1. 경사하강법
참고 : https://gooopy.tistory.com/129
경사하강법이란?
경사하강법(Gradient Descent)은 머신 러닝과 최적화에서 매우 중요한 개념으로, 함수의 최솟값을 찾는 데 사용됨.
주로 비용 함수(cost function)를 최소화하거나 최대화하는 문제에서 활용됨.
개념
경사하강법은 함수의 기울기(경사)를 이용하여 함수의 최솟값(또는 최대값)을 찾는 최적화 방법. 주어진 함수의 기울기가 음수면 함수 값을 줄이기 위해 기울기 방향으로 이동하고, 기울기가 양수면 함수 값을 줄이기 위해 기울기 반대 방향으로 이동.
이 과정을 반복하여 함수의 최솟값에 접근.
작동 원리
- 초기화: 시작점을 임의로 선택하거나 정해진 초기값을 설정.
- 기울기 계산: 현재 위치에서의 함수의 기울기(경사)를 계산.
이는 함수의 편도함수(partial derivative)를 계산하여 구할 수 있음.
- 이동: 기울기의 반대 방향으로 일정 거리만큼 이동.
이 거리는 학습률(learning rate)이라고 부르는 매개변수에 의해 결정됨.
학습률은 한 번의 반복에서 얼마나 멀리 이동할지를 조절.
- 반복: 위 과정을 반복.
각 반복마다 현재 위치에서의 기울기를 계산하고, 이를 이용하여 새로운 위치로 이동.
이 과정을 충분한 횟수만큼 반복하면, 최적의 해(최솟값 또는 최대값)에 도달.
종류
배치 경사하강법 (Batch Gradient Descent):
- 전체 학습 데이터셋을 사용하여 한 번의 반복에서 기울기를 계산하고 이동하는 방법.
데이터셋이 클 경우 계산 시간이 오래 걸릴 수 있음.확률적 경사하강법 (Stochastic Gradient Descent, SGD):
- 각 학습 데이터 포인트에 대해 기울기를 계산하고 이동하는 방법.
매 반복마다 하나의 데이터 포인트를 사용하기 때문에 계산 속도가 빠르지만 불안정할 수 있음.미니배치 경사하강법 (Mini-batch Gradient Descent):
- 일정 크기의 미니배치(mini-batch) 데이터를 사용하여 기울기를 계산하고 이동하는 방.
이는 배치와 SGD의 장점을 결합한 방법으로, 일반적으로 가장 많이 사용됨.
사용 예시
경사하강법은 선형 회귀, 로지스틱 회귀 등 다양한 머신 러닝 모델에서 사용됨.
예를 들어, 선형 회귀에서는 비용 함수를 최소화하여 최적의 회귀 계수를 찾기 위해 경사하강법을 사용함.
또한, 신경망에서도 각 레이어의 가중치와 편향을 조정하여 손실 함수를 최소화하는 데 경사하강법을 적용함.
