✔ STL
- STL 은 모두 컨테이너로 정의되어 있음
- STL 은 개념적으로 크게 4개 라이브러리로 나뉨
- 컨테이너 라이브러리 : array, vector, stack, queue, deque, list, forward_list, set, unordered_set, map, unordered_map
- 반복자 라이브러리 : 라이브러리에는 iterator 가 정의되어 있음. iterator 는 포인터처럼 동작하는 객체로, 객체 순차열 참조 할 때 사용
- 알고리즘 라이브러리
- 수치 라이브러리 (numerical processing)
✔ 컨테이너
- 컨테이너 : 객체를 일정한 방식으로 저장하고 조직화하는 객체. 컨테이너를 사용한다는 건 데이터에 접근하기 위해 반드시 반복자를 사용한다는 것
- 순차 컨테이너 (sequence container) : 객체들을 선형으로 저장. 멤버 함수를 호출하거나 반복자로 객체들을 차례로 접근 가능. 또한 경우에 따라서 첨자 연산자와 인덱스를 사용해 접근 가능. vector, list, deque 3개가 있음.
- 연관 컨테이너 (associative container) : 객체들을 연관된 키와 함께 저장. 키나 반복자를 이용해서 객체를 가져 옴.
- 컨테이너 어뎁터 (Container adapter) : Container 위에서 돌아가는 자료 구조 (보통 vector 로 구현됨)
Stack,que,priority_queue - ✨ 이 컨테이너 별 작업에 따라 속도차가 매우 크기 때문에, 적절한 컨테이너를 고르는게 중요!!
✔ 반복자
- 컨테이너 원소에 접근 할 수 있는 포인터와 같은 객체. 알고리즘 라이브러리는 대부분 반복자를 인자로 받음.
- 각 타입에
:iterator또는:const_iterator뒤에 붙여주면 사용 가능 - 포인터와 비슷하게 사용
- 간접 참조 가능 :
itr = v.begin() + 2에서*itr간접 참조 하면 세번째 원소 값 return
- 간접 참조 가능 :
- 초기 화 :
itr = container.begin()컨테이너이름.begin() 하면 첫번째 원소 iterator 리턴
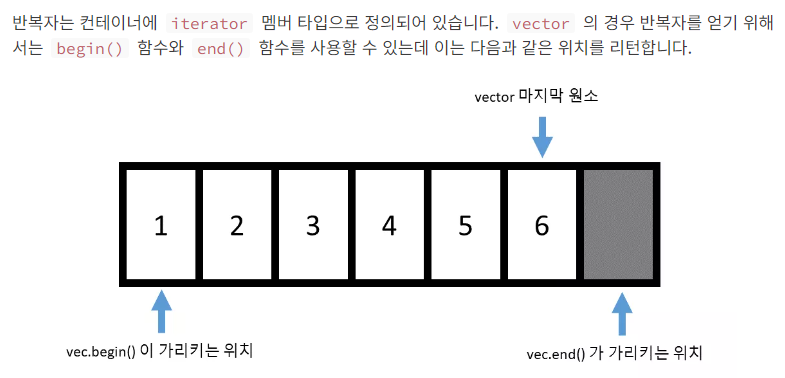
vector 에서의 사용 예시
- itr = container.begin();
- 첫번째 주소를 받아
- while (itr != container.end())
- 반복자가 끝까지 다 돌때까지.
- *itr
- 반복자가 가리키는 원소를 이용한 후 (간접참조같이)
- ++itr 다음 반복자.
#include <iostream>
#include <vector>
#include <list>
#include <set>
#include <map>
using namespace std;
int main()
{
vector<int> container;
for (int i = 0; i < 10; ++i)
container.push_back(i);
vector<int>::const_iterator itr;
itr = container.begin();
while (itr != container.end())
{
cout << *itr << " ";
++itr;
}
}시퀀스 컨테이너 (Sequence container)
🎉Vector
- element 가 index 를 가지고 선형으로 배열되어 있는 Sequence container
- Sequence Container 이므로
- index 로 원소 참조 가능, O(1) 시간 소요
- 순서대로 접근 가능, O(N) 시간 소요 (원소를 1칸씩 이동시켜줘야 해서 n 번 복사 필요)
- 동적 배열로 구현되어 있음
- 일반적인 상황은 거의 벡터로 구현 (거의 만능!)
