본 게시물은 참고 블로그1,위키독스를 읽고 정리하였습니다.
ResNet
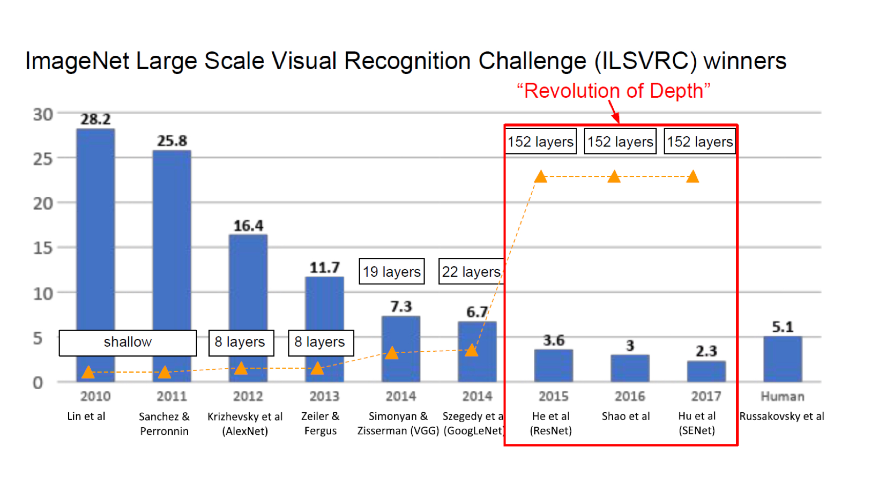
ResNet(Residual Learning)이 나오기 전 CNN을 연구하며 기존 모델들(AlexNet,VGGNet)의 layer를 깊게 쌓으면서 성능 향상을 기대했으나, 실제로는 20층 이상부터 성능이 낮아지는 Degradation문제가 생겼다.ResNet은 이러한 점을 보완하여 layer를 152층까지 쌓을수 있다.
ResNet은 이전 layer의 입력을 다음 layer로 전달하기 위해 skip connection(short connection)을 이용한다.skip connection은 깊은 신경망 생성을 가능케 하고 처음으로 Human error를 능가하는 3.57% top5 error를 보여주어 ILSVRC 15 와 COCO15에서 우승했다.
Gradient Vanishing / Gradient Exploding
기울기를 구하기 위해 가중치에 해당하는 손실함수의 미분을 오차역전파법으로 구한다.이 과정에서 활성화 함수의 편미분을 구하고 그 값을 곱한다.이는 layer가 뒷단으로 갈수록 활성화 함수의 미분값이 점점 작아지거나 커지는 효과를 갖는다.
신경망이 깊을때 작은 미분값이 여러번 곱해지면 0에 가까워진다.이를 gradient vanishing 이라고한다.
반대로 큰 미분값이 여러번 곱해지면 값이 매우 커진다.이를 gradient exploding이라 한다.
이 외에도 Degradation Problem 이라고 부르는,layer가 어느정도 이상으로 깊어지면 오히려 성능이 안좋아 지는 현상이 생긴다는 것을 알수 있다.
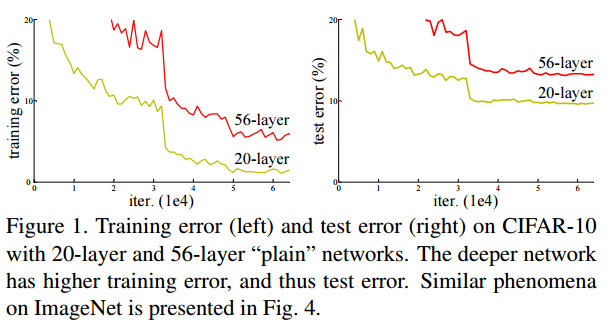
신경망이 깊어질 수록 더 정확한 예측을 할 것이라고 생각했었으나, 아래 그림은 20-layer plain network가 50-layer plain network보다 더 낮은 train error와 test error를 얻는 것을 보여준다.