#파이썬으로 경사하강법 구현
#업데이트할 W : Learning Rate*((Y예측-Y실체)*X)평균
#업데이트할 b: Learning Rate*((Y예측-Y실체)*1)평균
import numpy as np
import matplotlib.pyplot as plt
X = np.random.rand(100)
Y = 0.2 * X * 0.5
X[:10]
### 출력 결과
array([0.96658608, 0.48519549, 0.64279304, 0.03423192, 0.76161898,
0.53201886, 0.59284884, 0.11214976, 0.58340996, 0.68647162])
Y[:10]
### 출력 결과
array([0.09665861, 0.04851955, 0.0642793 , 0.00342319, 0.0761619 ,
0.05320189, 0.05928488, 0.01121498, 0.058341 , 0.06864716])plt.figure(figsize=(8, 6))
plt.scatter(X, Y)
plt.show()
### 출력 결과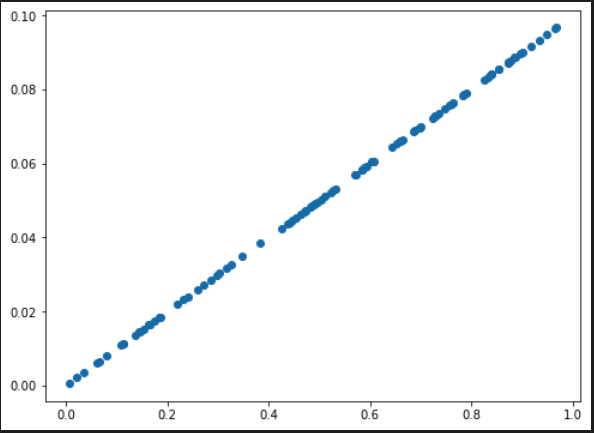
def plot_prediction(pred, y):
plt.figure(figsize=(6, 4))
plt.scatter(X, y)
plt.scatter(X, pred)
plt.show()
## Gradient Descent 구현
W = np.random.uniform(-1, 1)
b = np.random.uniform(-1, 1)
W
### 출력 결과
-0.6558399437238558
b
### 출력 결과
0.7952027966706336learning_rate = 0.7
for epoch in range(100):
Y_Pred = W * X + b
error = np.abs(Y_Pred - Y).mean()
if error < 0.001:
break
#gradient descent
w_grad = learning_rate * ((Y_Pred - Y)*X).mean()
b_grad = learning_rate * (Y_Pred - Y).mean()
#W, b 값 갱신
W = W - w_grad
b = b - b_grad
if epoch % 5 == 0:
Y_Pred = W * X + b
plot_prediction(Y_Pred, Y)위 함수 설명
초기 설정
- learning_rate = 0.7: 경사하강법에서 한 번에 얼마나 많이 학습할지 결정하는 매개변수.
높은 학습률은 빠른 학습을 의미하지만 수렴하지 않을 수 있고, 낮은 학습률은 수렴 속도가 느릴 수 있음. ( 0 ~ 1 사이의 값)주요 루프 (Epoch 반복)
- for epoch in range(100): 100번의 반복(epoch) 동안 모델을 학습.
이는 주어진 반복 횟수 동안 최적의 모델 파라미터(W, b)를 찾기 위한 반복적인 과정을 의미.예측값 계산
- Y_Pred = W * X + b: 현재의 가중치(W)와 편향(b)을 사용하여 예측값을 계산.
오차 계산 및 수렴 조건
- error = np.abs(Y_Pred - Y).mean(): 예측값과 실제 값 사이의 오차를 계산.
여기서는 평균 절대 오차를 사용하며, 이 오차가 0.001보다 작으면 학습을 종료.경사하강법 적용
- w_grad = learning_rate ((Y_Pred - Y) X).mean(): 가중치(W)에 대한 기울기를 계산.
이는 예측 오차와 입력 데이터(X)의 곱의 평균.- b_grad = learning_rate * (Y_Pred - Y).mean(): 편향(b)에 대한 기울기를 계산합.
예측 오차의 평균.파라미터 업데이트
- W = W - w_grad: 새로 계산된 가중치의 값을 현재 가중치에서 빼서 업데이트.
- b = b - b_grad: 새로 계산된 편향의 값을 현재 편향에서 빼서 업데이트.
시각화
- if epoch % 5 == 0:: 매 5번째 epoch에서 예측값을 계산하고, plot_prediction(Y_Pred, Y) 함수를 호출하여 예측값과 실제 값의 시각화를 수행.
이를 통해 학습 과정을 시각적으로 확인할 수 있음.
요약
이 코드는 선형 회귀를 경사하강법을 사용하여 학습하는 과정을 보여줍니다. 반복적으로 가중치와 편향을 조정하여 예측 오차를 최소화하고, 지정된 오차 기준을 만족할 때까지 학습을 반복합니다. 매 반복마다 학습 과정을 시각화하여 모델의 학습 상태를 모니터링할 수 있습니다.
