📌Wine data
- 분류 문제에서 많이 사용하는 Iris 꽃 데이터만큼 알려지진 않았지만, 와인데이터도 많이 사용한다.
- 인류 역사에서 최초의 술로 알려져 있다.
- 기원전 7000년 무렵 조지아-아르메이나-터키 동북부 (코카서스) 에서 흔적이 발견
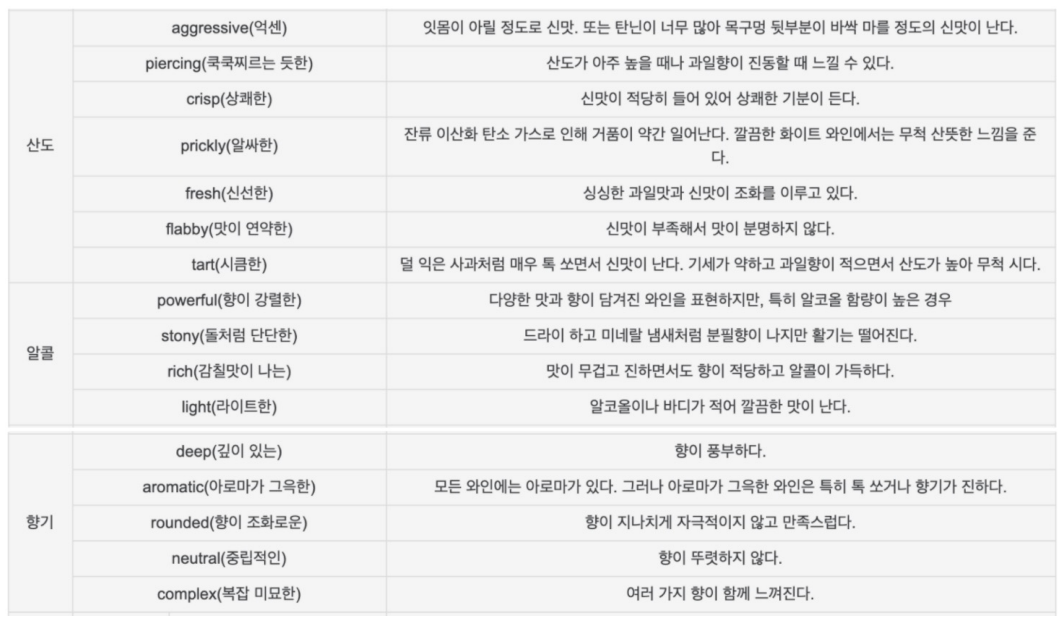
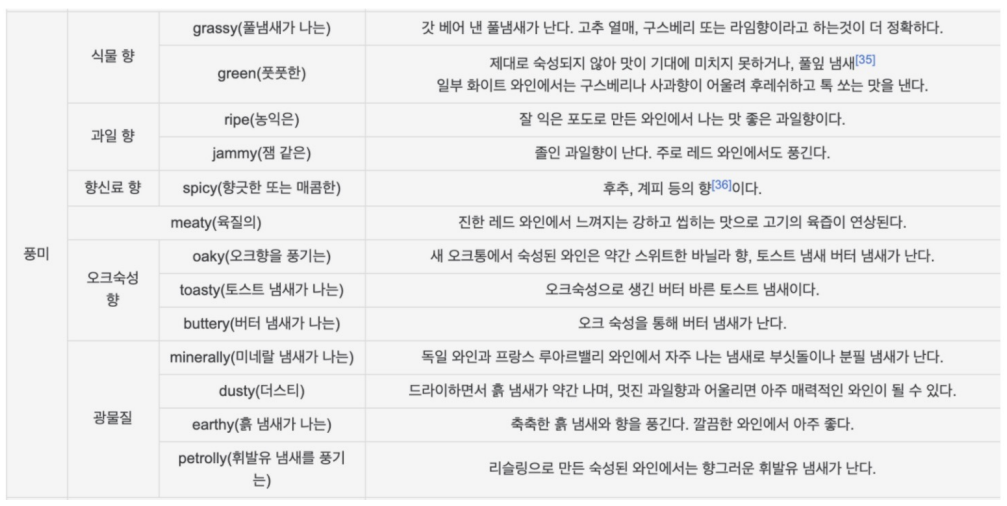