Residual block/skip,shortcut connection in Residual Network
H(x)를 기존의 네트워크라고 할때 H(x)를 복잡한 함수에 근사시키는 것보다 F(x) := H(x) - x일 때, H(x) = F(x) + x이고, F(x) + x를 근사시키는 것이 더 쉬울 것이라는 아이디어에서 출발한다.원래 output에서 자기 자신을 빼는것이 F(x)의 정의이므로 Residual learning이라는 이름을 갖게된다.x가 F(x)를 통과하고 나서 다시 x를 더해주기 때문에 이를 skip connection이라고 부른다.
기울기 소실 문제가 해결되면 정확도가 감소되지 않고 신경망의 layer를 깊게 쌓을수 있어 더 나은 성능의 신경망을 구축할수 있다.
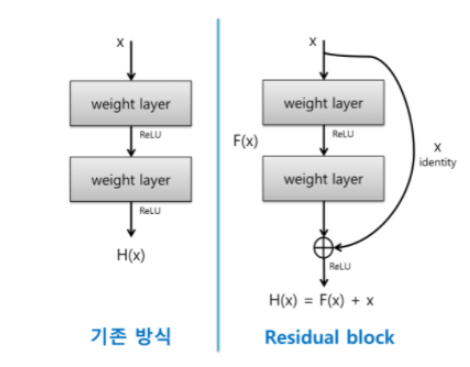
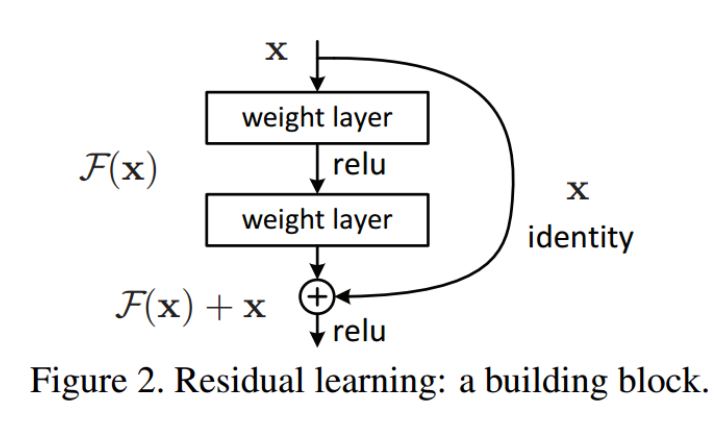
- x:입력값
- F(x) : CNN Layer -> ReLU -> CNN Layer 을 통과한 출력값
- H(x) : CNN Layer -> ReLU -> CNN Layer -> ReLU 를 통과한 출력값
ResNet Architecture
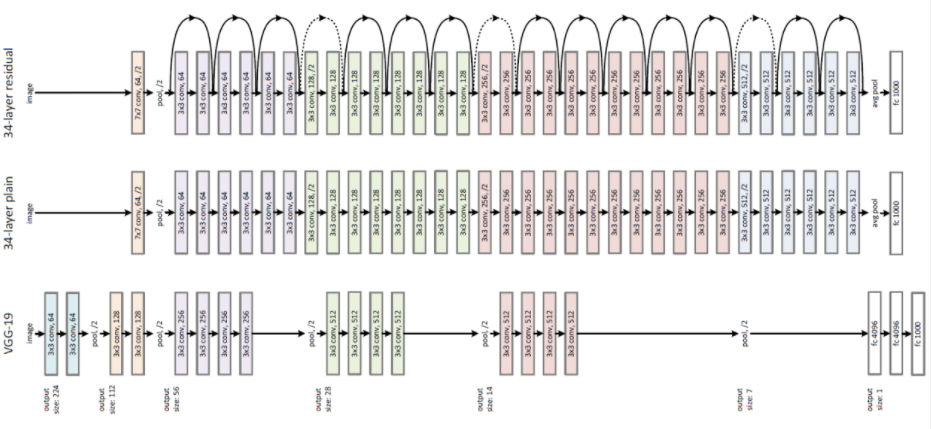
위 그림은 ResNet구조를 보여준다. 맨 아래 구조는 VGG-19,
중간 구조는 VGG-19가 깊어진 34-layer residual network(ResNet)이며 plain network에 skip/short connection이 추가 되었다.
