📌 Face Mask Detection
- dataset
Face Mask Detection kaggle data
- 파이썬 압축 풀기
파이썬도 압푹 파일을 관리하는 툴이 있다.
# 압축풀기
import zipfile
content_zip = zipfile.ZipFile('../data/archive.zip')
content_zip.extractall('../data/')
content_zip.close()-
압축 풀기 전
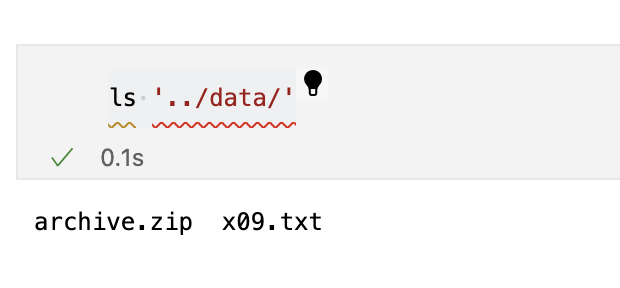
-
압축 푼 후
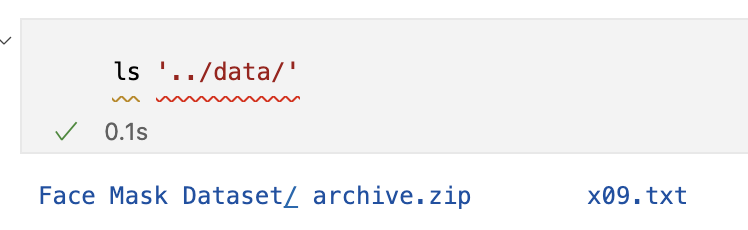
ls '../data/Face Mask Dataset/'
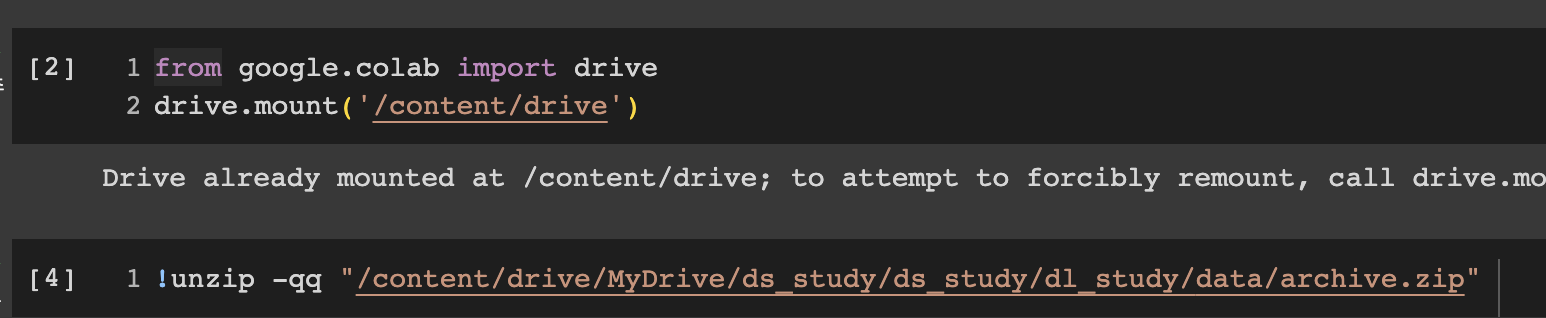
💡 colab에서 압축 풀기
- import module
import numpy as np
import pandas as pd
import os
import glob
import matplotlib.pyplot as plt
import seaborn as snsimport tensorflow as tf
from tensorflow.keras import Sequential, models
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPool2D
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix- 파일 정리
path = '../data/Face Mask Dataset/'
dataset = {
'image_path' : [],
'mask_status' : [],
'where' : []
}for where in os.listdir(path):
print('Where --> : ', where)
