📌Boosting

- Adaboost
- STEP 1
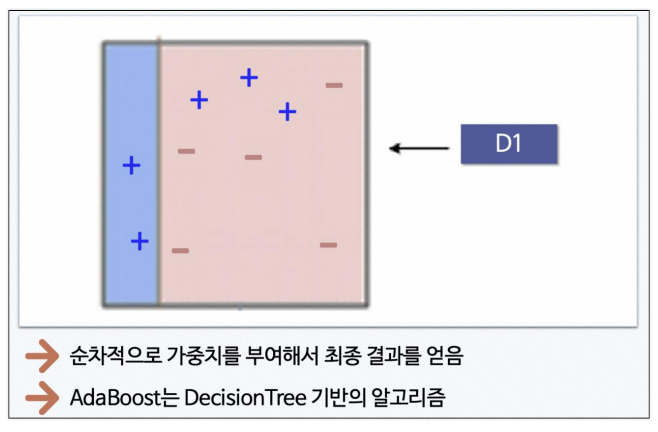
- STEP 2
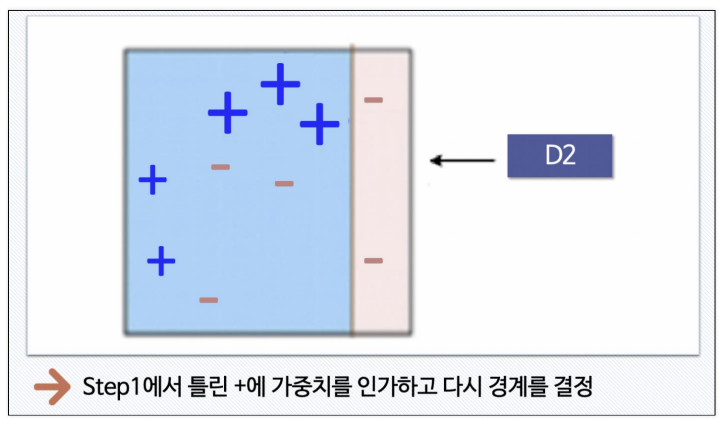
-
STEP 3
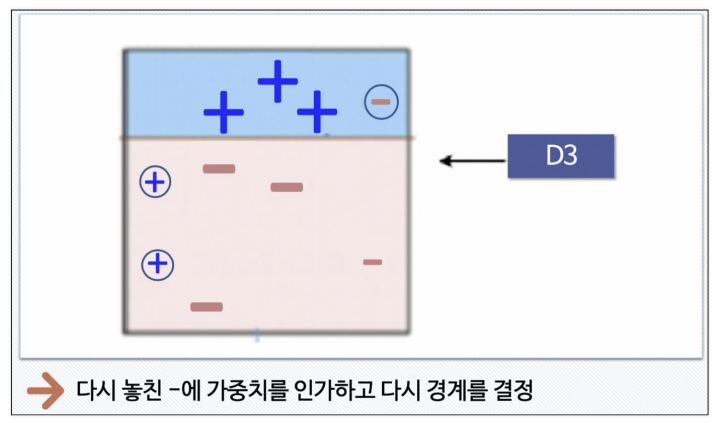
-
STEP 4
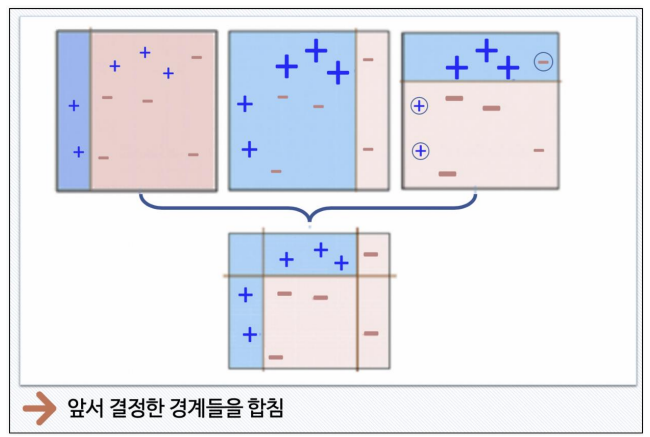
