
OpenMP 시작
- OpenMP 는 fork-join model 을 사용.
- OpenMP 컴파일 옵션
- gcc :
-fopenmp - icc :
-qopenmp - Cray :
-h omp
- gcc :
- parallel block 지정
#pragma omp parallel
{
...
}- thread 개수 지정 방법 3가지
- 환경 변수 설정 :
export OMP_NUM_THREADS = [int] - runtime 변수 설정 :
omp_set_num_threads([int]) - 전처리기 지시자 :
#pragma omp parallel num_threads(16) - 우선 순위 : 전처리기 지시자 > run time 변수 > 환경 변수
- 환경 변수 설정 :
- thread id 가져오기 :
#include<omp.h>; omp_get_thread_num(); _OPENMPmacro 를 사용하여, OpenMP 컴파일 option 유무에 따른 분기 가능.- 예시
- `#pragma omp parallel for private(a,b) num_threads(4)
데이터 유효 범위
- process 하부의 thread 는 stack, program counter 를 따로 가짐. 그 외에는 모두 공유.
private, firstprivate- thread 별로 변수를 따로 사용 하고 싶을 때는 private, firstprivate 활용. 변수를 복사하여 memory 공간을 새로 할당
- 배열과 같은 큰 data 를 복사하면, memory 부담이 매우 큼.
- 병렬 block 빠져 나가면 병렬 block 에서 쓰인 값은 사라짐.
- parallel block 안에서 변수 declaration 하면 다 private 임.
private: 변수를 새로 declaration (value assign X, gcc 의 default value 는 0)firstprivate: parallel block 밖의 값으로 변수 값으로 initialization. parallel block 나가면 값은 사라짐.
shared: thread 가 모두 같은 변수를 사용 할 때는 shared 활용. default 임. parallel block 밖에 변수 주소를 그대로 활용.- 예시 :
#pragma omp parallel shared(a) private(b,c) firstprivate(d)
동기화
- Critical
#pragma omp critical { ... }- block 으로 묶어서 thread 1개만 접근
- atomic
#pragma omp atomic- 단순 연산 1개(원자 연산) 만 thread 1개만 접근
Critical보다 ligth 하여, 성능이 더 좋음.
Critical, atomic적용하면 serial code 보다 더 느려 질 수도 있음.private을 활용해서 thread 가 각각 실행되도록 하고, 반드시 필요한 부분만critical, atomic적용해야 함.- barrier
#pragma omp barrier- 모든 thread 를 동기화
Reduction
- 연산을 thread 별로 분할해서 진행하고, 결과값을 취합하는 방법.
prgma omp for reduction ([operator]:[variable])pragma omp parallel for reduction ([operator]:[variable])로 하면 지시자 한 줄로 가능.atomic, critical을 쓰지 않고 변수와 연산을 정해서 값을 취합 하는 방법.variable: 어떤 변수에 취합 할 것인지operator: 어떤 종류 (연산)의 취합을 쓸 것인지.+,*,-,&,|,^,&&,||
- OpenMP 뿐만 아니라 MPI, CUDA 등 다른 병렬 프로그래밍에서도 활용.
- atomic 을 사용하는 것과 성능은 거의 유사.
- 코드 변경을 최소화 할 수 있음.
- 성능이 매우 뛰어나서, 최대한 사용하는 것이 좋음!
Nested Parallel
- Parallel block 안에서 한번 더 Parallel 을 써서 fork 를 n*n번 함.
omp_set_nested([1||0]): nested parallel 사용 여부 설정 (0 으로 하면 parallel 안에 parallel block 은 thread 1개만 실행 됨.)- 성능 이슈가 있어서, HPC 환경에서는 사용하지 않는 것을 권장 (?)
- 재귀 알고리즘의 경우 nested parallel 쓰면 코딩이 쉬워짐.
- OpenMP 5.2 부터는 deprecated
- fork level 마다 0,1,2,3.. 을 가짐. fork 시 thread id 는 0부터 새로 부여 됨.
omp_set_nested(1)- 더 정리...
작업분할, 동기화
- 작업분할 지시어
for, sections, single- 병렬 영역 내부에 삽입하에 작업할당에 이용
- 새로운 스레드 생성 없이 기존 스레드에 작업 분배
- 구문의 시작점 : 시작 할 때는 동기화가 없음. 즉, 먼저 접근하는 스레드가 우선적으로 작업을 할당 받음.