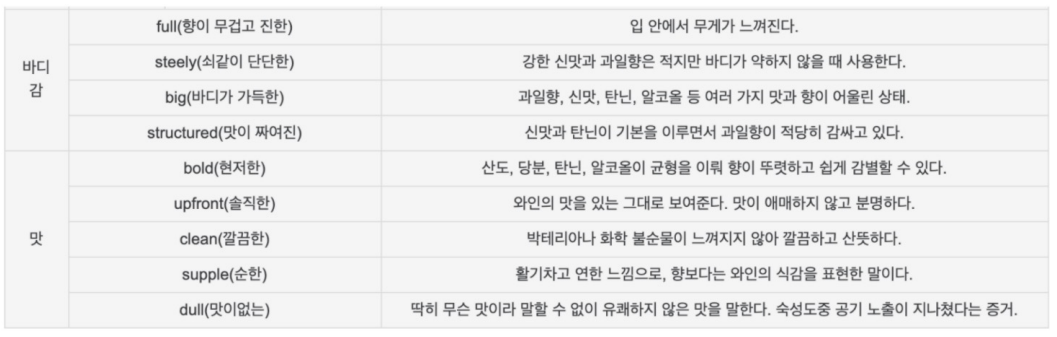
📍Wine 맛 분류

📍와인 데이터 받기
📍와인 데이터프레임 생성
import pandas as pdred_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')red_wine.head()
white_wine.head()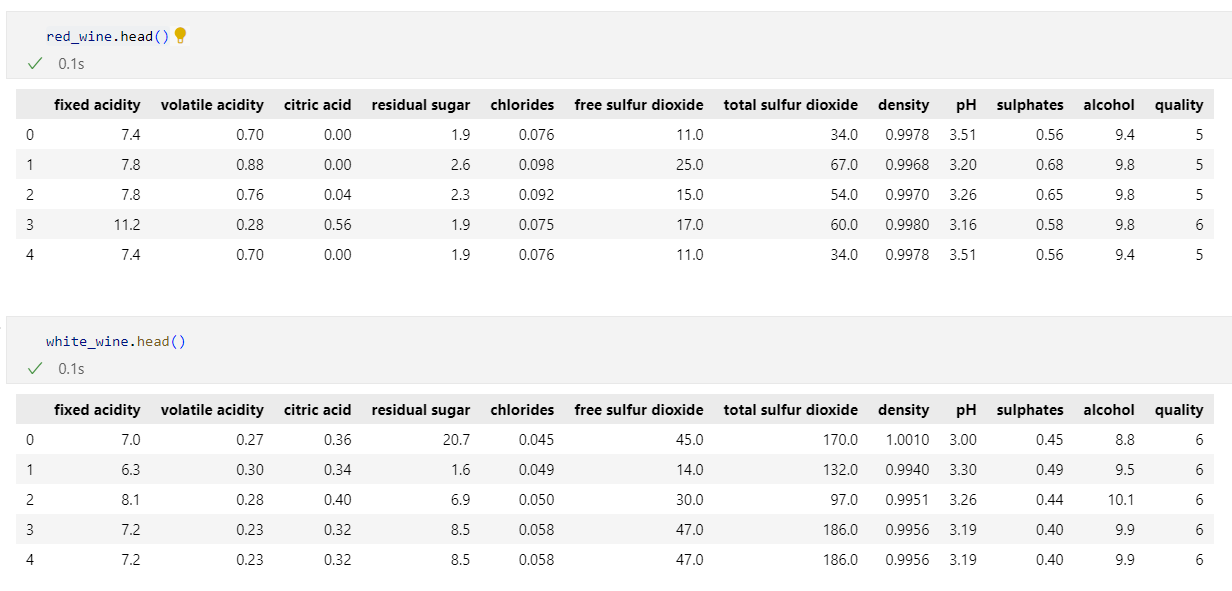
데이터 구조는 동일하다.