- Boosting 기법

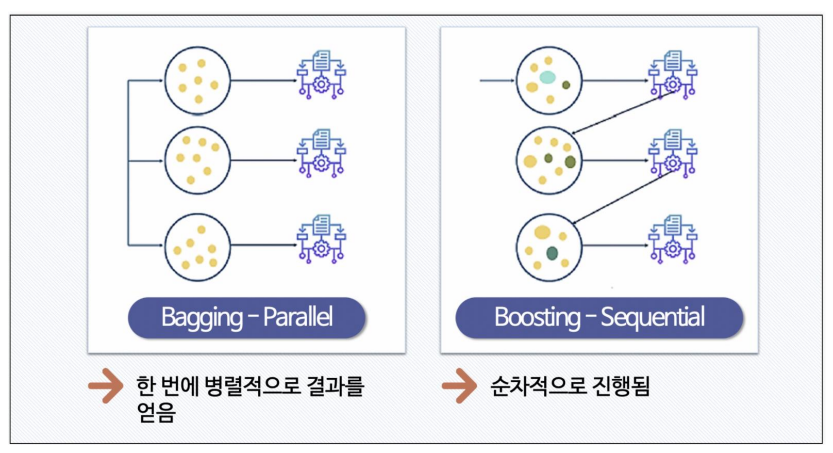
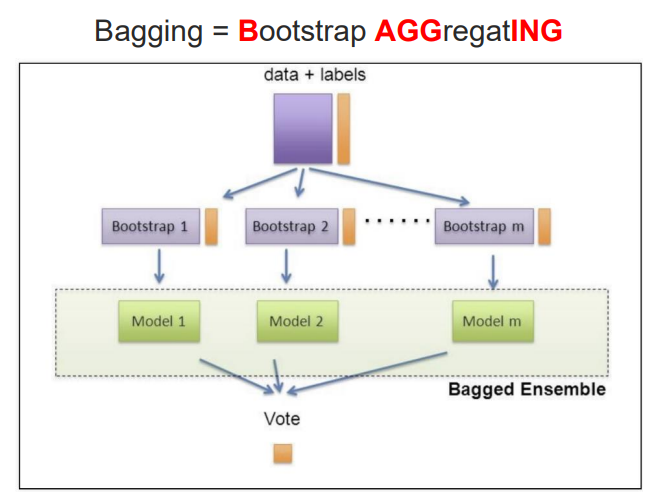
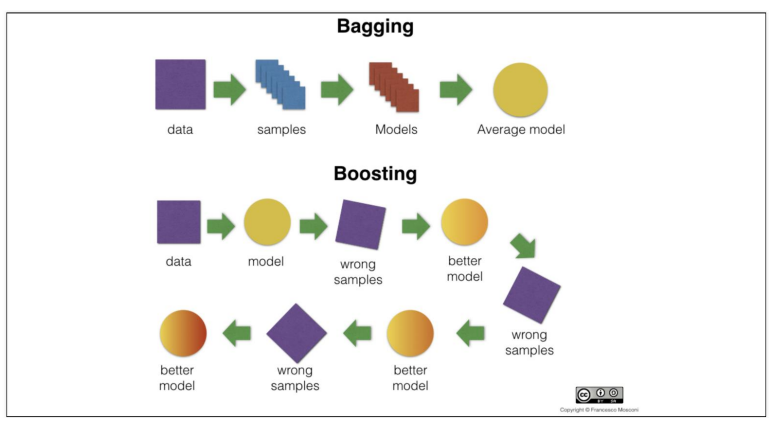
- 배깅과 부스팅의 차이
Bagging: 데이터 학습, 결과를 진행하는 타이밍이 동시에 이루어진다.