- 구문의 끝 : 동기화가 있음 (암시적 장벽). 즉, 작업이 먼저 끝난 thread 가 있어도 다른 모든 thread 가 작업이 끝날 때까지 대기함. (대기 없이 하려면 nowait clause 사용.)
- Sections
-#pragma omp sections로 block 설정#prgma omp section로 1개 thread 에 작업 할당- 여러 스레드에 작업 단위로 분배, 병렬 처리 가능
- 구문 끝에서는 동기화
- 사용 예시
#pragma omp parallel
{
// 작업 할당 받은 thread 만 아래 block 실행
#prgma omp sections
{
...
}
// 동기화
...
}-
Singles
- 가장 먼저 single 지시어에 도착한 thread 1개만 해당 작업 수행
- 구문 끝에서는 동기화
#pragma omp parallel { // 먼저 도착한 thread 가 아래 구문 실행 #pragma omp single { ... } // 동기화 }
-
master
single과 유사하나, 반드시 id 0번 thread 가 구문을 실행.- 구문 끝에 동기화가 없음!
#pragma omp parallel { // 0번 thread 가 아래 구문 실행 #pragma omp master { ... } // 동기화 없음. }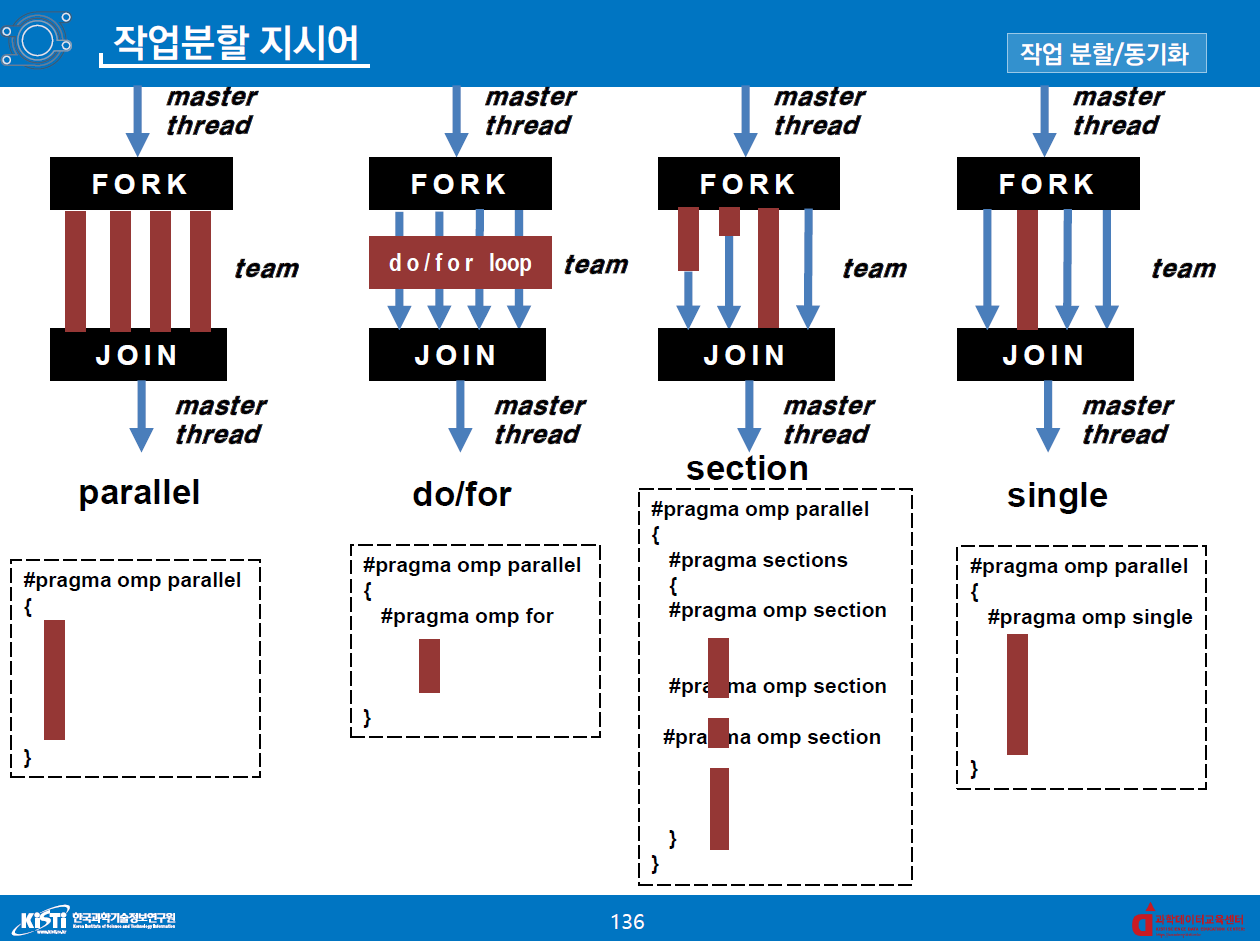
-
nowait
- 구문의 끝에 동기화를 하지 않게 해주는 보조지시어.