예제) 화씨 온도 구하기
섭씨온도와 화씨온도가 다음과 같은 선형(linear)관계를 Linear Regression 으로 접근
w(weight, 가중치), b(bias)
하지만, 1.8과 32라는 값을 모르고 있다고 가정한 뒤, 머신러닝 알고리즘을 이용하여 주어진 섭씨온도와 화씨온도 데이터만으로 이 값들을 찾아보는 실습을 해보겠습니다.
방법1) 파이썬
import numpy as np
C = np.random.randint(low=0, high=100, size=200)
print(len(C))
C
### 출력 결과
200
array([46, 29, 73, 15, 98, 43, 83, 50, 5, 86, 14, 42, 93, 97, 86, 28, 49,
58, 72, 81, 81, 35, 54, 68, 97, 91, 17, 32, 13, 69, 27, 8, 1, 76,
23, 82, 32, 49, 28, 13, 78, 92, 50, 36, 48, 68, 25, 79, 93, 30, 98,
7, 21, 57, 81, 21, 55, 94, 14, 52, 28, 76, 85, 10, 86, 67, 84, 86,
68, 96, 27, 33, 58, 49, 39, 38, 70, 38, 40, 97, 74, 71, 70, 34, 37,
13, 98, 36, 60, 80, 6, 7, 84, 58, 94, 23, 46, 24, 61, 26, 73, 88,
27, 86, 70, 43, 8, 76, 13, 73, 1, 4, 85, 93, 12, 78, 36, 49, 70,
59, 49, 30, 43, 17, 67, 31, 22, 71, 81, 12, 71, 68, 13, 25, 70, 62,
1, 86, 58, 89, 1, 21, 98, 68, 45, 96, 84, 34, 39, 58, 6, 92, 54,
0, 16, 1, 98, 7, 9, 70, 62, 76, 53, 49, 10, 45, 35, 83, 94, 80,
74, 73, 1, 86, 34, 33, 0, 49, 33, 43, 1, 78, 4, 78, 52, 84, 94,
48, 90, 18, 6, 17, 85, 66, 94, 68, 96, 61, 16, 36])
F = C * 1.8 + 32
F
### 출력 결과
array([114.8, 84.2, 163.4, 59. , 208.4, 109.4, 181.4, 122. , 41. ,
186.8, 57.2, 107.6, 199.4, 206.6, 186.8, 82.4, 120.2, 136.4,
161.6, 177.8, 177.8, 95. , 129.2, 154.4, 206.6, 195.8, 62.6,
89.6, 55.4, 156.2, 80.6, 46.4, 33.8, 168.8, 73.4, 179.6,
89.6, 120.2, 82.4, 55.4, 172.4, 197.6, 122. , 96.8, 118.4,
154.4, 77. , 174.2, 199.4, 86. , 208.4, 44.6, 69.8, 134.6,
177.8, 69.8, 131. , 201.2, 57.2, 125.6, 82.4, 168.8, 185. ,
50. , 186.8, 152.6, 183.2, 186.8, 154.4, 204.8, 80.6, 91.4,
136.4, 120.2, 102.2, 100.4, 158. , 100.4, 104. , 206.6, 165.2,
159.8, 158. , 93.2, 98.6, 55.4, 208.4, 96.8, 140. , 176. ,
42.8, 44.6, 183.2, 136.4, 201.2, 73.4, 114.8, 75.2, 141.8,
78.8, 163.4, 190.4, 80.6, 186.8, 158. , 109.4, 46.4, 168.8,
55.4, 163.4, 33.8, 39.2, 185. , 199.4, 53.6, 172.4, 96.8,
120.2, 158. , 138.2, 120.2, 86. , 109.4, 62.6, 152.6, 87.8,
71.6, 159.8, 177.8, 53.6, 159.8, 154.4, 55.4, 77. , 158. ,
143.6, 33.8, 186.8, 136.4, 192.2, 33.8, 69.8, 208.4, 154.4,
113. , 204.8, 183.2, 93.2, 102.2, 136.4, 42.8, 197.6, 129.2,
32. , 60.8, 33.8, 208.4, 44.6, 48.2, 158. , 143.6, 168.8,
127.4, 120.2, 50. , 113. , 95. , 181.4, 201.2, 176. , 165.2,
163.4, 33.8, 186.8, 93.2, 91.4, 32. , 120.2, 91.4, 109.4,
33.8, 172.4, 39.2, 172.4, 125.6, 183.2, 201.2, 118.4, 194. ,
