1. Collaborative Filtering (협업필터링)
협업 필터링이란?
협업 필터링(Collaborative Filtering)은 추천 시스템(Recommendation System)에서 사용되는 기법 중 하나로, 사용자들의 행동이나 기호를 기반으로 아이템(상품, 영화 등)을 추천하는 방법론.
협업 필터링은 사용자와 아이템 간의 상호 작용 데이터(평가, 구매 이력 등)를 분석하여 유사한 취향을 가진 사용자들이 선호한 아이템을 추천.
종류
1. 메모리 기반 협업 필터링 (Memory-Based Collaborative Filtering):
- 사용자 기반 협업 필터링 (User-Based Collaborative Filtering):
비슷한 취향을 가진 사용자들의 평가 패턴을 분석하여 사용자가 아직 평가하지 않은 아이템에 대한 평점을 예측.- 아이템 기반 협업 필터링 (Item-Based Collaborative Filtering):
비슷한 아이템들이 같이 평가되는 경향을 분석하여 사용자가 평가한 아이템과 유사한 아이템들을 추천.2. 모델 기반 협업 필터링 (Model-Based Collaborative Filtering):
- 머신 러닝과 같은 모델을 사용하여 사용자와 아이템 간의 관계를 학습하고 예측.
대표적인 방법으로는 잠재 요인 협업 필터링(Latent Factor Collaborative Filtering)이 있음.
작동 원리
- 사용자 행동 데이터 수집: 사용자들의 아이템에 대한 평가, 구매, 클릭 등의 데이터를 수집.
- 사용자-아이템 매트릭스 생성: 수집된 데이터를 바탕으로 사용자와 아이템 간의 상호 작용을 행렬 형태로 표현.
이 매트릭스는 사용자-아이템 평가 행렬이라고도 함.
- 유사도 계산: 사용자 기반 협업 필터링에서는 사용자들 간의 유사도를 계산하고, 아이템 기반 협업 필터링에서는 아이템들 간의 유사도를 계산.
유사도는 주로 코사인 유사도, 피어슨 상관계수 등을 사용.
- 평점 예측: 유사도를 기반으로 예측하고자 하는 사용자가 아직 평가하지 않은 아이템에 대한 평점을 예측.
- 추천 제공: 예측된 평점을 기반으로 사용자에게 가장 높은 평점을 예측한 아이템을 추천.
사용 예시
- 영화 추천 시스템: 사용자들이 영화에 대한 평가를 기반으로 비슷한 취향을 가진 다른 사용자들이 좋아한 영화를 추천.
- 음악 스트리밍 서비스: 사용자가 들은 음악을 기반으로 비슷한 음악을 추천.
- 온라인 쇼핑 사이트: 사용자의 구매 이력을 기반으로 비슷한 쇼핑 패턴을 가진 사용자들이 선호한 상품을 추천.
장점
- 개인화된 추천: 사용자 개별의 취향과 관심에 맞춘 추천을 제공.
- 상호 작용 데이터만 필요: 사용자의 프로파일 정보 없이도 효과적인 추천을 할 수 있음.
한계
- 냉장 효과(Cold Start): 새로 가입한 사용자나 새로 출시된 아이템에 대한 추천이 어려울 수 있음.
- 저평가 문제: 일반적으로 긍정적인 평가가 많은 아이템에 대한 추천이 쉽지 않을 수 있음.