single,for에 사용. for구문에nowait사용하면 먼저 할당량이 끝난 thread 는 다음 code 를 쭉 진행.- 단, reduction 과 함께 쓰면 race condition 이 발생하므로, reduciton 과는 함께 쓰면 안됨.
#pragma omp single nowait,#pragma omp for nowait
- 구문의 끝에 동기화를 하지 않게 해주는 보조지시어.
-
ordered
- for 루프 구문에 사용하는 보조지시어. 명령문을 순서대로 출력함.
#pragma omp for ordered for (;;){ #pragma omp ordered printf(~); }
Schedule & Task
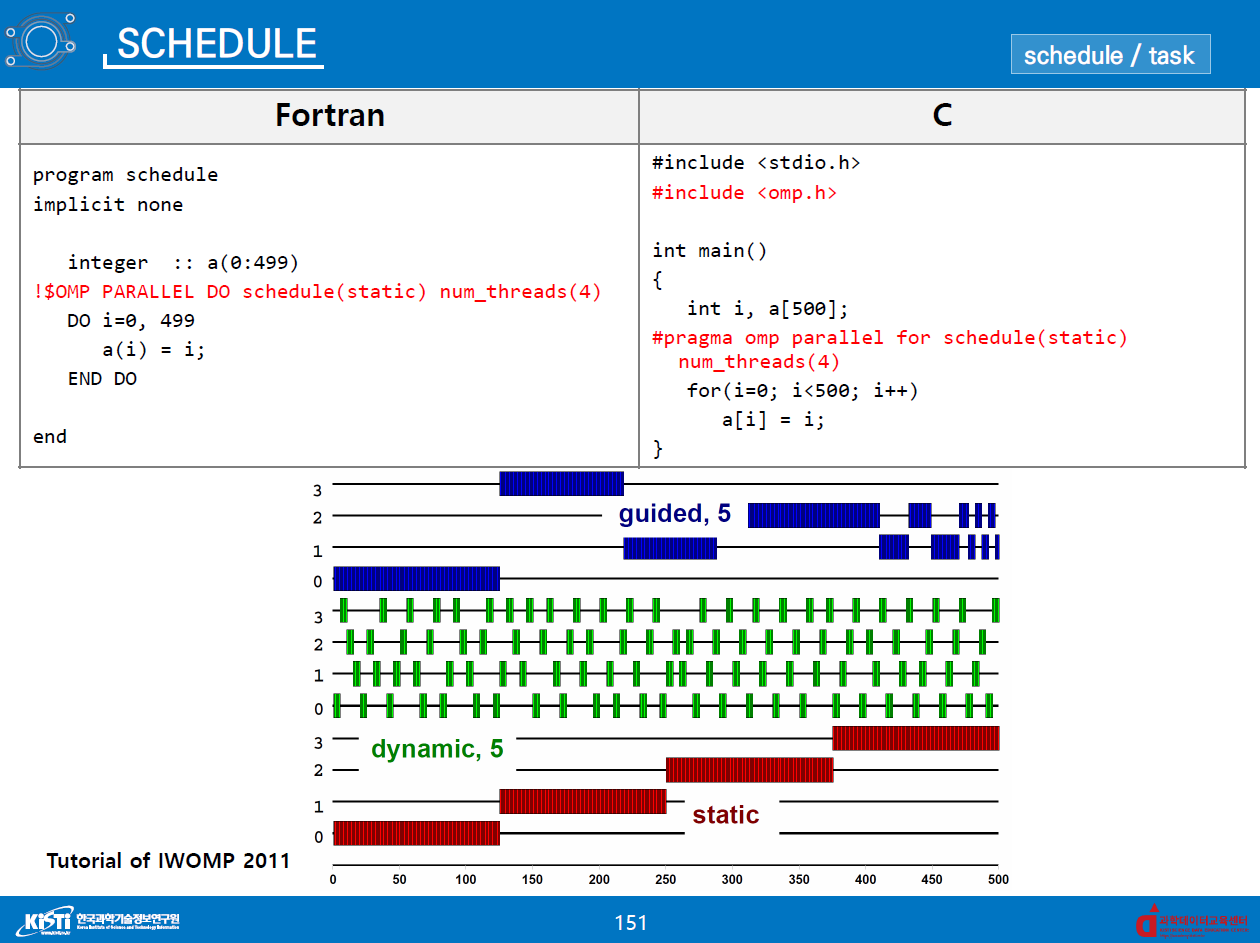
- schedule clause
#pragma omp parallel for schedule([static||dynamic||guided])- 루프의 분배 방식을 지정
- default : 실행 회수 균등 분배 (static)
- Static[, chunk_size]
- 각 스레드에 균일하게 할당
chunk_size가 주어지면, 총 반복 실행 횟수를chunk_size로 나누어 생성
- Dynamic[,chunk_size]
- 총 반복 횟수를
chunk_size로 나누어 chunk 생성 - 작업이 먼저 끝난 스레드는 다음 chunk 할당 (동적 할당)
- 총 반복 횟수를
- Guided
- Dynamic 의 일종
- chunk size 크기가 점점 작아짐
- Auto
- 컴파일러가 알아서 chunk size 지정.
- 추후 더 정리...
OpenMP performance issue
- Collapse 보조 지시어
- 중첩 loop 병렬 처리해서 병렬화 효율성 증가
- 중첩 loop 에서 fork-join 에 overhead 가 많이 발생 함. (nested for 쓰는 경우)
- nested for 를 안 쓰면 문법 오류 발생 함.
- n 개의 loop 를 단일 loop 처럼 컴파일러가 처리 함
- 유의사항으로 inner loop 가 outer loop 에 의존성이 없어야, 값의 불확실함이 없음. 의존성이 있는 경우, code 변경 필요.
- 예시
pragma omp for collapse(loop 개수)
for(i = 0; i < N; i++)
for(j = 0; j < N; j++)
a[i][j] *= 2;-
flush directive