64.4, 42.8, 62.6, 185. , 150.8, 201.2, 154.4, 204.8, 141.8,
60.8, 96.8])import matplotlib.pyplot as plt
import pandas as pd
plt.scatter(C, F)
plt.plot(C, F, c='r')
### 출력 결과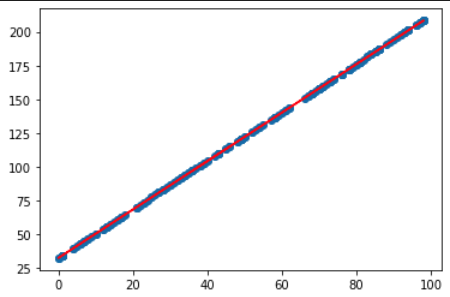
X = C
y = F
X, y
### 출력 결과
(array([46, 29, 73, 15, 98, 43, 83, 50, 5, 86, 14, 42, 93, 97, 86, 28, 49,
58, 72, 81, 81, 35, 54, 68, 97, 91, 17, 32, 13, 69, 27, 8, 1, 76,
23, 82, 32, 49, 28, 13, 78, 92, 50, 36, 48, 68, 25, 79, 93, 30, 98,
7, 21, 57, 81, 21, 55, 94, 14, 52, 28, 76, 85, 10, 86, 67, 84, 86,
68, 96, 27, 33, 58, 49, 39, 38, 70, 38, 40, 97, 74, 71, 70, 34, 37,
13, 98, 36, 60, 80, 6, 7, 84, 58, 94, 23, 46, 24, 61, 26, 73, 88,
27, 86, 70, 43, 8, 76, 13, 73, 1, 4, 85, 93, 12, 78, 36, 49, 70,
59, 49, 30, 43, 17, 67, 31, 22, 71, 81, 12, 71, 68, 13, 25, 70, 62,
1, 86, 58, 89, 1, 21, 98, 68, 45, 96, 84, 34, 39, 58, 6, 92, 54,
0, 16, 1, 98, 7, 9, 70, 62, 76, 53, 49, 10, 45, 35, 83, 94, 80,
74, 73, 1, 86, 34, 33, 0, 49, 33, 43, 1, 78, 4, 78, 52, 84, 94,
48, 90, 18, 6, 17, 85, 66, 94, 68, 96, 61, 16, 36]),
array([114.8, 84.2, 163.4, 59. , 208.4, 109.4, 181.4, 122. , 41. ,
186.8, 57.2, 107.6, 199.4, 206.6, 186.8, 82.4, 120.2, 136.4,
161.6, 177.8, 177.8, 95. , 129.2, 154.4, 206.6, 195.8, 62.6,
89.6, 55.4, 156.2, 80.6, 46.4, 33.8, 168.8, 73.4, 179.6,
89.6, 120.2, 82.4, 55.4, 172.4, 197.6, 122. , 96.8, 118.4,
154.4, 77. , 174.2, 199.4, 86. , 208.4, 44.6, 69.8, 134.6,
177.8, 69.8, 131. , 201.2, 57.2, 125.6, 82.4, 168.8, 185. ,
50. , 186.8, 152.6, 183.2, 186.8, 154.4, 204.8, 80.6, 91.4,
136.4, 120.2, 102.2, 100.4, 158. , 100.4, 104. , 206.6, 165.2,
159.8, 158. , 93.2, 98.6, 55.4, 208.4, 96.8, 140. , 176. ,
42.8, 44.6, 183.2, 136.4, 201.2, 73.4, 114.8, 75.2, 141.8,
78.8, 163.4, 190.4, 80.6, 186.8, 158. , 109.4, 46.4, 168.8,
55.4, 163.4, 33.8, 39.2, 185. , 199.4, 53.6, 172.4, 96.8,
120.2, 158. , 138.2, 120.2, 86. , 109.4, 62.6, 152.6, 87.8,
71.6, 159.8, 177.8, 53.6, 159.8, 154.4, 55.4, 77. , 158. ,
143.6, 33.8, 186.8, 136.4, 192.2, 33.8, 69.8, 208.4, 154.4,
113. , 204.8, 183.2, 93.2, 102.2, 136.4, 42.8, 197.6, 129.2,
32. , 60.8, 33.8, 208.4, 44.6, 48.2, 158. , 143.6, 168.8,
127.4, 120.2, 50. , 113. , 95. , 181.4, 201.2, 176. , 165.2,
163.4, 33.8, 186.8, 93.2, 91.4, 32. , 120.2, 91.4, 109.4,
33.8, 172.4, 39.2, 172.4, 125.6, 183.2, 201.2, 118.4, 194. ,
64.4, 42.8, 62.6, 185. , 150.8, 201.2, 154.4, 204.8, 141.8,