아래 그림은 Plain net과 ResNet의 그림이다
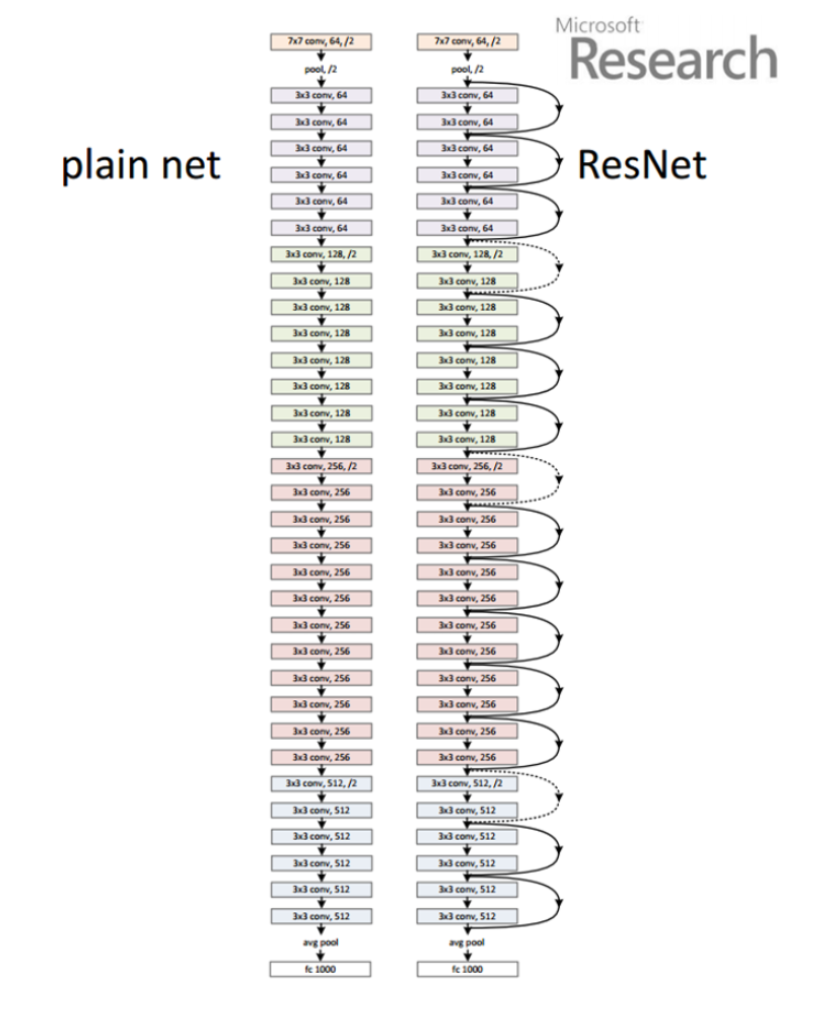
skip/short connection을 추가 하기 위해서는 더해지는 값x와 출력값의 차원이 같아야 한다.ResNet에서는 입력 차원이 출력 차원보다 작을때 사용하는 3종류의 skip/shortcut connection이 있다.
shortcut은 증가하는 차원에 대해 추가적으로 zero padding을 적용하여 identity mapping을 수행한다.따라서 추가적인 파라미터가 없다.
차원이 증가할때만 projection shortcut을 사용한다.다른 shortcut은 identity이며 추가적인 파라미터가 필요하다.
모든 shortcut이 projection이다.B보다 많은 파라미터가 필요하다.