- 컬럼 종류
red_wine.columns

구조가 동일한 레드와인, 화이트 와인 데이터프레임을 합치기 위해 컬럼을 생성하여 red, white 표기 후 합치기
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine.info()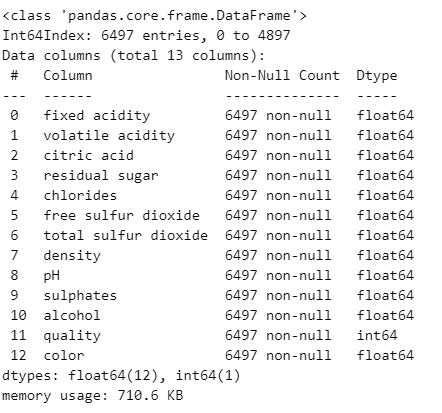
wine.head()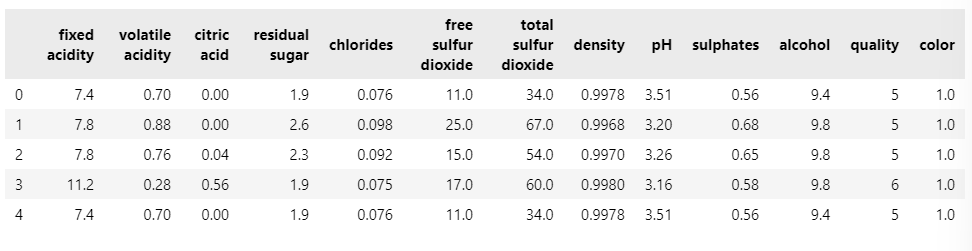
wine['quality'].unique()
📍시각화
- quality별 개수 histogram
import plotly.express as px
fig = px.histogram(wine, x='quality')
fig.show()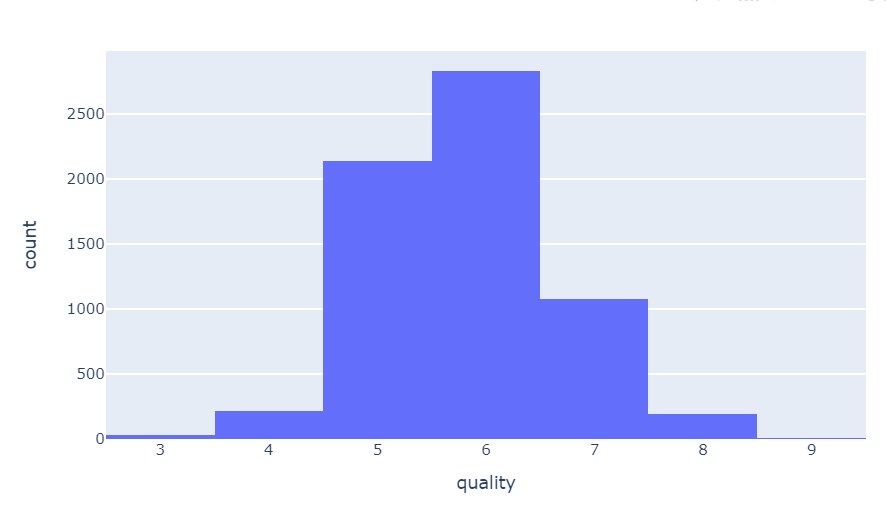
- quality별 개수 확인
wine['quality'].value_counts()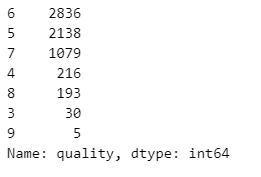
- wine 색상, quality별 개수 확인
fig = px.histogram(wine, x='quality', color='color')
fig.show()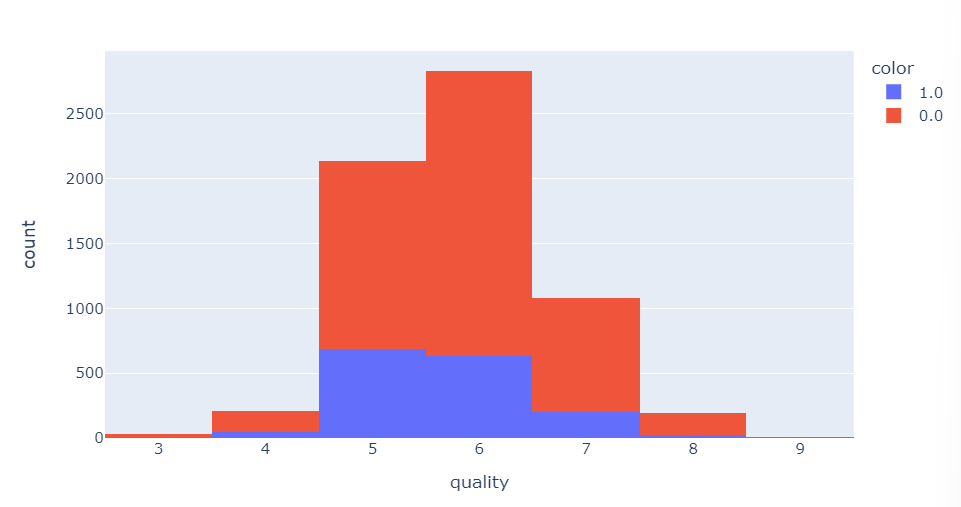
화이트 와인의 개수가 레드와인 대비 많다.
레드와인, 화이트와인 모두 5-6 등급의 수가 많다.
📌레드와인 / 화이트와인 분류기
- 레드와인, 화이트와인 분류를 위해 라벨을 분리
X = wine.drop(['color'], axis=1)
y = wine['color']
- 데이터를 훈련용과 테스트용 나누기
from sklearn.model_selection import train_test_split
import numpy as np
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)np.unique(y_train, return_counts=True)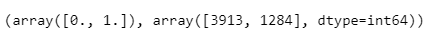
y_train에 0 - 3913개, 1 - 1284개로 구성되어 있다.