for status in os.listdir(path + where):
print('\tStatus --> : ', status)
for image in glob.glob(path + where + '/' + status + '/' + '*.png'):
dataset['image_path'].append(image)
dataset['mask_status'].append(status)
dataset['where'].append(where)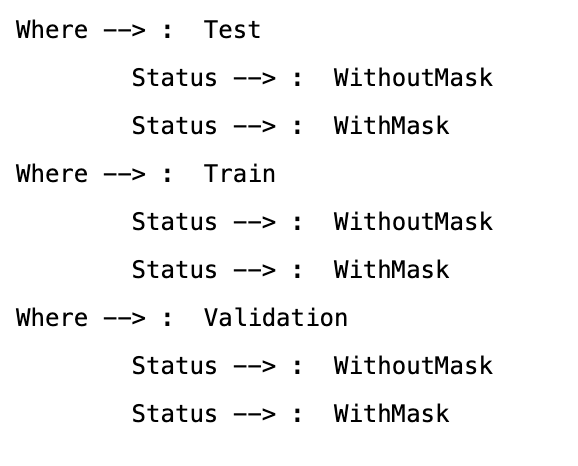
dataset = pd.DataFrame(dataset)
dataset.head()
- 마스크 사용 O, X 데이터 개수 확인
print('With Mask', dataset.value_counts('mask_status')[0])
print('Without Mask', dataset.value_counts('mask_status')[1])
sns.countplot(x=dataset['mask_status'])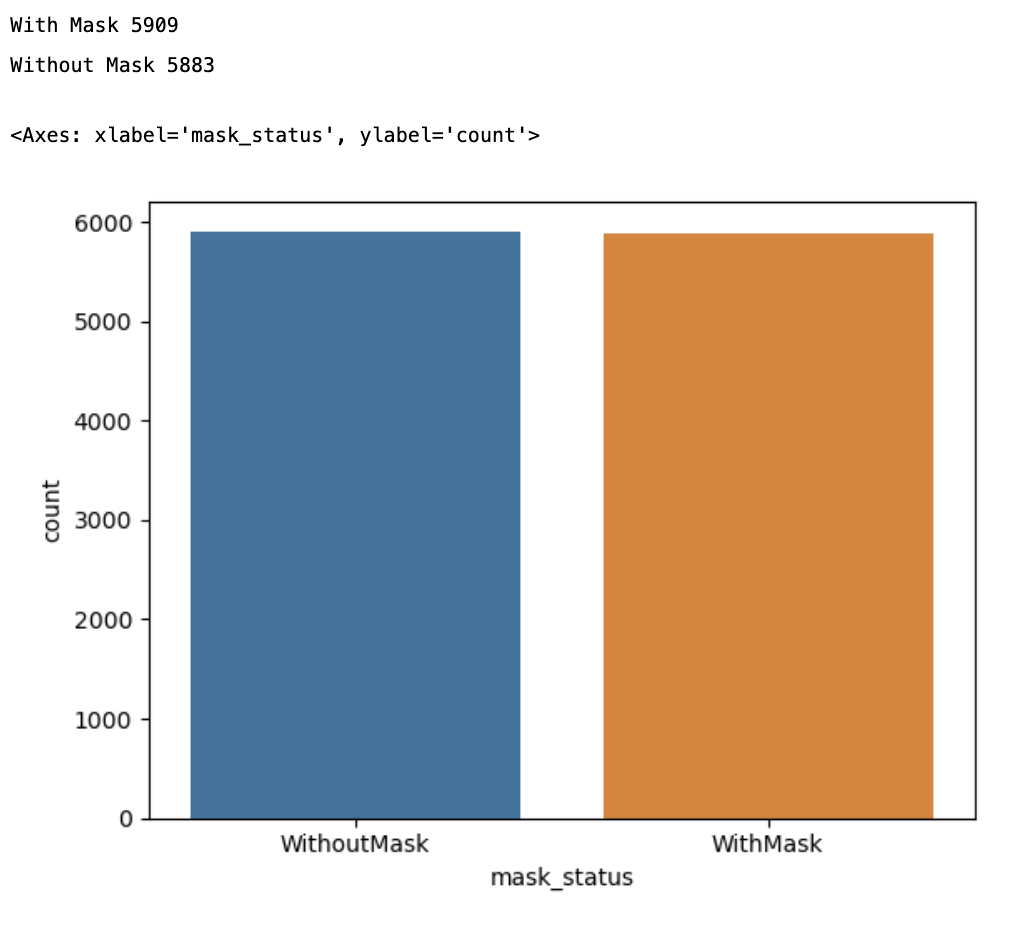
분포가 비슷한 모습을 볼 수 있다.
- 사진 확인
- 랜덤하게 어떤 그림이 있는지 확인
import cv2
plt.figure(figsize=(15, 10))
for i in range(9):
random = np.random.randint(1, len(dataset))
plt.subplot(3, 3, i+1)
plt.imshow(cv2.imread(dataset.loc[random, 'image_path']))
plt.title(dataset.loc[random, 'mask_status'], size=15)
plt.xticks([])
plt.yticks([])
plt.show()
gray처리 하지 않았기 때문에 푸르딩딩하게 보인다.