60.8, 96.8]))# y = X * w + b
w = np.random.uniform(-1, 1)
b = np.random.uniform(-1, 1)
w, b
### 출력 결과
(-0.5903135321708077, 0.9315187221209935)
y_predict = X * w + b
y_predict
### 출력 결과
array([-26.22290376, -16.18757371, -42.16136913, -7.92318426,
-56.91920743, -24.45196316, -48.06450445, -28.58415789,
-2.02004894, -49.83544504, -7.33287073, -23.86164963,
-53.96763977, -56.3288939 , -49.83544504, -15.59726018,
-27.99384435, -33.30666614, -41.57105559, -46.88387738,
-46.88387738, -19.7294549 , -30.94541202, -39.20980147,
-56.3288939 , -52.78701271, -9.10381132, -17.95851431,
-6.7425572 , -39.800115 , -15.00694665, -3.79098954,
0.34120519, -43.93230972, -12.64569252, -47.47419092,
-17.95851431, -27.99384435, -15.59726018, -6.7425572 ,
-45.11293679, -53.37732624, -28.58415789, -20.31976844,
-27.40353082, -39.20980147, -13.82631958, -45.70325032,
-53.96763977, -16.77788724, -56.91920743, -3.200676 ,
-11.46506545, -32.71635261, -46.88387738, -11.46506545,
-31.53572555, -54.5579533 , -7.33287073, -29.76478495,
-15.59726018, -43.93230972, -49.24513151, -4.9716166 ,
-49.83544504, -38.61948793, -48.65481798, -49.83544504,
-39.20980147, -55.73858037, -15.00694665, -18.54882784,
-33.30666614, -27.99384435, -22.09070903, -21.5003955 ,
-40.39042853, -21.5003955 , -22.68102256, -56.3288939 ,
-42.75168266, -40.98074206, -40.39042853, -19.13914137,
-20.91008197, -6.7425572 , -56.91920743, -20.31976844,
-34.48729321, -46.29356385, -2.61036247, -3.200676 ,
-48.65481798, -33.30666614, -54.5579533 , -12.64569252,
-26.22290376, -13.23600605, -35.07760674, -14.41663311,
-42.16136913, -51.01607211, -15.00694665, -49.83544504,
-40.39042853, -24.45196316, -3.79098954, -43.93230972,
-6.7425572 , -42.16136913, 0.34120519, -1.42973541,
-49.24513151, -53.96763977, -6.15224366, -45.11293679,
-20.31976844, -27.99384435, -40.39042853, -33.89697968,
-27.99384435, -16.77788724, -24.45196316, -9.10381132,
-38.61948793, -17.36820078, -12.05537899, -40.98074206,
-46.88387738, -6.15224366, -40.98074206, -39.20980147,
-6.7425572 , -13.82631958, -40.39042853, -35.66792027,
0.34120519, -49.83544504, -33.30666614, -51.60638564,
0.34120519, -11.46506545, -56.91920743, -39.20980147,
-25.63259023, -55.73858037, -48.65481798, -19.13914137,
-22.09070903, -33.30666614, -2.61036247, -53.37732624,
-30.94541202, 0.93151872, -8.51349779, 0.34120519,
