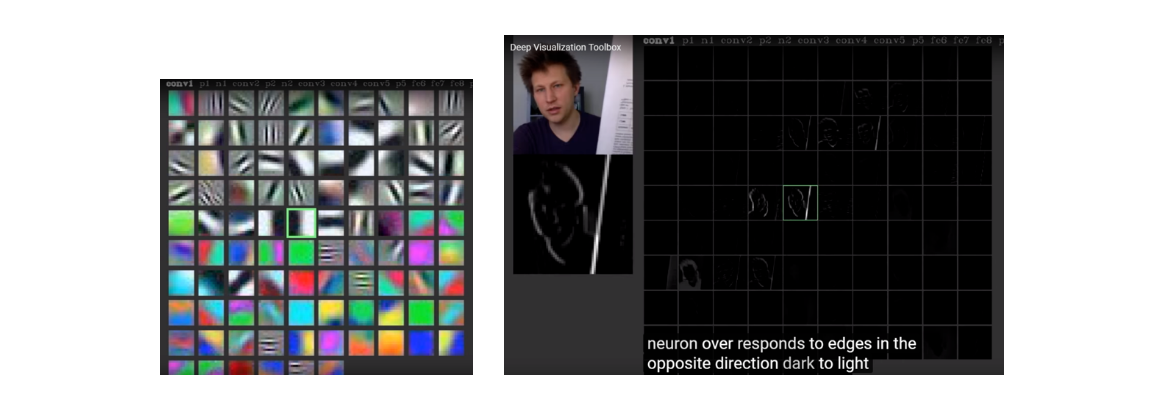
위 그림에 96개의 filter가 있는데 이는 96개의 서로 다른 feature값을 찾는다는 것과 같다.
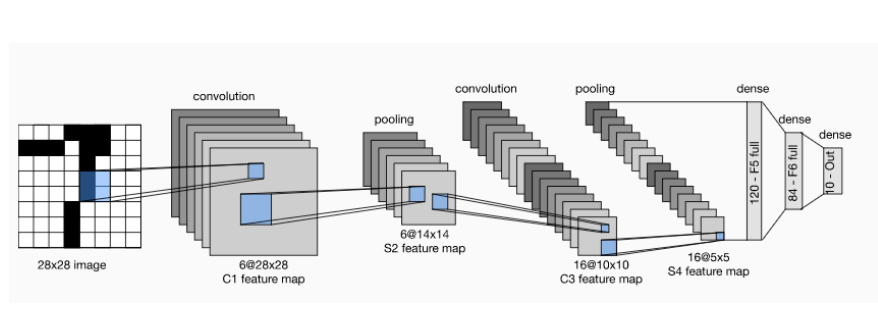
결과적으로 우리가 6개의 filter를 사용하면 아래 그림의 첫번째 conv layer에서 6개의 결과값들이 나오는데, 이를 feature map이라고 부른다(feature(특징)정보들이 들어있는 map(정보)).
처음에는 conv filter 역시 초기값 설정을 통해 무작위로 분포하지만 학습을 통해 아래 그림의 오른쪽과 같이 완성된 edge filter로 만들게 된다.

2.Pooling layer
아래 사진을 보면 convolution layer (Conv)사이에 Pooling layer(pool)가 사이사이에 배치하고 있다.

Pooling 연산에 대해 알아보면, conv filter를 거친 결과로 얻은 각각의 feature map에서 특정영역을 형성해 해당 영역내에 가장 큰 값을 도출한다.이러한 방법을 max pooling이라 한다.
