본 게시물은learn-opencv의 내용을 번역하여 정리한 글이다.
Input
AlexNet은 ILSVRC 2012에서 수상한 항목이다.입력이 1000개의 다른 class(고양이,개)중 하나의 이미지이고 출력이 1000개의 숫자로 구성된 벡터인 이미지 분류 문제를 해결한다.
출력 벡터의 i번째 요소는 입력 이미지가 i번째 class일 확률로 해석된다.따라서 모든 출력벡터의 합은 1이다.
AlexNet의 입력값은 256 x 256크기의 RGB이미지다.이는 train set의 모든 이미지와 모든 test 이미지 크기가 256,256이어야 함을 의미한다.
입력 이미지가 256 x 256이 아닌경우 네트워크 학습에 사용하기 전 256x256으로 변환해야 한다.이를 위해 더 작은 차원의 크기를 256으로 조정한다음 결과 이미지를 잘라 256x256 이미지를 얻는다.

입력 영상이 Grayscale이면 단일 채널을 복제해 RGB 영상으로 변환해 3채널 RGB영상을 얻는다.AlexNet의 첫번째 layer에 데이터를 입력하기위해 256x256 이미지 내부에서 227x227크기의 무작위 crop이 생성되었다.이 논문에서는 네트워크 입력이 224x224라고 언급했지만 이는 실수이며 숫자는 대신 227x227로 의미가 있다.
AlexNet Architecture
AlexNet은 CV작업에 사용된 이전 CNN보다 더욱 커졌다.(Yann LeCun의 1998 LeNet).6천만개의 매개변수와 650000개의 뉴런이 있으며 2개의 GTX580 3GB GPU에서 훈련하는데 5~6일이 걸렸다.
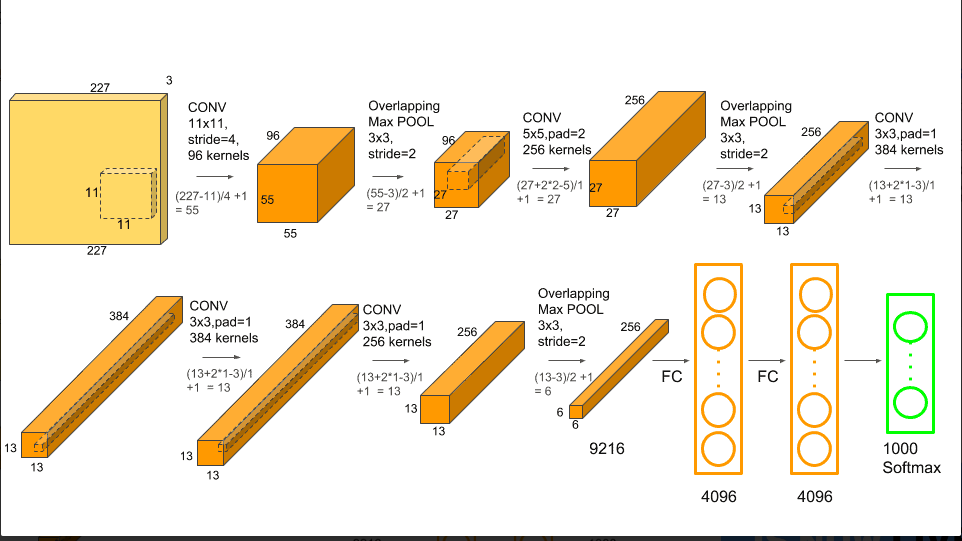
AlexNet은 5개의 Convolutional Layer와 3개의 Full Connected Layer로 구성되어 있다.
다중 Convolutional kenel(filter)은 이미지에서 흥미로운 특징을 추출한다. 단일 convolution layer에는 일반적으로 동일한 크기의 커널이 많이 있다.예를 들어 AlexNet의 첫번째 변환 계층에는 11x11x3크기의 커널이 96개 포함되어 있다.커널의 높이는 일반적으로 동일하고 깊이는 채널수와 동일하다.
처음 두개의 convolutional layer 다음에는 Overlapping Max Pooling layer(설명) 가 있다.3,4,5번째 convolution layer는 직접 연결된다.다섯번째 convolution layer 다음에는 Overlapping Max Pooling layer가 있으며 출력은 두개의 완전히 연결된 일련의 layer로 이동한다.두번째 Fully connected layer는 1000개의 class lable이 있는 softmax분류기로 들어간다.