import numpy as np
import pandas as pd
file = "data/ratings.csv"
data = pd.read_csv(file)
data.info()
### 출력 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 23 entries, 0 to 22
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 사람 23 non-null object
1 책 23 non-null object
2 평점 23 non-null float64
dtypes: float64(1), object(2)
memory usage: 680.0+ bytes
data.head()
### 출력 결과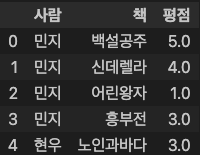
set(data['사람'].to_list())
### 출력 결과
{'민수', '민지', '지민', '지연', '현우'}
set(data['책'].to_list())
### 출력 결과
{'노인과바다', '백설공주', '신데렐라', '어린왕자', '콩쥐팥쥐', '흥부전'}
ratings = pd.pivot_table(data, index="사람", columns="책", values="평점").sort_values(by='노인과바다', ascending=True)
ratings
### 출력 결과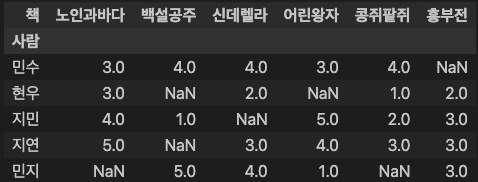
Cosine Similarity
코사인 유사도란?
코사인 유사도(Cosine Similarity)는 벡터 간의 유사도를 계산하는 방법 중 하나로, 주로 문서나 다차원 공간에서 벡터 간의 방향적 유사성을 측정하는 데 사용됨.
특히 자연어 처리와 정보 검색 분야에서 문서 간 유사도를 계산하는 데 널리 사용.
코사인 유사도의 개념
코사인 유사도는 두 벡터 사이의 각도를 이용하여 유사성을 측정하는 방법.
벡터 A와 벡터 B가 주어졌을 때, 이들 벡터 사이의 각도가 작을수록 코사인 유사도는 1에 가까워지며, 각도가 클수록 0에 가까워짐.
따라서 코사인 유사도는 벡터의 방향이나 크기에 상관없이 두 벡터가 얼마나 유사한 방향을 가지고 있는지를 측정함.
수식
- : 벡터 A와 B의 내적 (dot product)
- : 벡터 A의 크기 (norm)
- : 벡터 B의 크기 (norm)
내적 은 벡터 A와 B가 얼마나 비슷한 방향을 가지고 있는지를 나타내며,
각 벡터의 크기 와 는 각각 벡터의 길이를 고려함.
특징
- 벡터의 방향성: 코사인 유사도는 벡터의 방향에 따른 유사성을 측정하기 때문에 벡터의 크기에 민감하지 않음.
따라서 벡터의 크기가 다를 경우에도 코사인 유사도는 정확한 방향성 비교를 가능하게함.- 벡터 정규화: 코사인 유사도를 계산하기 전에는 보통 벡터를 정규화(normalize)하여 길이를 1로 만들어줌.
이는 각 벡터의 크기가 유사성 측정에 영향을 미치지 않도록 하기 위함.
적용 예시
- 문서 유사도: 문서의 특성을 벡터로 표현한 후, 코사인 유사도를 계산하여 문서 간 유사성을 평가.
이를 통해 비슷한 주제나 내용을 가진 문서를 찾거나 추천할 수 있음.- 추천 시스템: 사용자나 상품을 특성 벡터로 표현한 후, 사용자의 선호도를 기반으로 유사한 사용자나 상품을 추천.
- 이미지 처리: 이미지 특징을 벡터로 표현한 후, 비슷한 이미지를 찾거나 이미지 검색을 개선하는 데 사용될 수 있음.
np.array([1,np.nan,3]+[4,5,6])
### 출력 결과
array([ 1., nan, 3., 4., 5., 6.])u = np.array([1,np.nan,3])
v = np.array([4,5,6])
print( u, v )
### 출력 결과
[ 1. nan 3.] [4 5 6]print( u, v )
print(u + v)
### 출력 결과
[ 1. nan 3.] [4 5 6]
[ 5. nan 9.]print( u, v )
print( u - v )
### 출력 결과
[ 1. nan 3.] [4 5 6]
[-3. nan -3.]print( u, v )
print( u * v )
### 출력 결과
[ 1. nan 3.] [4 5 6]
[ 4. nan 18.]print( u,)
print( u ** 2 )
### 출력 결과
[ 1. nan 3.]
[ 1. nan 9.]print(u)
print( (u ** 2).sum() )
### 출력 결과
[ 1. nan 3.]
nanprint( u )
print(np.isnan(u))
### 출력 결과
[ 1. nan 3.]