-56.91920743, -3.200676 , -4.38130307, -40.39042853,
-35.66792027, -43.93230972, -30.35509848, -27.99384435,
-4.9716166 , -25.63259023, -19.7294549 , -48.06450445,
-54.5579533 , -46.29356385, -42.75168266, -42.16136913,
0.34120519, -49.83544504, -19.13914137, -18.54882784,
0.93151872, -27.99384435, -18.54882784, -24.45196316,
0.34120519, -45.11293679, -1.42973541, -45.11293679,
-29.76478495, -48.65481798, -54.5579533 , -27.40353082,
-52.19669917, -9.69412486, -2.61036247, -9.10381132,
-49.24513151, -38.0291744 , -54.5579533 , -39.20980147,
-55.73858037, -35.07760674, -8.51349779, -20.31976844])plt.scatter(C, F)
plt.plot(X, y_predict, c='r')
### 출력 결과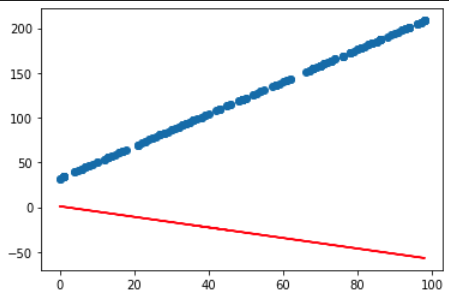
b = b - (y_predict - y).mean()
b
### 출력 결과
155.48359707194393# y = X * w + b
# 경사하강법 공식
# 업데이트할w : LearningRate * ((Y예측 - Y실제)*X)평균
# 업데이트할b : LearningRate * ((Y예측 - Y실제)*1)평균
w = w - ((y_predict - y) * X).mean()
w
### 출력 결과
10113.015284668909
y_predict = X * w + b
y_predict
### 출력 결과
array([4.65354187e+05, 2.93432927e+05, 7.38405599e+05, 1.51850713e+05,
9.91230981e+05, 4.35015141e+05, 8.39535752e+05, 5.05806248e+05,
5.07205600e+04, 8.69874798e+05, 1.41737698e+05, 4.24902126e+05,
9.40665905e+05, 9.81117966e+05, 8.69874798e+05, 2.83319912e+05,
4.95693233e+05, 5.86710370e+05, 7.28292584e+05, 8.19309722e+05,
8.19309722e+05, 3.54111019e+05, 5.46258309e+05, 6.87840523e+05,
9.81117966e+05, 9.20439875e+05, 1.72076743e+05, 3.23771973e+05,
1.31624682e+05, 6.97953538e+05, 2.73206896e+05, 8.10596059e+04,
1.02684989e+04, 7.68744645e+05, 2.32754835e+05, 8.29422737e+05,
3.23771973e+05, 4.95693233e+05, 2.83319912e+05, 1.31624682e+05,
7.88970676e+05, 9.30552890e+05, 5.05806248e+05, 3.64224034e+05,
4.85580217e+05, 6.87840523e+05, 2.52980866e+05, 7.99083691e+05,
9.40665905e+05, 3.03545942e+05, 9.91230981e+05, 7.09465906e+04,
2.12528805e+05, 5.76597355e+05, 8.19309722e+05, 2.12528805e+05,
5.56371324e+05, 9.50778920e+05, 1.41737698e+05, 5.26032278e+05,
2.83319912e+05, 7.68744645e+05, 8.59761783e+05, 1.01285636e+05,
8.69874798e+05, 6.77727508e+05, 8.49648768e+05, 8.69874798e+05,
6.87840523e+05, 9.71004951e+05, 2.73206896e+05, 3.33884988e+05,
5.86710370e+05, 4.95693233e+05, 3.94563080e+05, 3.84450064e+05,
7.08066554e+05, 3.84450064e+05, 4.04676095e+05, 9.81117966e+05,
7.48518615e+05, 7.18179569e+05, 7.08066554e+05, 3.43998003e+05,