list와 다르게 원소들이 메모리에 연속적으로 존재정적 배열과 다르게 스스로 공간 할당 및 크기 확장/축소 할 수 있고, 좀 더 여유 있게 할당 받기 때문에 메모리 필요량이 좀 더 높음- 원소 중간 삽입은
deque,list보다 느림. 다만 끝에 삽입하는 것은vector가 더 효율적-
정보
- capacity : 벡터 여유 공간 리턴
- size() : 원소 개수 리턴
- data() : 벡터가 사용하는 힙 메모리 주소 리턴
- empty() : 빈 벡터 유무 bool 리턴
-
반복자
- begin() : 벡터 첫 번째 원소
- end() : 벡터 마지막 원소 다음
- rbegin() : 역순, 벡터 마지막 원소
- rend() : 역순, 벡터 첫번째 원소 이전
-
원소 접근
- [n] : [인덱스] 로 해당 원소 접근
- at(n) : 해당 원소 접근.
[]와 기능은 동일하나 더 느림 - front() : 첫번째 원소 접근
- back() : 마지막 원소 접근
-
원소 추가
- assign(반복자,반복자) : 호출한 벡터의 해당 반복자 구간으로 할당
- assign(n, x) : x 를 n 번만큼 반복하여 집어 넣음
- push_back(원소) : 원소를 벡터 끝에 추가
- insert(반복자,원소) : 해당 반복자가 가리키는 곳에 원소 삽입
- insert(반복자, n, x) : 해당 반복자가 가리키는 곳에 x 원소를 n 개 삽입
-
원소 삭제
- pop_back() : 마지막 원소 제거
- erase(반복자) : 해당 반복자가 가리키는 곳 원소 삭제
- clear() : 벡터 원소 전부 삭제
- pop_back() : 마지막 원소 제거
-
원소 바꾸기
- swap(다른 벡터) : 다른 벡터와 원소 바꿈
-
🎉 리스트 (list)
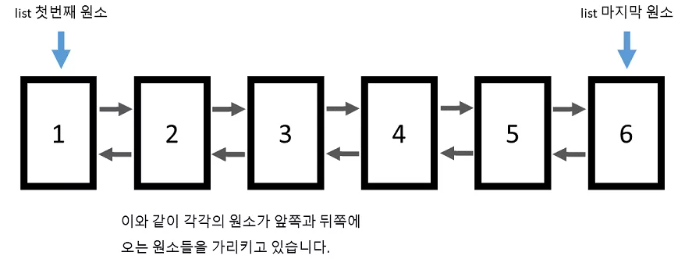
- 양방향 연결 구조를 가짐 (doubly linked list)
- 임의 위치 접근 불가능
- 임의 위치 원소 추가/제거 O(1)
- 중간에 원소 추가 일이 많고, 원소들을 순차적으로 접근 할 때 사용
🎉 덱 (deque - double ended queue)
- 벡터와 비슷하게 O(1) 으로 임의 위치 원소 접근 가능
- 맨 앞/뒤 원소 추가/제거도 O(1) 으로 가능
- 임의 위치 원소 제거/추가 작업은 O(n)
- 벡터와 다르게 원소들이 메모리에 연속적으로 존재하지 않음. 원소들이 어디에 저장되어 있는지 정보 보관을 위해 추가적인 메모리가 더 필요 (메모리 8배나 더 소모)
- 맨 처음과 끝 모두에 원소 추가 작업 많이 할 때 덱 사용!
🎉 시퀀스 컨테이너 사용 Case 정리
- 일반적인 상황의 경우
vector가 만능! - 끝이 아닌 중간에 원소 추가/제거가 많고, 원소 순차 접근만 한다면
list - 맨 처음, 끝에 원소 추가 작업이 많으면
deque
연관 컨테이너 (Associative Container)
- key-value 구조를 가짐.