[False True False]print( u )
print(np.isfinite(u)) # not NaN(Not a Number) 찾기 -> 숫자만 골라내기
### 출력 결과
[ 1. nan 3.]
[ True False True]print( v )
print(np.isfinite(v))
### 출력 결과
[4 5 6]
[ True True True]print( u, v )
print(np.isfinite(u) & np.isfinite(v)) # Boolean(T/F) 값을 찾기
### 출력 결과
[ 1. nan 3.] [4 5 6]
[ True False True]print( u, v )
print(v[np.isfinite(u) & np.isfinite(v)]) # T/F 기준으로 데이터value 구하기
### 출력 결과
[ 1. nan 3.] [4 5 6]
[4 6]# 그래프 출력 함수
import numpy as np
import matplotlib.pyplot as plt
def plot_vectors(u, v, title):
# 두 벡터의 내적과 크기 계산
uvdot = np.dot(u, v)
norm_u = np.linalg.norm(u)
norm_v = np.linalg.norm(v)
# 코사인 유사도 계산
cosine_similarity = uvdot / (norm_u * norm_v)
# 두 벡터 사이의 각도 계산 (라디안)
angle = np.arccos(cosine_similarity)
# 그래프 그리기
plt.figure(figsize=(8, 8))
plt.quiver(0, 0, u[0], u[1], angles='xy', scale_units='xy', scale=1, color='r', label='u')
plt.quiver(0, 0, v[0], v[1], angles='xy', scale_units='xy', scale=1, color='b', label='v')
# 벡터의 끝점을 원으로 표시
plt.scatter(u[0], u[1], color='r')
plt.scatter(v[0], v[1], color='b')
# 벡터의 끝점을 이어주는 선을 그리기
plt.plot([u[0], 0, v[0]], [u[1], 0, v[1]], linestyle='--', color='gray')
# 각도 표시
plt.text(0.5, 0.5, f"θ = {np.degrees(angle):.2f}°", fontsize=12, color='k')
# 축 설정
plt.xlim(-1, 3)
plt.ylim(-1, 3)
plt.axhline(0, color='gray', lw=0.5)
plt.axvline(0, color='gray', lw=0.5)
plt.grid()
plt.legend()
plt.title(f'{title}\nCosine Similarity: {cosine_similarity:.2f}')
plt.gca().set_aspect('equal', adjustable='box')
# 그래프 표시
plt.show()def get_cosine_similarity(u, v):
mask = np.isfinite(u) & np.isfinite(v)
u = u[mask]
v = v[mask]