ReLU 비선형성은 모든 convolution및 fc layer후에 적용된다.첫번째 및 두번째 convolution layer의 ReLu비선형성은 pooling을 수행하기 전에 local nomalization 단계를 거친다.그러나 후에 nomalization이 그다지 유용하지 않다는 것을 발견하였다.
Overlapping MaxPooling
링크 는 Overlapping Maxpolling에 관하여 정리한 블로그다.
Max Pooling layer는 일반적으로 깊이를 동일하게 유지하면서 Tensor의 너비와 높이를 다운샘플링하는데 사용된다.Overlapping Max Pool layer는 Max Pool layer와 비슷하지만 최대값이 계산되는 인접한 창은 서로 겹쳐진다.블로그에서 stride =2 크기는 3x3의 pooling window를 사용했다.pooling의 이러한 중첩특성은 동일한 출력을 하는 stride=2 2x2 비중첩 pooling window를 사용하여 비교할 때 상위 1 오류율은 0.4% , 상위5 오류율은 0.3% 줄이는데 도움이 되었다.
ReLU 비선형성
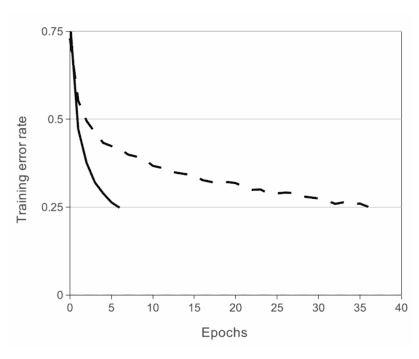
AlexNet의 중요한 기능은 ReLU(Rectified Linear Unit)비선형성을 사용한다는 것이다.Tanh 또는 Sigmoid활성화 함수는 신경망 모델을 훈련하는 일반적인 방법이였다.AlexNet은 ReLU비선형성을 사용하면 tanh,sigmoid와 같은 포화 활성화 함수를 사용하는 것보다 깊은 CNN을 훨씬 빠르게 훈련 할 수 있음을 보여주었다.위 그림은 ReLUs(실선곡선)를 사용해 AlexNet이 tanh(점선)를 사용하는 같은 네트워크보다 6배 빠른 25%훈련 오류율을 보여준다.해당 작업은 CIFAR-10 dataset에서 test되었다.
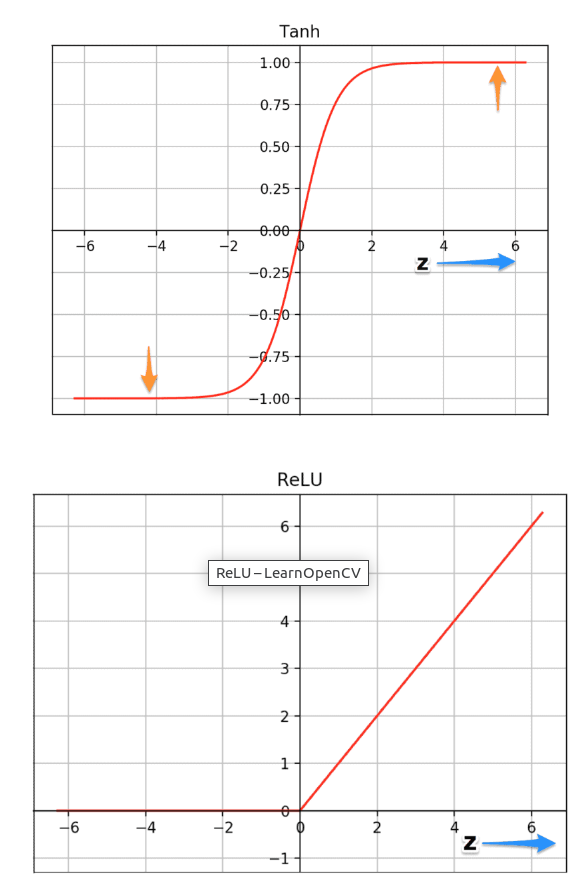
ReLU를 사용하면 더 빨리 train이 되는 이유를 알아본다.
f(x) = 최대(0,x)
위 그래프는 tanh와 ReLU의 두 함수 plot이다.tanh함수는 z의 매우높거나 매우 낮은 값에서 포화된다.이 영역에서 함수의 기울기는 0에 매우 가까워 경사 하강법(gradient descent)를 늦추게 된다.반면 ReLU 함수의 기울기는 z의 더 높은 양수값에 대해 0에 가깝지 않다.이런 방식은 최적화가 더 빨리 진행된다.z의 음수값의 경우 기울기는 여전히 0이지만 신경망의 대부분의 뉴런은 일반적으로 양수의 값을 갖는다.이와 같은 이유로 ReLU가 sigmoid함수보다 우위에 있다.