Boosting: 데이터를 가지고 학습하고 그 결과를 가지고 틀린 것 혹은 가중치 부여한 후 또 학습하는 순차적 진행
- Wine data
- 데이터 전처리
import pandas as pd
wine_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/wine.csv'
wine = pd.read_csv(wine_url, index_col=0)
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']- Standard Scaler 적용
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_sc = sc.fit_transform(X)- 데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_sc, y, test_size=0.2, random_state=13)
- 시각화
import matplotlib.pyplot as plt
wine.hist(bins=10, figsize=(15, 10))
plt.show()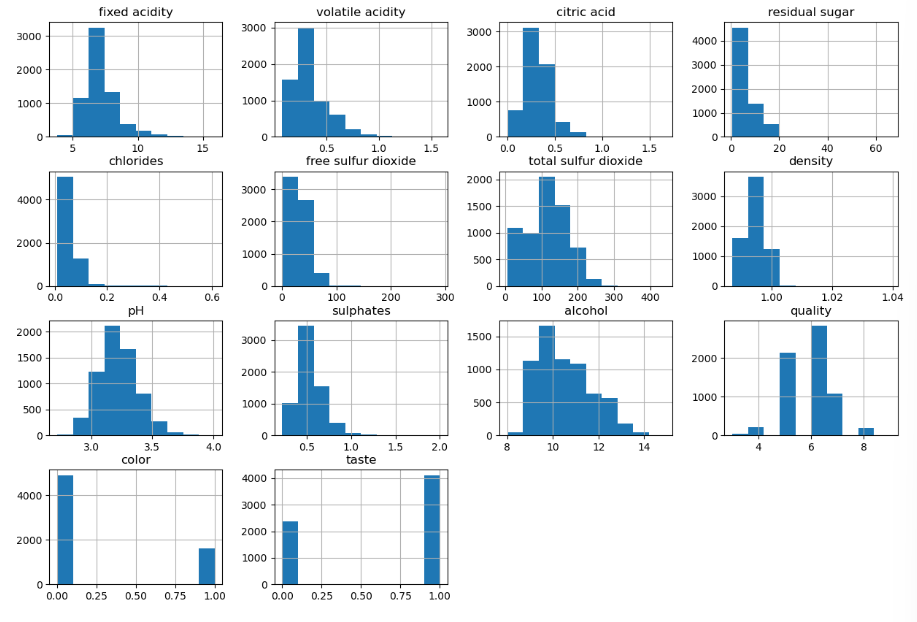
잘 분포되어 있는 컬럼이 좋을 때가 많다.
잘 분포되어 있는 컬럼이란
- quality 별 다른 특성이 어떤지 확인
colum_names = ['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar',
'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density',
'pH', 'sulphates', 'alcohol']
df_pivot_table = wine.pivot_table(colum_names, ['quality'], aggfunc='median')
print(df_pivot_table)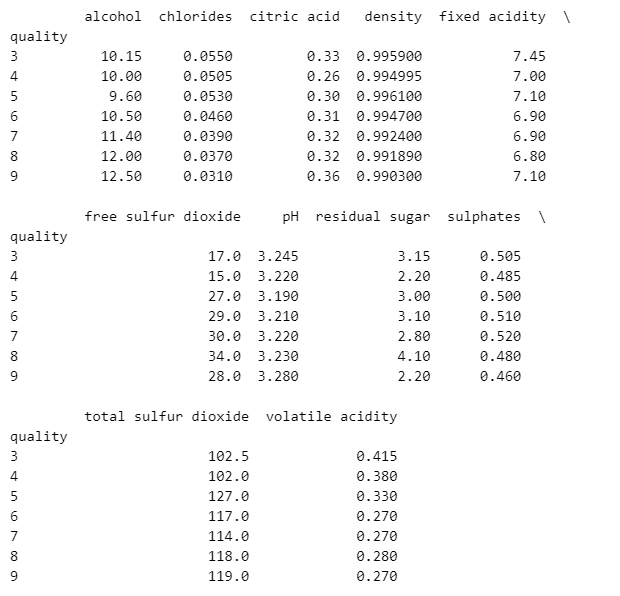
alcohol, dioxide 이 9등급으로 갈수록 증가하는 걸로 보인다.
- quality에 대한 나머지 특정들의 상관관계
corr_matrix = wine.corr()
print(corr_matrix['quality'].sort_values(ascending=False))
density가 제일 아래에 있다고 상관관계가 없다고 생각하면 안된다.