uvdot = (u * v).sum()
norm1 = (u ** 2).sum()
norm2 = (v ** 2).sum()
score = uvdot / np.sqrt(norm1 * norm2)
plot_vectors(u, v, 'test')
return score
u = np.array([np.nan, 4, 3])
v = np.array([3, 2, 4])
print(u, v)
### 출력 결과
[nan 4. 3.] [3 2 4]
get_cosine_similarity(u, v)
### 출력 결과
0.8944271909999159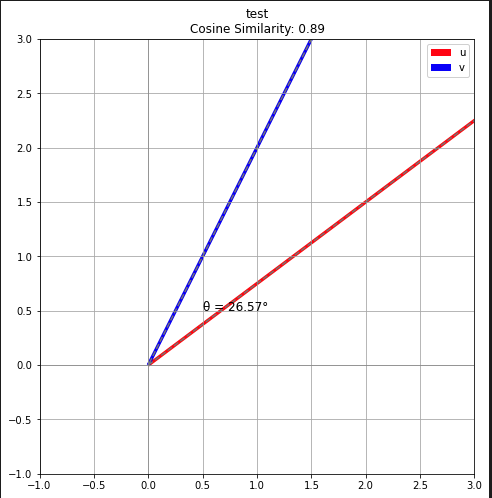
ratings
### 출력 결과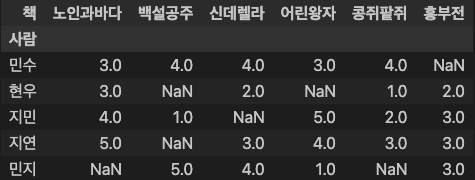
u = ratings.loc["민수"]
v = ratings.loc["민지"]
u, v
### 출력 결과
(책
노인과바다 3.0
백설공주 4.0
신데렐라 4.0
어린왕자 3.0
콩쥐팥쥐 4.0
흥부전 NaN
Name: 민수, dtype: float64,
책
노인과바다 NaN
백설공주 5.0
신데렐라 4.0
어린왕자 1.0
콩쥐팥쥐 NaN
흥부전 3.0
Name: 민지, dtype: float64)get_cosine_similarity(u, v)
### 출력 결과
0.8944271909999159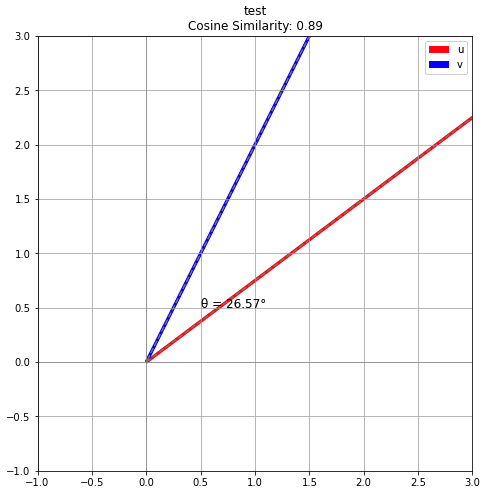
전체 사용자 코사인 유사도 구하기
from itertools import productitertools & product
파이썬의 itertools 모듈은 효율적이고 메모리 친화적인 반복자(iterator)들을 생성하는 데 유용한 함수들을 제공하는 표준 라이브러리이다.
이 모듈에는 다양한 반복자 함수가 포함되어 있으며, 그 중 product 함수는 데카르트 곱(Cartesian product)을 생성하는 데 사용된다.
itertools 모듈
itertools 모듈은 반복(iterable) 가능한 객체를 처리하기 위한 함수들을 제공한다.
이 모듈의 함수들은 반복 가능한 객체를 받아들이고, 이터레이터를 반환한다.
이러한 함수들을 사용하면 코드가 더 간결하고 효율적으로 작성될 수 있다.
itertools.product
itertools.product 함수는 입력 반복자들의 데카르트 곱을 반환한다.
데카르트 곱은 주어진 여러 반복자들의 모든 가능한 조합을 생성한다.
이는 중첩된 루프를 통해 쉽게 이해할 수 있다.
itertools 모듈의 다른 유용한 함수들
- count(start, step): start부터 step 간격으로 무한히 증가하는 값을 생성.
- cycle(iterable): 주어진 반복자를 무한히 순환.
- repeat(object, times): 주어진 객체를 지정된 횟수만큼 반복.
- chain(*iterables): 여러 반복자를 하나의 반복자로 연결.
- islice(iterable, start, stop, step): 슬라이싱을 지원하는 이터레이터를 반환.
- combinations(iterable, r): 주어진 반복자에서 r개의 요소로 이루어진 조합을 생성.
- permutations(iterable, r): 주어진 반복자에서 r개의 요소로 이루어진 순열을 생성.