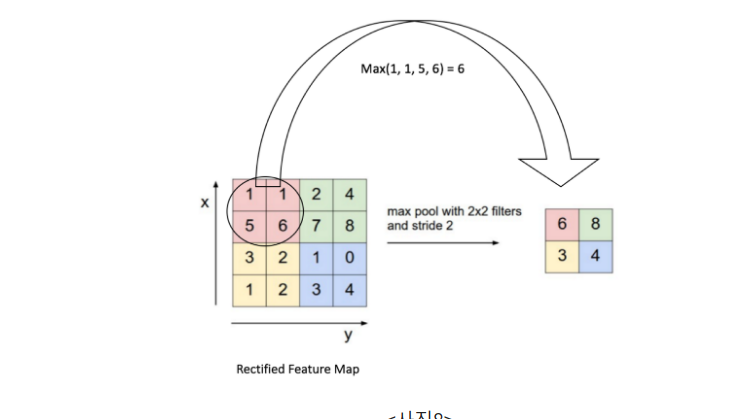
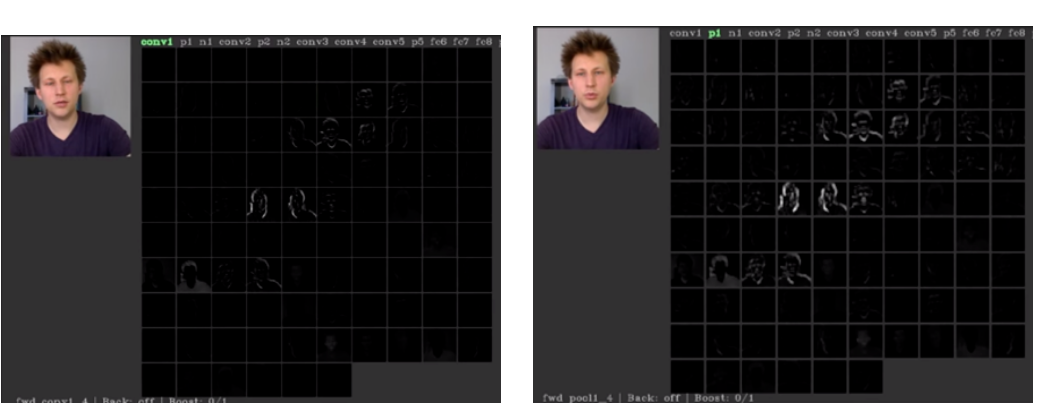
Max pooling은 말 그대로 특정영역에서 가장 큰 값을 꺼내어 쓰는 것이다.아래 사진을 보면 모양은 그대로인데 pooling한 결과가 좀더 feature들이 뚜렷해 지는 것을 볼 수 있다.
아래 사진을 보다시피 pooling연산을 통해 형태는 유지하며 기존의 이미지 크기를 작게 만들수 있게 되었다.(down sampling)
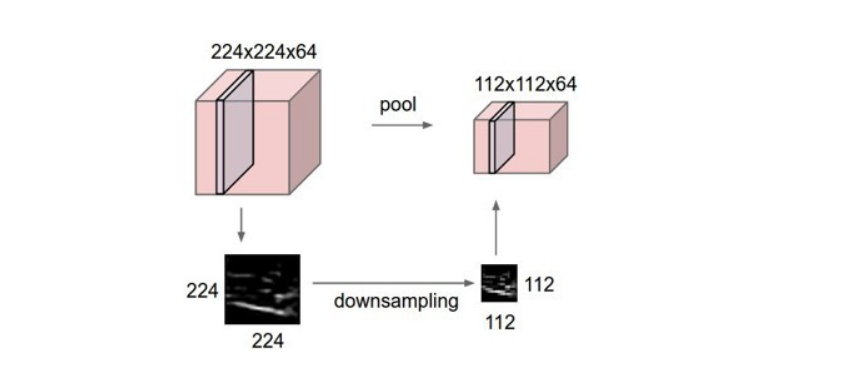
본문에 말한대로 conv filter의 size는 변함이 없다.
First conv layer에서 conv filter는 edge 정보만 추출할수 있었는데, pooling을 통해 down sampling을 하게 되면 이미지 사이즈가 작아져 conv filter의 크기가 상대적으로 커진 것을 알 수 있다.따라서 edge정보가 아닌 눈과 같은 추상적(abstract)인 정보를 볼수있는 conv filter를 갖게 된다.
3.중간점검
지금까지 convolution layer와 pooling layer에 대해 정리해 보았다.
첫번째 convolution layer를 보면 6개의 conv filter를 사용하고 있고, 그 결과 각각의 특징을 갖는 6개의 feature map이 생성된다.그 후 pooling을 통해 6개의 feature map size가 줄어들게 된다(down sampling).