- 훈련용과 테스트용이 레드/화이트 와인에 따라 어느정도 구분되었는지 확인
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Histogram(x=X_train['quality'], name='Train'))
fig.add_trace(go.Histogram(x=X_test['quality'], name='Test'))
fig.update_layout(barmode='overlay') # 두 개가 겹칠 것
fig.update_traces(opacity=0.7) # 투명도 조절
fig.show()train와 test 데이터의 각 등급 별 개수가 얼마나 배분되었는지 확인하는 작업
나름 잘 들어간 것 같다.
- DecisionTreeClassifier(결정나무)
- FIT(학습)
X_train - feature, y_train - label
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
- 수치 확인
from sklearn.metrics import accuracy_score
y_pred_tr = wine_tree.predict(X_train) # train accuracy
y_pred_test = wine_tree.predict(X_test) # test accuracyX_train 로 학습했는데 왜 X_train로 accuracy를 확인하는가?
아직 수치를 확인하지 못했다. so train accuracy를 확인 해야한다.
- train 데이터 정답(y_train)과 훈련 모델이 예측한 결과값(y_pred_tr) 정확도 확인
accuracy_score(y_train, y_pred_tr)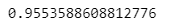
- 테스트 정답(y_test)과 훈련 모델이 예측한 결과값(y_pred_test) 정확도 확인
accuracy_score(y_test, y_pred_test)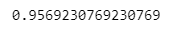
레드와인과 화이트와인을 분류하는 분류기(모델)의 성능을 봤더니 train, test 데이터의 accuracy가 유사함을 알 수 있었다.