Overfitting 줄이기
overfitting이란?
NN에서 제한된 데이터로 계속 학습을 하다보면 훈련 데이터에선 잘 작동하지만 학습하지 않은 새로운 test dataset에선 엉망으로 작동을 하게 된다.이를 과적합(over fitting)이라고 한다.
AlexNet은 몇가지 방법을 통해 과적합을 줄였다.
데이터 증강 (Data Augmentation)
신경망에 동일한 이미지에 변화를 주면 과적합을 방지하는데 도움이 된다.예를 들어 이미지를 회전,반전,색반전,crop 과 같은 방식으로 동일한 이미지에 대해 변화를 줄 수 있다.AlexNet에선 다음과 같은 방식으로 데이터 증강을 진행하였다.
Mirroring
train set에 고양이 이미지가 있는 경우 mirror된 사진도 고양이 이미지 이다.따라서 수직 축을 중심으로 이미지를 뒤집기만 하면 train set의 크기를 두배로 늘릴수 있다.
Random Crops
원본 이미지를 random하게 자르면 원본데이터의 이동된 이미지도 생성된다. AlexNet에서는 input data로 256x256 이미지 경계 내부에서 227x227의 크기로 random crop을 진행하였고 결과적으로 데이터를 2048배 늘렸다
Random 하게 자른 4개의 이미지는 비슷해 보이지만 똑같지 않다.이는 픽셀의 미세한 이동이 고양이 이미지라는 사실을 변경하지 않는다는것을 신경망에 학습시킨다.

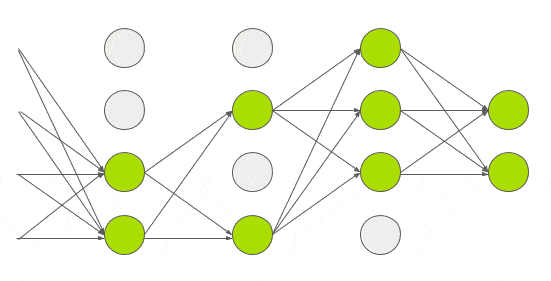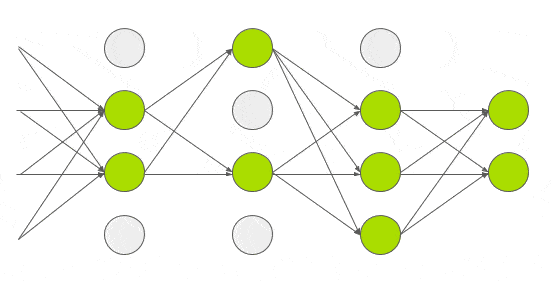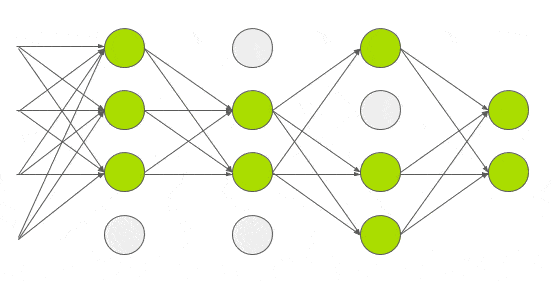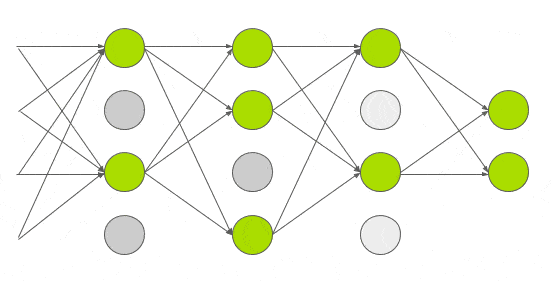
Dropout
train을 진행할 약 6천만개의 매개변수를 사용해 과적합을 줄이는 방법을 실험했다.GE Hinton의 논문에서 소개한 Dropout이라는 기술을 적용했다.Dropout에서 뉴런은 0.5의 확률로 네트워크에서 삭제된다.뉴런이 삭제되면 정방향 또는 역방향 전파에 기여하지않는다.
따라서 모든 입력값은 아래 gif같이 다른 네트워크 아키텍쳐를 거친다.결과적으로 학습된 가중치 매개변수는 더 강력하고 쉽게 과적합되지 않는다.