#pragma omp flush([variable])- 컴파일 시 최적화 옵션
-O3를 사용하면 read/write 순서의 reordering 이 발생 함. 또한,-O3옵션 사용 시 메모리를 전부 캐시에 올려서 사용해서, 메모리 값의 변경을 알 수 없는 경우도 있음. 그 때flush를 써서 문제 해결 - flush directive 를 쓰면 메모리에서 값을 직접 읽어 옴.
-
False sharing
- 멀티코어 아키텍처에서, 코어와 Cache 사이에 값 변경 시 일관성 유지해야 함. Memory 에서 cache 로 데이터를 가져 올 때 64바이트의 크기를 한번에 올림. Data 가 인접해 있는 경우 (ex:array 에서 근접 element), core 가 각각 연산하는 data 를 캐시에 각각 올려두고 있고, 그 경우 연산이 발생하면 cache 값 일치를 계속 시켜서 overhead 가 발생함 -> False sharing 발생.
- False sharing 발생 시 성능 저하 발생 (함수 6~7배, App 2배)
- 해결 방법 :
- False sharing 이 발생 할 변수를 private 로 선언. (core 별 cache 에 같은 data 가 올라가지 않도록 함.)
- 인접한 메모리 주소를 사용하지 않고, 의도적으로 주소를 띄워서 사용. (array 라면 index 를 띄워서 사용. int array 라면 index 를 16 이상 띄움.)
- 성능 : reduction > atomic(false sharing 제거) > false sharing 제거 > serial code > false sharing
-
데이터 의존성
- data dependency 가 있을 때 for 구문을 그냥 쓰게 되면, 결과 값을 예측 할 수가 없음.
- shared 변수에서만 발생.
- Loop-carried 의존성
- flow 의존성 (RAW)
- anti 의존성 (WAR)
- output 의존성 (WAW)
- anti,output 의존성은 항상 제거 가능. flow 의존성은 케바케.
- flow 의존성 제거 : Loop skewing
- i, i+1 에 의존성이 있을 때 하드코딩과 index 조작을 통해서 i, i+1 의존성을 없앰.
- Loop-carried flow 의존성을 non-loop-carried 로 변환

출처 :
- KISTI e-learning OpenMP(초급) 강의
- 네이버 Mybox 에 강의자료 업로드

복습용 저장소