3.74337049e+05, 1.31624682e+05, 9.91230981e+05, 3.64224034e+05,
6.06936401e+05, 8.09196706e+05, 6.08335753e+04, 7.09465906e+04,
8.49648768e+05, 5.86710370e+05, 9.50778920e+05, 2.32754835e+05,
4.65354187e+05, 2.42867850e+05, 6.17049416e+05, 2.63093881e+05,
7.38405599e+05, 8.90100829e+05, 2.73206896e+05, 8.69874798e+05,
7.08066554e+05, 4.35015141e+05, 8.10596059e+04, 7.68744645e+05,
1.31624682e+05, 7.38405599e+05, 1.02684989e+04, 4.06075447e+04,
8.59761783e+05, 9.40665905e+05, 1.21511667e+05, 7.88970676e+05,
3.64224034e+05, 4.95693233e+05, 7.08066554e+05, 5.96823385e+05,
4.95693233e+05, 3.03545942e+05, 4.35015141e+05, 1.72076743e+05,
6.77727508e+05, 3.13658957e+05, 2.22641820e+05, 7.18179569e+05,
8.19309722e+05, 1.21511667e+05, 7.18179569e+05, 6.87840523e+05,
1.31624682e+05, 2.52980866e+05, 7.08066554e+05, 6.27162431e+05,
1.02684989e+04, 8.69874798e+05, 5.86710370e+05, 9.00213844e+05,
1.02684989e+04, 2.12528805e+05, 9.91230981e+05, 6.87840523e+05,
4.55241171e+05, 9.71004951e+05, 8.49648768e+05, 3.43998003e+05,
3.94563080e+05, 5.86710370e+05, 6.08335753e+04, 9.30552890e+05,
5.46258309e+05, 1.55483597e+02, 1.61963728e+05, 1.02684989e+04,
9.91230981e+05, 7.09465906e+04, 9.11726212e+04, 7.08066554e+05,
6.27162431e+05, 7.68744645e+05, 5.36145294e+05, 4.95693233e+05,
1.01285636e+05, 4.55241171e+05, 3.54111019e+05, 8.39535752e+05,
9.50778920e+05, 8.09196706e+05, 7.48518615e+05, 7.38405599e+05,
1.02684989e+04, 8.69874798e+05, 3.43998003e+05, 3.33884988e+05,
1.55483597e+02, 4.95693233e+05, 3.33884988e+05, 4.35015141e+05,
1.02684989e+04, 7.88970676e+05, 4.06075447e+04, 7.88970676e+05,
5.26032278e+05, 8.49648768e+05, 9.50778920e+05, 4.85580217e+05,
9.10326859e+05, 1.82189759e+05, 6.08335753e+04, 1.72076743e+05,
8.59761783e+05, 6.67614492e+05, 9.50778920e+05, 6.87840523e+05,
9.71004951e+05, 6.17049416e+05, 1.61963728e+05, 3.64224034e+05])epoch = 200000
learning_rate = 0.0003
# y = X * w + b
w = np.random.uniform(-1, 1)
b = np.random.uniform(-1, 1)
for e in range(epoch):
y_predict = X * w + b
w = w - learning_rate * ((y_predict - y) * X).mean() ### gdW : update gradient
b = b - learning_rate * (y_predict - y).mean() ### gdb : gradient discent b
if e % 1000 == 0:
# plt.scatter(C, F)
# plt.plot(X, y_predict, c='r')
print(f"{e}, w = {w: .6f}, b = {b: .6f}")
plot_prediction(y_predict, y)위 코드를 통해 epoch의 값 만큼 학습을 시키면서 결과값을 봤을때 대략 160000번째 부터 근사치의 값을 찾는것을 볼 수 있다.