list(product(ratings.index, repeat=2))
### 출력 결과
[('민수', '민수'),
('민수', '현우'),
('민수', '지민'),
('민수', '지연'),
('민수', '민지'),
('현우', '민수'),
('현우', '현우'),
('현우', '지민'),
('현우', '지연'),
('현우', '민지'),
('지민', '민수'),
('지민', '현우'),
('지민', '지민'),
('지민', '지연'),
('지민', '민지'),
('지연', '민수'),
('지연', '현우'),
('지연', '지민'),
('지연', '지연'),
('지연', '민지'),
('민지', '민수'),
('민지', '현우'),
('민지', '지민'),
('민지', '지연'),
('민지', '민지')]
print(len(list(product(ratings.index, repeat=2))))
### 출력 결과
25
ratings
### 출력 결과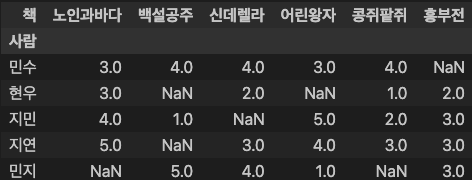
from itertools import product
def get_cosine_similarity_table(ratings):
index_combinations = list(product(ratings.index, repeat=2))
similarity_list = []
for uname, vname in index_combinations:
u = ratings.loc[uname]
v = ratings.loc[vname]
score = get_cosine_similarity(u, v)
similarity = {
'u': uname,
'v': vname,
'score': score
}
similarity_list.append(similarity)
similarity_list = pd.DataFrame(similarity_list)
similarity_table = pd.pivot_table(similarity_list, index='u', columns='v', values='score')
return similarity_table
similarity_table = get_cosine_similarity_table(ratings)
similarity_table
### 출력 결과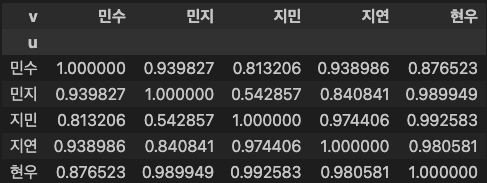
해당 함수를 통해 모든 사용자의 코사인 유사도를 구해봤다.
자기 자신은 1이며 0 ~ 1까지 유사도가 높을수록 1에 가깝다.
평점 예측하기
코사인 유사도를 통해, 평점을 넣지 않은 유저의 평점을 예측해보자.
ratings
### 출력 결과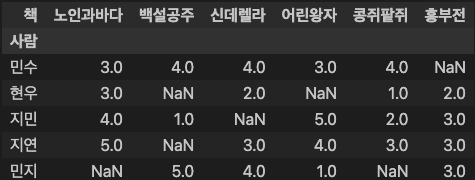
user_name = "민지"
book_name = "노인과바다"
ratings[book_name].drop(index = user_name)
### 출력 결과
사람
민수 3.0
현우 3.0
지민 4.0
지연 5.0
Name: 노인과바다, dtype: float64
ratings[book_name].drop(index = user_name).sort_index() # 자신의 것은 제외시킴
### 출력 결과
사람
민수 3.0
지민 4.0
지연 5.0
현우 3.0
Name: 노인과바다, dtype: float64
similarity_table[user_name].drop(index = user_name).sort_index()
### 출력 결과
u
민수 0.939827
지민 0.542857
지연 0.840841
현우 0.989949
Name: 민지, dtype: float64
neighbors_ratings = ratings[book_name].drop(index = user_name).sort_index() # 자신의 것은 제외시킴
neighbors_similarity = similarity_table[user_name].drop(index = user_name).sort_index()neighbors_ratings
필자도 해당 수식은 이해했으나, 왜 해당 수식을 사용 해야 하는지는 이해 못했었다.
필자가 이해한 부분에 대해 서술하자면.
= 우리가 원하는 평점이 없는 사람의 평점.
모든 유저의 ( : 코사인 유사도) * ( : 평점)을 더해준 다음, 모든 유저의 코사인 유사도의 합으로 나눠주면 우리가 원하는 값이 나온다는 것이다.{() + () + () + ()} () = () = 우리가 원하는 평점
이렇게 되는 것이다.