- Train, Test, Validation 확인
train_df = dataset[dataset['where'] == 'Train']
test_df = dataset[dataset['where'] == 'Test']
validation_df = dataset[dataset['where'] == 'Validation']
train_df.head()
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
sns.countplot(x=train_df['mask_status'])
plt.title('Training Dataset', size=10)
plt.subplot(1, 3, 2)
sns.countplot(x=test_df['mask_status'])
plt.title('Test Dataset', size=10)
plt.subplot(1, 3, 3)
sns.countplot(x=validation_df['mask_status'])
plt.title('Validation Dataset', size=10)
plt.show()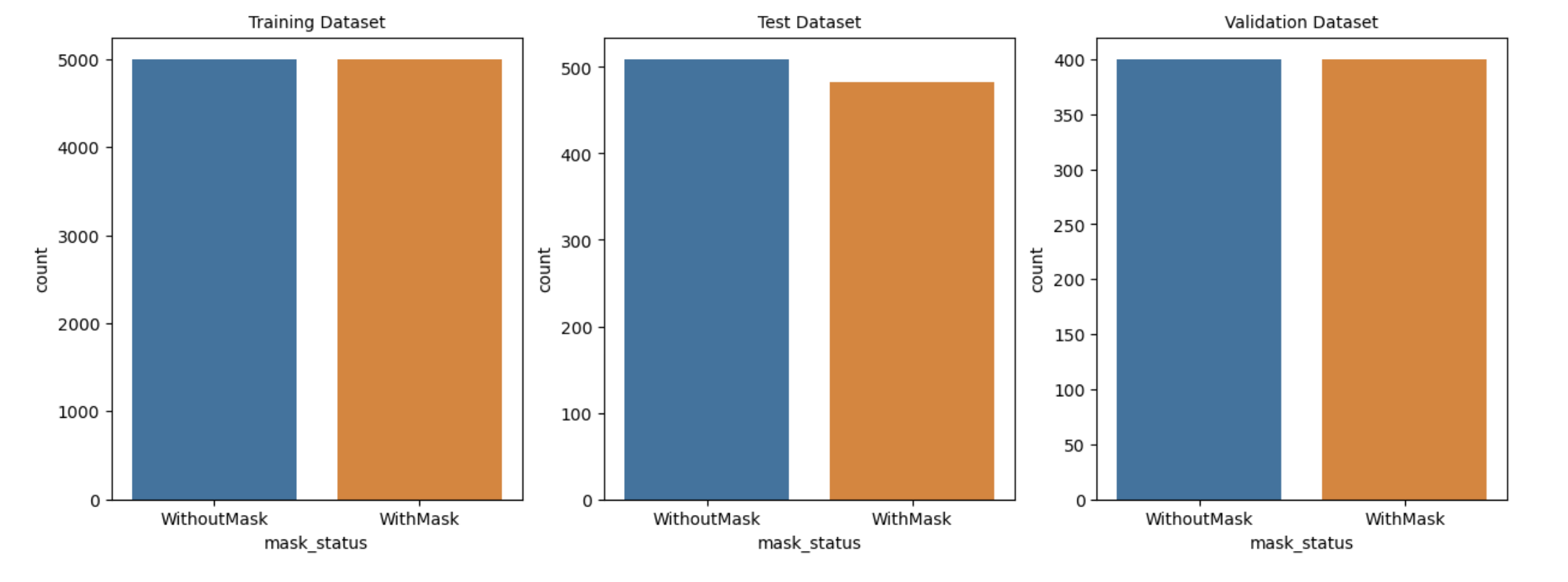
train_df = train_df.reset_index().drop('index', axis=1)
train_df.head()
- 데이터 전처리
data = []
image_size = 150
for i in range(len(train_df)):
img_array = cv2.imread(train_df['image_path'][i], cv2.IMREAD_GRAYSCALE)
# 이미지를 동일 크기로 resize
new_image_array = cv2.resize(img_array, (image_size, image_size))
# 마스크 사용여부 라벨 추가
if train_df['mask_status'][i] == 'WithMask':
data.append([new_image_array, 1])
else:
data.append([new_image_array, 0])data[0]
- 랜덤하게 섞어주는 코드
np.random.shuffle(data)data[0]
- 잘 섞였는지 확인
fig, ax = plt.subplots(2, 3, figsize=(10, 6))
for row in range(2):
for col in range(3):
image_index = row * 100 + col
ax[row, col].axis('off')
ax[row, col].imshow(data[image_index][0], cmap='gray')
if data[image_index][1] == 0:
ax[row, col].set_title('Without Mask')
else:
ax[row, col].set_title('With Mask')
X, y = [], []
for image in data:
X.append(image[0])
y.append(image[1])
X = np.array(X)