방법2) tensorflow 사용
tensorflow는 적용이 안 될 수도 있으니, 해당 코드로 적용이 되는지 확인해보면 된다.
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy
def x_norm(x): # x값을 Normalization (이유: 학습을 빠르게 하고 학습과정 중 발산(양 또는 음의 무한대)을 피하기 위함)
x = numpy.array(x) # 리스트형태, 스칼라형태 관계없이 처리하기 위해 변환
x = x / 100 * 0.99 + 0.01
return x
# (요소값 - 최소값) / (최대값 - 최소값) * 0.99 + 0.01
# 최소값 0, 최대값 100 가정
# 섭씨와 화씨를 관찰하여 입력한다.
# 12.0 -> 53.6
# 28.0 -> 82.4
# 36.5 -> 97.7
# 42.0 -> 107.6
# 29.8 -> 85.64
# 섭씨를 입력하면 화씨로 변환하고자 한다.
# 답을 살짝 알려주면 F = 1.8 * C + 32 이다.
x = [12.0, 28.0, 36.5, 42.0, 29.8] # 섭씨(C) 입력
x = x_norm(x)
y = [53.6, 82.4, 97.7, 107.6, 85.64] # 화씨(F) 출력(=Target)
# random_uniform(shape, minval=0, maxval=None, dtype=tf.float32, seed=None, name=None)
# minval ~ maxval 사이의 숫자를 균등분포로 랜덤하게 생성한다.
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0), name="Weight") # 가중치(Weight) 변수
print(W)
b = tf.Variable(tf.random_uniform([1], -1.0, 1.0), name="Bias") # 편향(Bias) 변수
print(b)
X = tf.placeholder(tf.float32, name="X")
Y = tf.placeholder(tf.float32, name="Y")
hypothesis = tf.add( tf.multiply(W, X), b ) # 여기서 입력 값 1개와 가중치 1개씩 트레이닝에 이용되므로 요소간 곱셉 이용
# hypothesis = W * X + b # 위 표현식과 정확히 같다.
# tf.multiply는 요소간 곱셉이다.
# tf.matmul는 행렬 곱셈이다. 즉 내적(dot product)으로 그 차이점을 잘 알아두어야 한다.
# tf.matmul로 바꾸면 "Shape must be rank 2" 오류가 발생한다. 실제 W는 [1]으로 rank 1이므로 사용하지 못한다.
# 2개 이상의 Feature를 이용한 경우부터 사용가능하다.
print(hypothesis)
optimizer = tf.train.GradientDescentOptimizer(learning_rate = 0.3) # 경사하강법(Gradient Descent) 사용
cost = tf.reduce_mean( tf.square(Y - hypothesis)) # 실제값에서 가정값의 차이에 제곱한 값들의 평균값을 비용으로 정의
train_op = optimizer.minimize(cost) # 비용(=오류총합)를 최소화하도록 최적화
with tf.Session() as sess: # 세션 블록 생성
sess.run(tf.global_variables_initializer())
print(sess.run(W), sess.run(b))
for step in range(10000):
_, cost_val = sess.run([train_op, cost], feed_dict={X: x, Y: y})
print("Step: ", step, " Cost: ", cost_val, " W: ", sess.run(W), " b: ", sess.run(b))
print("X: 20, Y:", sess.run(hypothesis, feed_dict={X: x_norm(20)}))
print("X: 30, Y:", sess.run(hypothesis, feed_dict={X: x_norm(30)}))
print("X: 40, Y:", sess.run(hypothesis, feed_dict={X: x_norm(40)}))
print("X: 50, Y:", sess.run(hypothesis, feed_dict={X: x_norm(50)}))
print("X: 60, Y:", sess.run(hypothesis, feed_dict={X: x_norm(60)}))