- set, multiset : 특정 키에 연관 컨테이너가 존재 하는지 유무
- map, multimap : 특정 키에 대응되는 값이 무엇인지
🎉 셋 (Set)
- Red black tree 자료구조 활용
- set 안에는 중복 원소가 없음 (중복된
insert는 무시) - 원소 추가 시 내부 정렬된 상태를 유지
- key 가
bool타입의 value 값과 연결되어, key 존재 유무만 확인해 줌. - 원소 추가/제거/탐색 O(log N) (정렬되어 있으므로)
- find 로 원소 유무 확인 O(log N) (vector 의 find 는 O(log N))
- 자체 클래스를 set 의 원소로 활용 시, priority / job_desc 2개의 멤버 변수 가져야 하며
">,<" Operator overide 해야 함. - 반복자를 이용해서 순차적으로 맵에 저장되어 있는 원소 탐색 가능
- 함수
- begin() : 시작 iterator return
- end() : 끝 다음 iterator return
- insert(element) : insert
- erase(element) : erase
- clear() : element 전부 삭제
- find(element) : element 값에 해당되는 iterator return, 원소 없으면 end() 호출
- empty() : 비어 있으면 true, 아니면 false
- size() : 원소 개수 return
🎉 맵 (Map)
- Red black tree 자료구조 활용
- set 과 거의 유사하나, set 의 경우 key 만 보관하지만 map 은 key 에 대응하는 value 도 보관
- set 처럼 중복된 원소를 허용하지 않음
- map 의 원소는
std::pair타입 - 선언 시 템플릿 인자가 2개 (키의 타입, 값의 타입)
ex :std::map<std::string, double> pitcher_list - 반복자를 이용해서 순차적으로 맵에 저장되어 있는 원소 탐색 가능, for 문 가능
template <typename K, typename V>
void print_map(std::map<K, V>& m) {
// 맵의 모든 원소들을 출력하기
for (auto itr = m.begin(); itr != m.end(); ++itr) {
std::cout << itr->first << " " << itr->second << std::endl;
}template <typename K, typename V>
void print_map(std::map<K, V>& m) {
// kv 에는 맵의 key 와 value 가 std::pair 로 들어갑니다.
for (const auto& kv : m) {
std::cout << kv.first << " " << kv.second << std::endl;
}
}[key]연산자 활용하여 value 값 return 가능. 단, 없는 key 값을 참조 시 자동으로 디포트 생성자 호출해서 원소를 추가하여 '0' 을 return 함. 그러므로 되도록이면find함수로 원소가 키에 존재하는지 확인 후에, 값 참조가 좋음.- 함수
- begin() : 시작 iterator return
- end() : 끝 바로 다음 iterator return
- insert(std::pair) : (key,value) 형태로 element 추가
std::pair객체는 C++ 표준 객체template <class T1, class T2> struct std::pair { T1 first; T2 second; };first는 key,second는 value- 중복 원소 허용 X, 기존 Key 있으면 무시
- erase(key) : key 대응 element 삭제
- clear() : 모든 element 삭제
- find(key) :
- key 에 대응되는 iterator return
- key 값을 못 찾으면 end() 호출
- key 에 대응되는 iterator return
- count(key) : key 값에 해당되는 원소 개수 return
- empty() : map 이 비어 있으면 true, 아니면 false
- size() : 원소 개수 return
Map 에 원소 추가 방법 3가지
map 컨테이너는 원소를
pair타입 객체로 추가해야 한다.
std::pair템플릿 구체화 해주기
map<string,int> map;
map.insert(pair<string, int>("식빵",5));std::make_pair함수 사용하기 (std::pair 객체를 만들어 return 해 줌)
map<string, int> map;
map.insert(make_pair("식빵", 5));[]연산자 사용, 헤더에 연산자 오버로딩 되어 있음.map<string, int> map; map["식빵"] = 5;
-- 원소의 Value 를 수정, 바꾸러면 `[]` 를 사용하자insert사용 시, 기존 키 있을 경우 insert 가 무시되기 때문원소 탐색 : [] 주의사항, find
find(key) : 해당 키에 해당하는 원소 반복자를 return. 못 찾으면 end() return
[]사용 시 주의 사항[]로 맵에 없는 key 참조하면 자동으로 생성자 호출해서 원소 추가해 버림- 따라서 Key 를 참조 해야 할 때는 find() 를 사용하는게 더 안전함
- for-each 문 :
elem은 pair 객체,elem.first:key,elem.second:Value
map<string, int> map;
for (auto & elem : map)
{
cout << elem.first << " : " << elem.second << endl;
}🎉 멀티셋(multiset) 과 멀티맵 (multimap
- 한 개의 key 에 여러 value 가 대응 가능. 하지만
[]operator 사용 불가. - ...