y = np.array(y)- train 데이터 다시 나누기(이유는 딱히 없다.)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=13)- 모델 생성
- LeNet
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(32, kernel_size=(5, 5), strides=(1, 1), padding='same', activation='relu', input_shape=(150, 150, 1)),
layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
layers.Conv2D(64, (2, 2), activation='relu', padding='same'),
layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(1000, activation='relu'),
layers.Dense(1, activation='sigmoid')
])출력이 0과 1 사이임을 기억해야함(sigmoid)
model.compile(optimizer='adam', loss=tf.keras.losses.BinaryCrossentropy(), metrics=['accuracy'])X_train = X_train.reshape(-1, 150, 150, 1)
X_val = X_val.reshape(-1, 150, 150, 1)- Fit
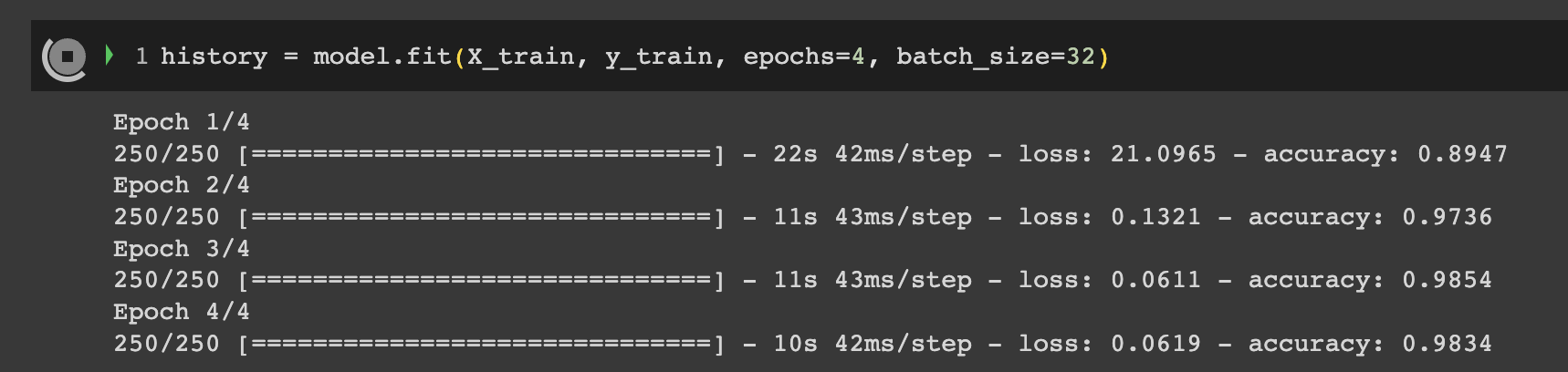
history = model.fit(X_train, y_train, epochs=4, batch_size=32)
💡 colab gpu를 사용하니 시간이 더 빨라졌다.
model.evaluate(X_val, y_val)
- 결과 확인
prediction = (model.predict(X_val) > 0.5).astype('int32')
print(classification_report(y_val, prediction))
print(confusion_matrix(y_val, prediction))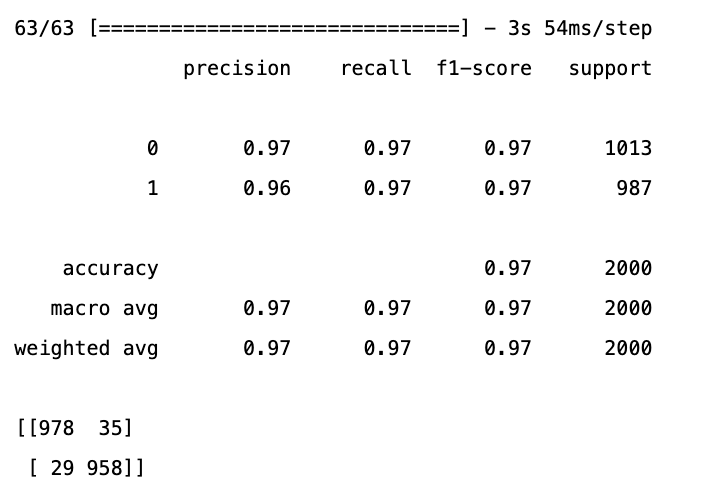
틀린것 확인
wrong_result = []
for n in range(len(y_val)):
if prediction[n] != y_val[n]:
wrong_result.append(n)
len(wrong_result)
64개가 틀렸다.
- 틀린 사진 랜덤으로 확인
import random
samples = random.choices(population=wrong_result, k=6)
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(3,2, idx+1)
plt.imshow(X_val[n].reshape(150, 150), interpolation='nearest')
plt.title(prediction[n])
plt.axis('off')
"이 글은 제로베이스 데이터 취업 스쿨 강의를 듣고 작성한 내용으로 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