neighbors_similarity
### 출력 결과
u
민수 0.939827
지민 0.542857
지연 0.840841
현우 0.989949
Name: 민지, dtype: float64
neighbors_ratings
### 출력 결과
사람
민수 3.0
지민 4.0
지연 5.0
현우 3.0
Name: 노인과바다, dtype: float64
#분자
nominator = (neighbors_similarity * neighbors_ratings).sum()
nominator
### 출력 결과
12.16496376725352
#분모
denominator = neighbors_similarity.sum()
denominator
### 출력 결과
3.3134748798018654def predict_rating_test(user_name, book_name):
neighbors_ratings = ratings[book_name].drop(index = user_name).sort_index() # 자신의 것은 제외시킴
neighbors_similarity = similarity_table[user_name].drop(index = user_name).sort_index()
nominator = (neighbors_similarity * neighbors_ratings).sum()
denominator = np.sqrt(((neighbors_similarity ** 2).sum()) * ((neighbors_ratings ** 2).sum()))
score = nominator / denominator
return score
predict_rating("민지", "노인과바다")
### 출력 결과
predict_rating("현우", "백설공주")
### 출력 결과
2.4607597343308854평점 테이블
ratings.index
### 출력 결과
Index(['민수', '현우', '지민', '지연', '민지'], dtype='object', name='사람')
ratings.columns
### 출력 결과
Index(['노인과바다', '백설공주', '신데렐라', '어린왕자', '콩쥐팥쥐', '흥부전'], dtype='object', name='책')
print(len(list(product(ratings.index, ratings.columns))))
### 출력 결과
30
list(product(ratings.index, ratings.columns))
### 출력 결과
[('민수', '노인과바다'),
('민수', '백설공주'),
('민수', '신데렐라'),
('민수', '어린왕자'),
('민수', '콩쥐팥쥐'),
('민수', '흥부전'),
('현우', '노인과바다'),
('현우', '백설공주'),
('현우', '신데렐라'),
('현우', '어린왕자'),
('현우', '콩쥐팥쥐'),
('현우', '흥부전'),
('지민', '노인과바다'),
('지민', '백설공주'),
('지민', '신데렐라'),
('지민', '어린왕자'),
('지민', '콩쥐팥쥐'),
('지민', '흥부전'),
('지연', '노인과바다'),
('지연', '백설공주'),
('지연', '신데렐라'),
('지연', '어린왕자'),
('지연', '콩쥐팥쥐'),
('지연', '흥부전'),
('민지', '노인과바다'),
('민지', '백설공주'),
('민지', '신데렐라'),
('민지', '어린왕자'),
('민지', '콩쥐팥쥐'),
('민지', '흥부전')] def predict_rating_table(ratings):
user_book_combinations = list(product(ratings.index, ratings.columns))
rating_list = []
for user_name, book_name in user_book_combinations:
score = predict_rating(user_name, book_name)
rating_predict = {
'user': user_name,
'book': book_name,
'score': score
}
rating_list.append(rating_predict)
rating_list = pd.DataFrame(rating_list)
rating_table = pd.pivot_table(rating_list, index='user', columns='book', values='score')
rating_table = rating_table[ratings.isnull()]
return rating_tableratings.sort_index()
### 출력 결과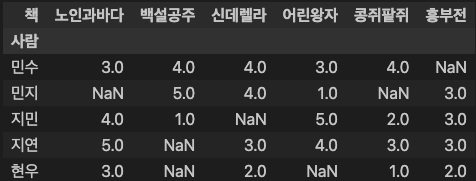
rating_table = predict_rating_table(ratings)
rating_table
### 출력 결과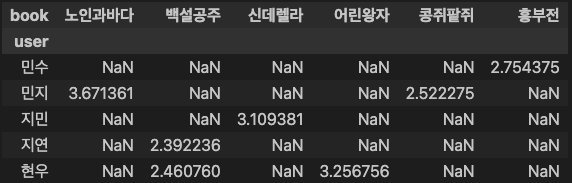
2. 사용자 기반 & 아이템 기반 협업 필터링
를 사용자 가 상품 에 내린 ratings, 를 사용자 와 사용자 가 모두 평가한 상품 집합, 를 상품 와 상품 를 모두 평가한 사용자 집합이라고 표기하겠습니다.
Calculate Sim ilarity
사용자 기반(User-based) 기법
- 사용자 "민지"와 나머지 모든 사용자의 유사도를 연산합니다. "민지"-"현우", "민지"-"민수", "민지"-"지민", "민지"-"지연"의 유사도를 연산합니다.