Deeper bottleneck architecture
50층 이상의 깊은 모델에서는 Inception에서와 마찬가지로 연산상의 이점을 위해 Bottleneck layer(1x1 convolution)을 이용했다.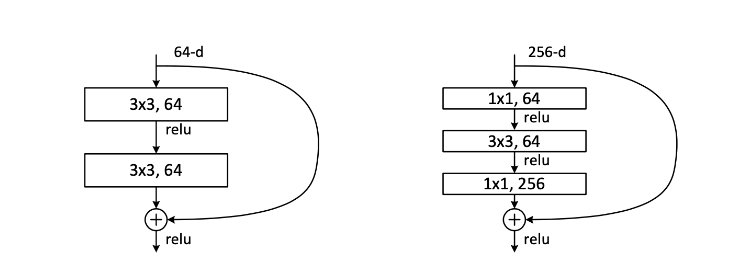
기존의 residual block은 한 블록에 convolution layer(3x3)2개가 있는 구조였다.Bottleneck구조는 층이 하나 더 생겼지만 convolution layer (1x1)2개를 신경망의 처음과 끝에 사용하기 때문에 파라미터 수가 감소하여 신경망의 성능을 감소시키지 않고 연산량을 줄였다.이 기법은 NN과 GoogLeNet에서 제안되었다.
Bottleneck design으로 연산량을 감소시켜 34-layer는 50-layer ResNet이 되고 ResNet-101 , ResNet-152와 같은 Bottleneck design을 지닌 더 깊은 신경망이 생겨났다.
또한 VGG-16보다 ResNet-152가 더 적은 연산량을 가진다.

ResNet 초창기 논문에서는 110Layer에서 가장 적은 error을 보여주었고, 1000개 이상의 layer가 쌓였을때는 Overfitting이 발생하였다.
Plain Network / ResNet

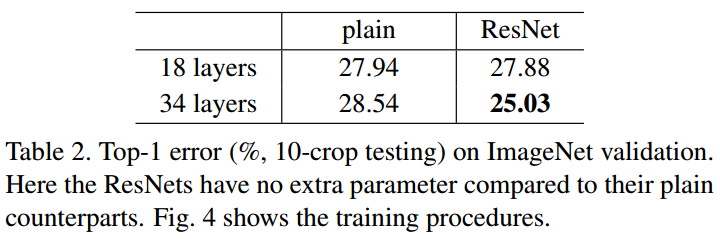
Plain Network에서 vanishing gradient때문에 18-layer의 성능이 34-layer 보다 뛰어나다.
ResNet에서는 vanishing gradient 문제가 skip connection에 의해 해결되어 34-layer의 성능이 18-layer보다 뛰어나다.
깊지 않은 일반적인 신경망에서는 vanishing gradient 문제가 나타나지 않기에 18-layer plain network와 18-layer ResNet network에는 차이점이 없다.
ResNet이 잘 되는 이유
원 논문에서 자신들이 어떤 이론을 바탕으로 결과를 도출했다기보다는 경험적으로residual block을 쓰니 좋은 결과가 나왔다고 서술했다.그럼에도 불구하고 ResNet이 왜 잘동작하는지 설명하려는 노력이 있었고 아직까지도 많은 사람들이 연구하고 있다.
Optimal depth란 신경망의 최적 layer 개수라고 생각하면 될 것 같다.신경망 학습을 진행하면서 optimal depth를 쉽게 유추해낼수 없다.하지만 vanishing/explode gradient와 같은 degradation problem들은 optimal depth를 넘어가면 바로 발생한다.
ResNet은 깊은 네트워크를 만들고 Optimal depth에서의 값을 바로 Output으로 보내줄수 있는데 이는 Skip connection 때문이다.ResNet은 Skip connection이 존재하기에 Main path에서 Optimal depth이후의 weight와 bias가 전부 0에 수렴하도록 학습된다면 Optimal depth에서의 Output이 바로 Classification으로 넘어갈 수 있다.즉 Optimal depth이후의 layer들은 결과값에 영향을 주지 않는 것이다.
예를 들어 27층이 Optimal depth인데 ResNet-50에서 학습을 한다면 28층부터 Classification전까지의 weight와 bias를 전부 0으로 만드는 것이다.
따라서 27층의 결과값이 바로 classification에서 이용되어 Optimal depth의 네트워크를 그대로 사용하는것과 같다고 볼 수 있다.