절대값을 생각해야한다.
so, alcohol, density가 가장 중요하구나 생각해야함.
- 다양한 모델 한 번에 테스트⭐⭐⭐
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
models = []
models.append(('RandomForestClassifier', RandomForestClassifier()))
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append(('LogisticRegression', LogisticRegression()))- 결과 저장
from sklearn.model_selection import KFold, cross_val_score
results = []
names = []
for name, model in models:
# n_splits: 5개로 나누기, shuffle: 데이터를 5개로 나누기 전 섞어라
kfold = KFold(n_splits=5, random_state=13, shuffle=True)
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())
results에는 5개 알고리즘의 성능이 저장되었다.
평균 값만 본다면 RandomForestClassifier가 가장 좋다.
- cross-validation 결과 확인
fig = plt.figure(figsize=(14, 8))
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()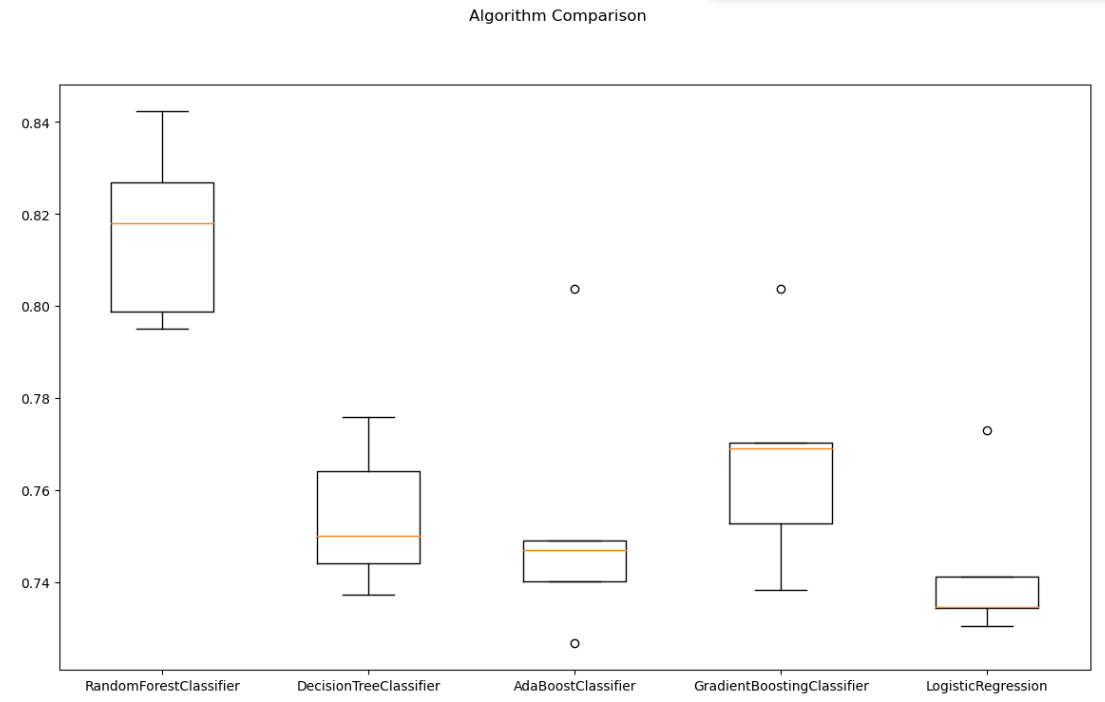
wine data에서는 RandomForest, GradientBoostingClassifier 순으로 좋은 성능으로 나왔다.
- 테스트 데이터에 대한 평가 결과
from sklearn.metrics import accuracy_score
for name, model in models:
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(name, accuracy_score(y_test, pred))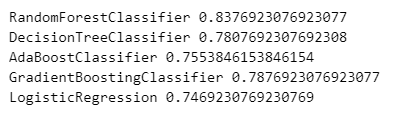
"이 글은 제로베이스 데이터 취업 스쿨 강의를 듣고 작성한 내용으로 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