📌데이터 전처리
MinMaxScaler와 StandardScaler
DecisionTree는 사실 scaler를 이용한 전처리에 크게 영향을 받지 않는다. 지니계수, 엔트로피를 계산할 때 feature 편향에 영향을 주지 않기 때문이다. 하지만 현재까지 학습한 DecisionTree를 사용하여 학습하기 위함
- 시각화
와인 데이터의 fixed acidity, chlorides, quality 항목의 Boxplot 그리기
fig = go.Figure()
fig.add_trace(go.Box(y=X['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=X['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=X['quality'], name='quality'))
fig.show()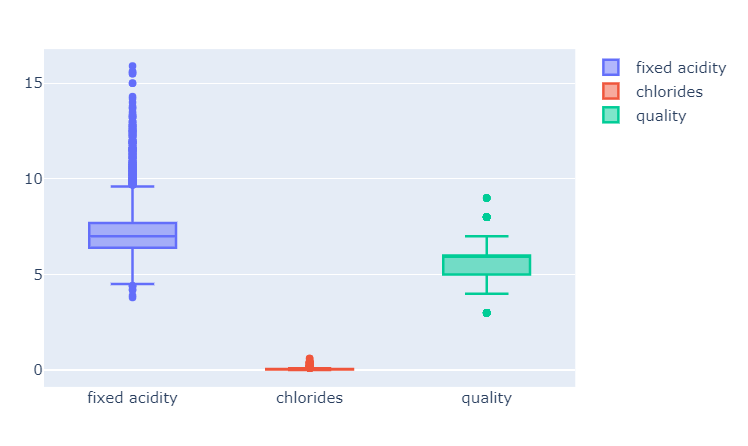
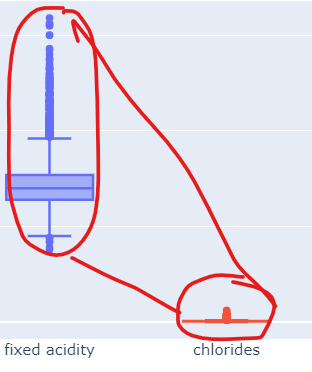
일반적으로 머신러닝에서 컬럼들 간의 범위의 격차가 심한 경우에는 제대로 학습이 안될 수도 있다.
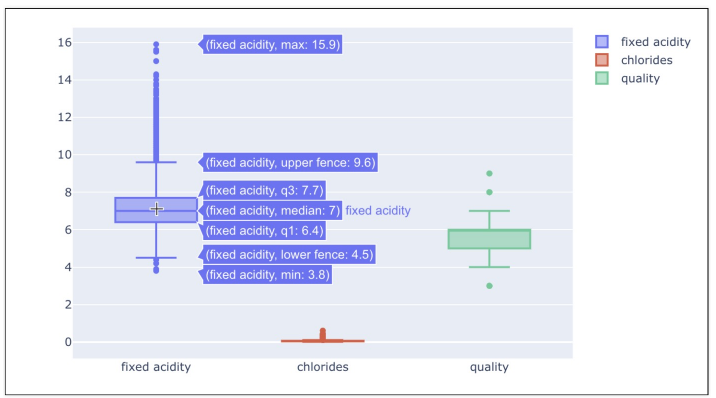
- 컬럼들의 최대/최소 범위가 각각 다르고, 평균과 분산이 각각 다르다.
- 특성(feature)의 편향 문제는 최적의 모델을 찾는데 방해가 될 수도 있다.
이럴 때 MinMaxScaler와 StandardScaler를 사용한다.
- MinMaxScaler, StandardScaler
- 결정나무에서는 이런 전처리는 의미를 가지지 않는다.
- 주로 Cost Function을 최적화할 때 유효할 때가 있다.
- MinMaxScaler와 StandardScaler 중 어떤 것이 좋을지는 해봐야 안다.