🎉 unorderd_set, unordered_map
- Hash function 활용 (임의의 크기의 데이터를 고정된 크기의 데이터로 대응, 해시 함수는 해시 값 계산을 상수 시간에 처리 함)
- 원소들이 정렬되어 있지 않음.
unordered_set은 insert, erase, find 모두 O(1). 탐색은 최악의 경우 O(N).set,map은 평균/최악 O(log N) 이므로 일반적인 경우map,set을 사용하고 최적화가 매우 필요한 작업일 경우 해시 함수를 잘 설계해서unordred_set,unordered_map활용
🎉 연관 컨테이너 사용 Case 정리
- 데이터의 존재 유무만 궁금 할 경우 →
set - 중복 데이터 허락 할 경우 →
multiset(insert,erase,find모두 O(log N), 최악의 경우에도 O(log N)) - 데이터에 대응되는 데이터 저장하고 싶은 경우 →
map - 중복 키 허락 할 경우 →
multimap(insert,erase,find모두 O(log N), 최악의 경우에도 O(log N)) - 속도가 매우 중요해서 최적화 필요 한 경우 →
unordered_set,unordered_map(insert,erase,find모두 O(1), 최악의 경우 O(N) 따라서 해시 함수 및 상자 개수 최적화 필요)
문자열 (String)
- C++ 표준 문자열 라이브러리
- string 은 basic_string 클래스 템플릿의 인스턴스화 버전
- basic_string 은
CharT타입 객체들을 메모리에 연속적으로 저장하고, 문자열 연산들을 지원 (???) - C++14 에서 리터럴 연산자 (literal operator). 뒤에
s를 붙여주면auto가string으로 추론 (std::literals 네임스페이스 사용해야 함)
auto str = "hello"s;string_view는 문자열을 읽기만 하는 클래스npos: 상수로 string.h 헤더 파일내에 -1 로 정의 되어 있음. 해당 문자 or 문자열이 없다는 의미- 함수
substr(int pos, int cout): 문자열에서 [pos, pos+count] 범위의 부분 문자열을 returnfind: 인수로 들어간 문자열 혹은 문자가 포함되어 있는지를 찾음. 찾으면 그 문자열의 시작 위치를 return, 찾지 못하면npos를 returnstoi, stol, stoll: 문자열을 정수로 변환to_string: 정수나 실수를 문자열로 바꿈front, back: 맨 앞글자, 맨 뒷글자 출력+ 연산자: 문자열끼리+을 통해 이어 붙일 수 있음 (오버로딩 되어 있음)append(추가 할 문자열, 추가 문자열 시작 지점, 몇 글자 추가할건지)
알고리즘
- 컨테이너에 반복자들을 사용해서 이런 저런 작업을 쉽게 수행 할 수 있도록 도와줌
- 알고리즘에 정의되어 있는 함수들은 크게 두 개의 형태를 가지고 있음
전자는 알고리즘 수행 할 반복자 시작점, 끝점 바로 뒤를 받고
후자는 반복자는 동일하게 받되, '특정 조건' 을 추가 인자로 받음.
'특정 조건' 이런 서술자(Predicate) 라고 부르며,Pred에는 보통bool을 리턴하는 함수 객체 (Functor) 를 전달 함.