사용자 유사도 현우 0.7261 민수 0.9547 지민 0.5985 지연 0.8541 상품 기반 (Item-based) 기법
- 상품 "노인과바다"와 나머지 모든 상품의 유사도를 연산합니다. "노인과바다"-"백설공주", "노인과바다"-"신데렐라", "노인과바다"-"어린왕자", "노인과바다"-"콩쥐팥쥐", "노인과바다"-"흥부전"의 유사도를 연산합니다.
그렇다면 임의의 두 사용자 혹은 임의의 두 상품, 즉 두 값이 얼마나 유사한지를 어떻게 판단할 수 있을까요? 우리가 알고 있는 가장 대표적인 방법으로 두 데이터가 얼마나 가까운지를 유클리디안 거리(Euclidean Distance)를 활용하여 측정해볼 수도 있습니다. 이 외에도 다양한 유사도 메트릭을 사용하여 유사한 정도를 파악하는 것이 가능합니다. 주로 유사도 측정을 위하여 피어슨 상관계수(Pearson Correlation Coefficient), 스피어만 순위 상관계수(Sprearman Rank Correlation Coefficient), 켄달의 타우(Kendall's Tau), 코사인 유사도(Cosine Similarity), 자카드 유사도(Jaccard Coefficient) 등을 활용합니다. 여기서는 자주 쓰이는 피어슨 상관계수(Pearson Correlation Coefficient)에 대하여 더 자세하게 알아보고 이를 직접 구현해보겠습니다.
상품 유사도 백설공주 0.7761 신데렐라 0.8794 어린왕자 0.9830 콩쥐팥쥐 0.9032 흥부전 0.9949
Pearson Correlation Coefficient
피어슨 상관계수는 Collaborative Filtering에서 유사도 측정 메트릭으로 주로 사용되며, 두 벡터의 선형 상관관계를 확인하기 위해 사용됩니다.
식으로 표현하자면 아래와 같습니다.피어슨 상관계수는 +1과 -1 사이의 값을 갖습니다.
+1에 가까울수록 강한 양의 선형 상관관계가 있다는 것을 의미하고 -1에 가까울수록 강한 음의 선형 상관관계가 있다는 것을 의미합니다.
또한 0은 아무런 선형 상관관계가 없음을 뜻합니다.
상품 와 상품 의 피어슨 상관계수는 아래와 같이 정의할 수 있습니다.또한 사용자 와 사용자 의 피어슨 상관계수는 아래와 같이 정의할 수 있습니다.
Average Correction
유사한 상품/사용자에 더 큰 가중치를 주어 특정 상품에 대한 사용자의 ratings 값을 예측합니다.
유사도에 따라 ratings에 유사도가 높은 k개의 상품에 내려진 ratings의 평균/유사도가 높은 k명의 사용자가 내린 ratings의 평균을 뺀 값의 가중 평균을 구합니다.
이 값에 상품에 내린 ratings 값/사용자가 내린 ratings 값의 평균을 최종적으로 더하여 예측합니다.
상품/사용자가 받거나 하는 ratings 특성을 더 잘 반영합니다.
사용자 기반(사용자-based) 기법
- 특정 유사도 메트릭에 따라 사용자 와 유사한 k명(혹은 이하)의 이웃을 결정합니다.
- 유사한 k명의 사용자가 상품 에 내린 ratings에 각각 k명의 사용자가 내린 ratings의 평균을 뺀 값에 대해 유사도에 따른 가중 평균을 구합니다.
- 사용자 이 내린 ratings 값의 평균을 더하여 값을 보정해줍니다.
상품 기반(상품-based) 기법
- 특정 유사도 메트릭에 따라 상품 와 유사한 k개(혹은 이하)의 상품을 결정합니다.
- 유사한 k개의 상품에 내린 사용자 의 ratings에 각각 k개의 상품에 내려진 ratings의 평균을 뺀 값에 대해 유사도에 따른 가중 평균을 구합니다.
- 상품 에 내려진 ratings 값의 평균을 더하여 값을 보정해줍니다.