두번째 conv layer에서 16개의 conv filter가 사용되었는데, down sampling으로 이미지의 크기로 filter에 적용되어 첫번째 filter보다 좀더 abstract한 conv filter모양을 보일것이다.
그리고 두번째 conv filter 한개에 통과되는 데이터는 이전 conv layer-pooling layer를 통해 나온 6개의 feature map에 모두 적용된다.
따라서 각 feature map을 합산한 하나의 feature map이 만들어 지고, 합산한 feature map에 두번째 conv layer에 있는 16개의 conv filter들을 적용해 또 다른 16개의 feature map을 생성한다.
보통 layer가 뒤로 갈수록 filter의 총 개수가 많아지는데,
두가지 측면에서 설명할수 있다.
1) 연산량
처음 input img의 크기가 크기 때문에 6개의 conv filter로만 계산을 해도 많은 연산을 해야한다.하지만 마지막 layer까지 가면 이미지의 크기(feature map)가 매우 작아지는데,이때는 많은 conv filter로 연산을 진행해도 첫번째 conv layer에서 6개의 filter를 적용한 계산량과 비슷하게 될 것이다.
2)
첫번째 layer에서 추출할 edge정보는 굉장히 단순한 구조로 되어있어 많은 형태의 모양이 필요 없다고 판단할 수 있다. 하지만 복잡한 모양을 가질수록 형태가 다양해진다.예를 들어 사람의 얼굴을 표현하기 위해선 직선과 곡선이 필요한데 눈,코 입같은 세세한 부위를 표현하기엔 더욱 다양한 형태가 필요해지는 것과 같다.
4.FC layer
위 방식대로 feature를 추출해내면 마지막엔 물체와 유사한 형태의 feature map들이 선별된다.
결국 물체와 유사한 feature map을 통해 classification을 진행하는데, 이때 FC layer가 사용된다.
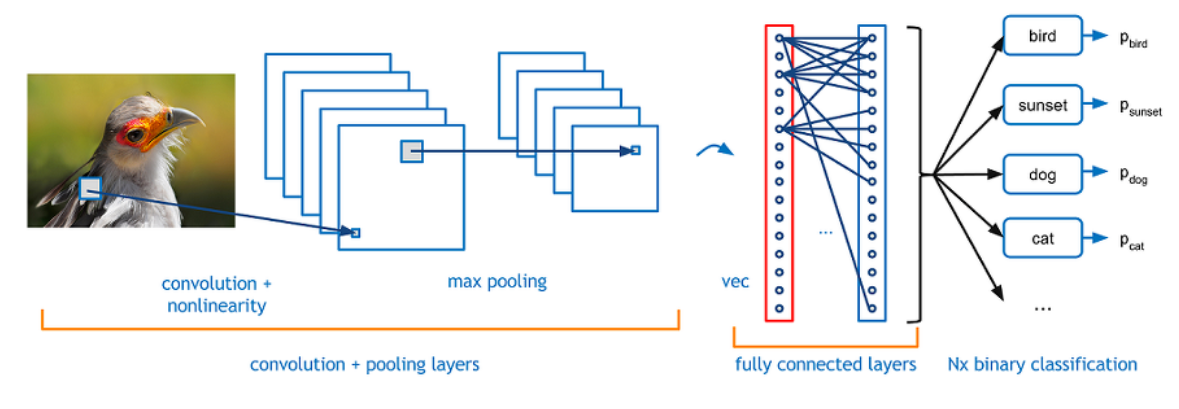
conv filter를 통해 시각정보를 최대한 보존해 오며 마지막 feature map들을 일렬로 늘린후,이를 DNN과 같이 입력차원으로 받아드려서 하나의 Hidden layer를 거쳐 classification을 진행한다.
사진 출처
https://d2l.ai/chapter_convolutional-neural-networks/lenet.html
https://stats.stackexchange.com/questions/296679/what-does-kernel-size-mean/296701
https://adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
https://www.youtube.com/watch?v=AgkfIQ4IGaM
https://www.researchgate.net/figure/AlexNet-and-VGGNet-architecture_fig1_282270749
https://www.itread01.com/content/1544830204.html
