- 2004 년부터 serial computing 은 개선의 한계를 부딪힘. 클럭속도가 3~4 GHz 에서 한계 (발열 문제) -> 병렬 컴퓨팅 필요
- GPU 는 CPU 와 별도로 메모리가 있다. 따라서 PCI 버스에서 병목이 매우 심하다.
- 2016년 기준 Top 500 슈퍼컴퓨터는 OpenACC 를 활용
OpenACC
-
Open ACC 란 : directive based standard to allow developers to take advantage of accelerators such as GPUs from NVIDIA and AMD, Intel's Xeon Phi, FPGAs, and even DSP chips.
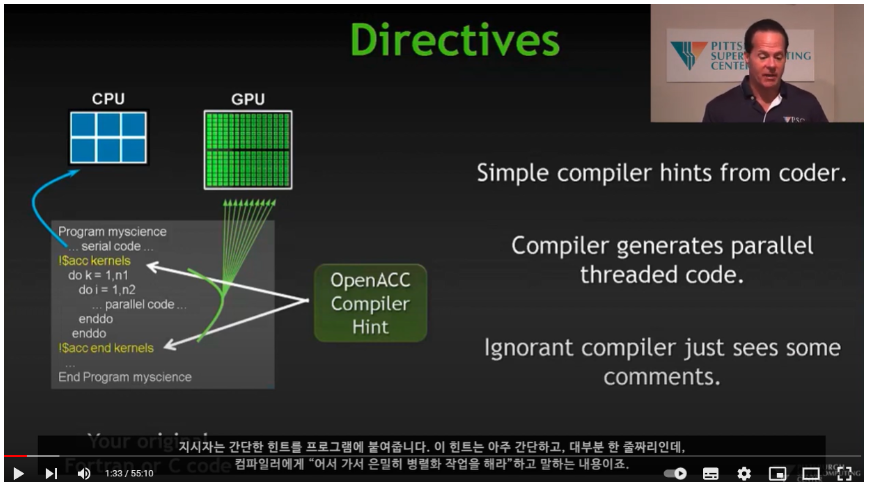
-
OpenMP 와 OPenACC 는 통합을 목표로 제작되었으며, syntax 가 매우 유사.
-CUDA 도 GPU 가속화 프로그래밍이 가능하지만, 매우 low level 임. 컴파일러가 해야되는일까지 대신하는 느낌. 또한 18-24개월마다 GPU 가 새로 등장하는데, GPU 마다 code 를 조금씩 바꿔줘야 함. 따라서 CUDA 로 직접 코딩하는 것 보다, CUDA 로 짜여진 라이브러리를 그냥 이용하는게 권장 됨. OpenACC 는 CUDA 로 짜여진 라이브러리를 활용 할 수 있음. (CUDA 의 오픈 소스 버전인 OpenCL 도 마찬가지..) -
MPI 를 사용해서 코드 병렬화를 하기 위해서는 전체 코드를 다 이해해야 하고, 상당한 양의 코드를 다시 써야 함
-
다양한 컴파일러에서 OpenACC 를 지원함. 그 중 PGI 컴파일러 (Nvidia 소유) 는 GPU 코드가 잘 작동하는 것에 초점이 맞추어져 있음. (무료인 PGI 커뮤니티 버전 존재) gcc 는 6.0 이상부터 OpenACC 지원
-
OpneMP 는 Shared memory 에서 사용을 목표로 하였기 때문에, 데이터 이동 (migration) 기능이 없음. OpenACC 는 PCI 버스를 통해 GPU 로 데이터 이동 가능.

-
Nvidia GPU 를 사용 할 꺼면 OpenACC, OpenACC 컴파일러 사용이 유리 (Nvidia 는 CUDA, OpenACC 를 지원)
-
Xeon Phi 를 사용 할 꺼면 OpenMP + 인텔 컴파일러가 유리 (인텔은 OpenMP 를 지원) (두 개 사이를 돌아가면서 하기 위한 편집 tool 도 존재 함)
-
OpenCL 은 법인 지원을 잃음

용어 정리
- FLOPS (FLoating point Operation Per Second)
1초동안 부동 소수점을 몇 번이나 연산할 수 있는지 나타내는 컴퓨터 성능을 나타내는 단위.
모바일 AP 는 기가 플롭스, PC 는 테라 플롭스, 슈퍼 컵퓨터는 페타 플롭스, 고성능 슈퍼 컴퓨터는 엑사플롭스 단위 성능 - 단위 :
- 1 GB : Gigabyte, 1e9 (유튜브 영상)
- 1 TB : Terabyte, 1e12 (최신 게임 20개)
- 1 PB : Petabyte, 1e15 (사진 55억 만장)
- 1 EB : Exabyte, 1e18 (구글 보유 데이터 총량이 10~15 엑사바이트)
- 1 ZB : Zettabyte, 1e21 (데이터 센터 약 천개, 인류가 보유 총 데이터가 100제타 바이트)
OpenACC 고급 프로그래밍 자세히 공부 할 자료
https://www.youtube.com/watch?v=I36kb1UBEBA