template <typename Iter>
void do_something(Iter begin, Iter end);template <typename Iter, typename Pred>
void do_something(Iter begin, Iter end, Pred pred)몇 가지 알고리즘 연산들
-
min_element(container.begin(),container.end()): 범위에서 가장 작은 원소의 반복자를 return -
max_element(container.begin(),container.end()): 범위에서 가장 큰 원소의 반복자를 return -
find(container.begin(),container.end(), item): item 검색해서 찾아서 그 반복자 return, 없으면 end() return -
정렬
sort(container.begin(),container.end()): 범위를 정렬, 세 번재 인수로 정렬 기준이 되는 사용자 정의 비교 함수 (lambda) 포인터 넘길 수도 있음sort(container.begin(),container.end(), compare): 범위를 정렬, 세 번재 인수로 정렬 기준이 되는 사용자 정의 비교 함수 (lambda) 포인터 넘길 수도 있음stable_sort: stable 정렬 (sort 는 unstable)partial_sort: 배열 일부분만 정렬
-
reverse: 인수로 넘긴 범위의 순서를 거꾸로 뒤집음. -
수학 관련 :
- max(a,b), min(a,b)
- max_element(시작 주소/반복자, 끝 주소/반복자), min_element(시작 주소/반복자, 끝 주소/반복자)
-
원소 수정하지 않는 작업 :
- all_of : 범위 안에 모든 원소들이 조건을 만족하는지 확인한다.
- any_of : 범위 안의 원소들 중 조건을 만족하는 원소가 있는지 확인한다.
- find : 범위 안에 원소들 중 값이 일치하는 원소를 찾는다.
- find_if : 범위 안에 원소들 중 조건과 일치하는 원소를 찾는다.
- count : 특정 값과 일치하는 원소의 개수를 센다.
- count_if : 특정 조건을 만족하는 원소의 개수를 센다.
- equal : 두 원소의 나열들이 일치하는지 확인한다.
- search : 어떤 원소들의 나열을 검색한다.
-
원소를 수정하는 작업 :
- copy : 원소들을 복사한다.
- copy_n : 원소들을 n 번 복사한다.
- copy_if : 특정 조건에 만족하는 원소들을 복사한다.
- copy_backward : 원소들을 뒤에서 부터 복사한다.
- move : 원소들을 이동시킨다.
- move_backward : 원소들을 뒤에서 부터 이동시킨다.
- swap : 두 원소를 서로 교환한다.
- transform : 특정 범위의 원소들을 변환한다.
- replace : 특정 범위의 원소들을 치환한다.
- replace_if : 특정 범위의 원소들을 조건이 맞을 시에 치환한다.
- replace_copy : 특정 범위의 원소들을 (다른데) 복사한 후 치환한다.
- replace_copy_if : 특정 범위의 원소들을 조건이 맞을 시에 복사한 후 치환한다.
- fill : 특정 범위를 어떤 값으로 채운다.
- fill_n : 특정 범위의 n 개의 원소를 값으로 채운다.
- remove : 특정 값들을 모두 지운다.
- remove_if : 특정 조건을 만족하는 원소들을 모두 지운다.
- remove_copy : 특정 값들을 복사한 후 지운다.
- remove_copy_if : 특정 조건에 만족하는 원소들을 복사한 후 지운다.
- unique : 연속적으로 다른 원소들이 나타나도록 같은 원소들을 제거한다.
- unique_copy : 연속적으로 다른 원소들이 나타나도록 같은 원소들을 제거하며, 제거된 원소들을 복사한다.
- reverse : 특정 범위의 원소들의 순서를 거꾸로 한다.
- reverse_copy : 특정 범위의 원소들의 순서를 거꾸로 해서 복사한다.
- rotate : 왼쪽으로 원소들을 회전시킨다 (첫번째 원소를 제외한 나머지 원소들을 왼쪽으로 쉬프트 한 후, 맨 왼쪽에 있었던 원소는 맨 뒤로 감)
- rotate_copy : 왼쪽으로 원소들을 회전시켜서 복사한다.
- random_shuffle : 무작위로 원소들을 섞는다. (C++17 에서 사용 금지됨; 아래 shuffle 사용 할 것!)
- shuffle : generator 을 이용해서 원소들을 섞는다.
람다 함수 (lambda function)
-
c++ 11 에서 도입, 쉽게 이름이 없는 함수 객체 만들 수 있음.
[capture list] (받는 인자) -> 리턴 타입 { 함수 본체 }
ex :
[](int i) -> bool { return i % 2 == 1; }
출처 :
https://modoocode.com/223
https://jiwanm.github.io/stl/vector/
Cpp Ref. : https://en.cppreference.com/w/cpp/header

복습용 저장소