병렬 프로그래밍
1.포항공대 병렬 프로그래밍 강의 1
포스텍https://postech.edwith.org/강의 모음 (HPC Lab)https://hpclab.tistory.com/4내 udemy 강의 목록
2.CPU Parallel 동작 방법
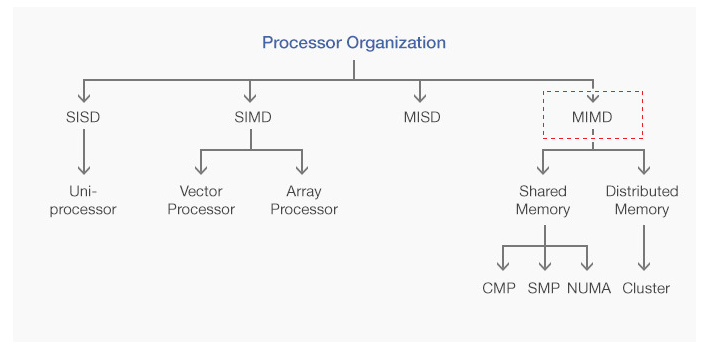
Single core, Hyper threading(superscalar), Multi Core, process-thread schedule (이거부터 보기! 그림으로 설명 잘 되어 있음)https://gregsnotes.medium.com/how-do-cpu
3.병렬 프로그래밍 프로세스
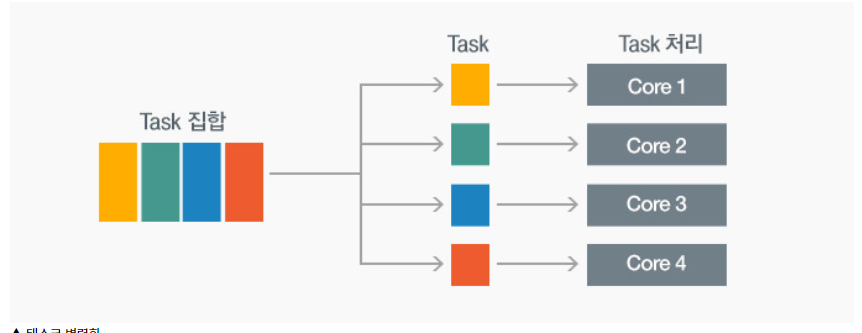
병렬 프로그래밍 : 순차적인 직렬 프로그래밍을 분할하고, 분할된 단위를 동시에 병렬로 수행함으로써 성능을 향상시키는 프로그래밍 기술병렬화 단계병렬화 대상 찾기의존성 분석병렬화 패턴 결정 - 테스크,데이터병렬 프로그래밍 구현 - 공유메모리, 메시지패싱, 가속기순차 코드에
4.Parallel Computing And Accelerators - OpenACC
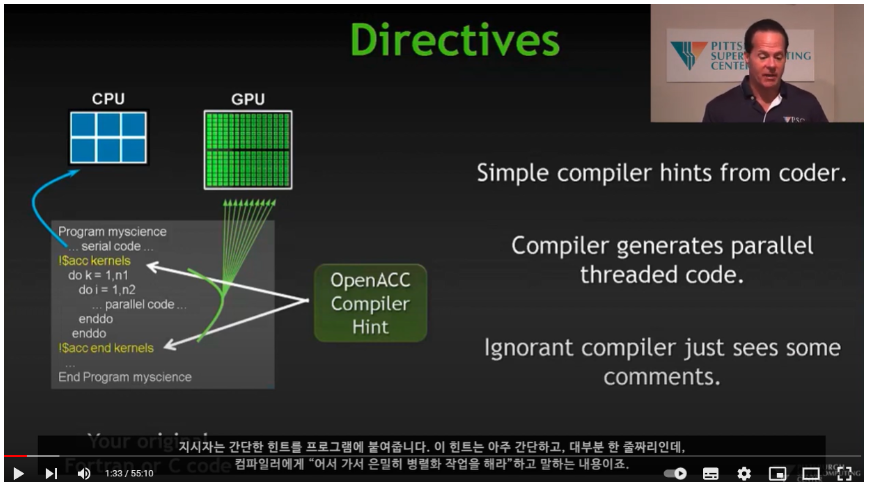
2004 년부터 serial computing 은 개선의 한계를 부딪힘클럭속도가 3~4 GHz 에서 한계 (발열 문제)\-> 병렬 컴퓨팅 필요GPU 는 CPU 와 별도로 메모리가 있다. 따라서 PCI 버스에서 병목이 매우 심하다.2016년 기준 Top 500 슈퍼컴퓨터
5.KISTI e러닝 OpenMP 초급 정리

thread 개수 지정 방법 3가지환경 변수 설정 : export OMP_NUM_THREADS = \[int]runtime 변수 설정 : omp_set_num_threads(\[int])전처리기 지시자 : \`- 우선 순위 : 전처리기 지시자 > run time 변수
6.MPI vs OpenMP, Hybrid MPI

모든 스레드가 동일한 메모리에 엑세스 함. (shared memory paradigm, 공유 변수 활용) 이 접근 방식은 루프 병렬화를 단순화하고 멀티 코어 프로세서 기능을 효과적으로 활용 가능.MPI 에 비해 synchronization, communication o
7.HPC 환경 기타 내용 정리

인텔 제온 E3, E5, Gold 6144Node 419 개, Core 수 17,912 개제온 파이 프로세서 (나이츠랜딩) 8305 대제온 프로세서 (스카이레이크-E3) 132 대 - 2.4 GHz x 2 Socket, 메모리 DDR4/ 2666 MHz 192GB인터커
8.GPU API 정리

oneAPI CPU,GPU,FGPA 등 다양한 컴퓨팅 아키텍처에서 하나의 API 만을 사용하는 통합 프로그래밍 모델 제공 프로젝트. 2020.9 에 발표. Intel 이 주도 다양한 언어와 라이브러리 (DPC++, MKL, DNN 등)를 포함하고 있음. DPC++ :
9.NUMA Archi. 에서 OpenMP 최적화
thread migration일반적으로 OS 는 core 간 workload 차이가 크게 나면, 작업(thread or process) 를 core 간 옮김. load balancing 을 개선 시키나, 추가적인 cost 가 발생 함.이 과정은 NUMA system
10.MPI
MPI (Message Passing Interface) 는 소스코드에서 하나의 변수로 선언된 것일지라도, 각각의 프로세스가 이름만 같은 별도의 변수를 가지며 값도 독립적임.서로 다른 프로세스간 값을 주고 받기 위해 별도 함수 호출 필요.여러 개의 Node 가 연결된
11.hybrid mpi, openmp, cuda or openacc 공부 할 자료..
https://aiichironakano.github.io/cs653/02-21MPI+OMP+CUDA-slide.pdfhttps://www.dcc.fc.up.pt/~ricroc/aulas/1516/cp/apontamentos/slides_mpi_ope