from sklearn.preprocessing import MinMaxScaler, StandardScaler
MMS = MinMaxScaler()
SS = StandardScaler()
X_ss = SS.fit_transform(X)
X_mms = MMS.fit_transform(X)
X_ss_pd = pd.DataFrame(X_ss, columns=X.columns)
X_mms_pd = pd.DataFrame(X_mms, columns=X.columns)** 새로운 데이터 프레임을 생성하는 이유 > 그래프를 그리기 위함
- MinMaxScaler
최대 최소값을 1과 0으로 강제로 맞추는 것
fig = go.Figure()
fig.add_trace(go.Box(y=X_mms_pd['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=X_mms_pd['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=X_mms_pd['quality'], name='quality'))
fig.show()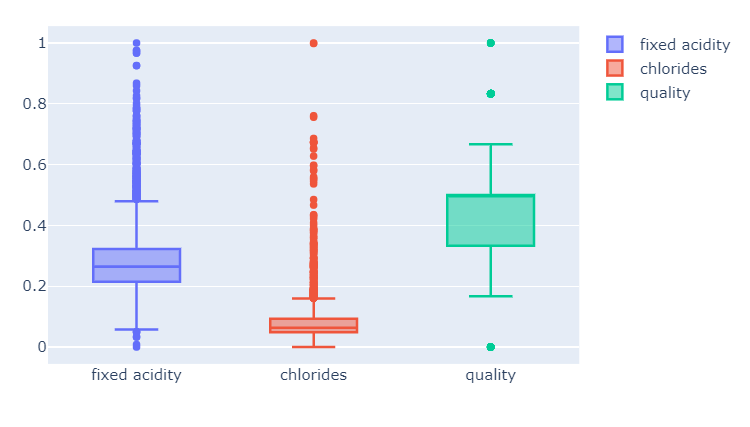
- StandardScaler
평균을 0으로 표준편차를 1로 맞추는 것
fig = go.Figure()
fig.add_trace(go.Box(y=X_ss_pd['fixed acidity'], name='fixed acidity'))
fig.add_trace(go.Box(y=X_ss_pd['chlorides'], name='chlorides'))
fig.add_trace(go.Box(y=X_ss_pd['quality'], name='quality'))
fig.show()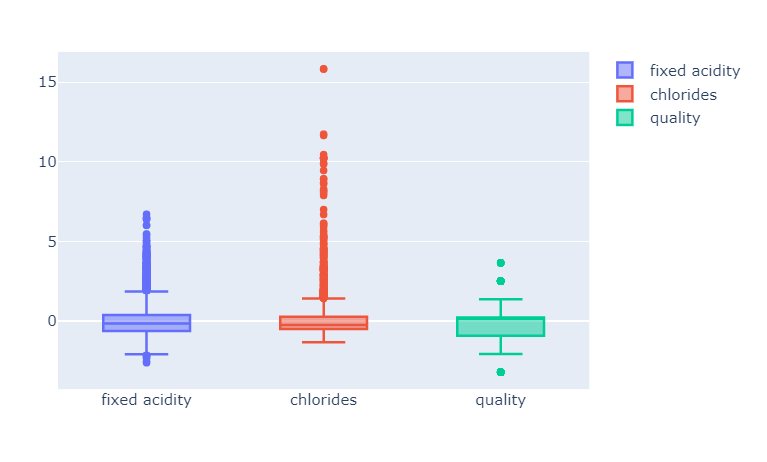
- FIT
다시 이야기하지만 결정나무에서는 이런 전처리는 거의 효과가 없다.
- MinMaxScaler를 적용해서 다시 학습
X_train, X_test, y_train, y_test = train_test_split(X_mms_pd, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print('Train Acc :', accuracy_score(y_train, y_pred_tr))
print('Test Acc :', accuracy_score(y_test, y_pred_test))
- MinMaxScaler를 적용해서 다시 학습
X_train, X_test, y_train, y_test = train_test_split(X_ss_pd, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print('Train Acc :', accuracy_score(y_train, y_pred_tr))
print('Test Acc :', accuracy_score(y_test, y_pred_test))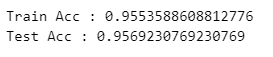
- 중요 feature
레드와인과 화이트와인을 구분하는 중요 특성
레드와인과 화이트와인을 구분하는 중요 특성
max_depth에 따라 다르게 나온다.
📌와인 맛의 이진 분류
와인 맛에 대한 분류 - 이진 분류
1. quality 컬럼 이진화
와인 맛을 와인의 등급이 5보다 크면 1, 같거나 작으면 0으로 하자
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
wine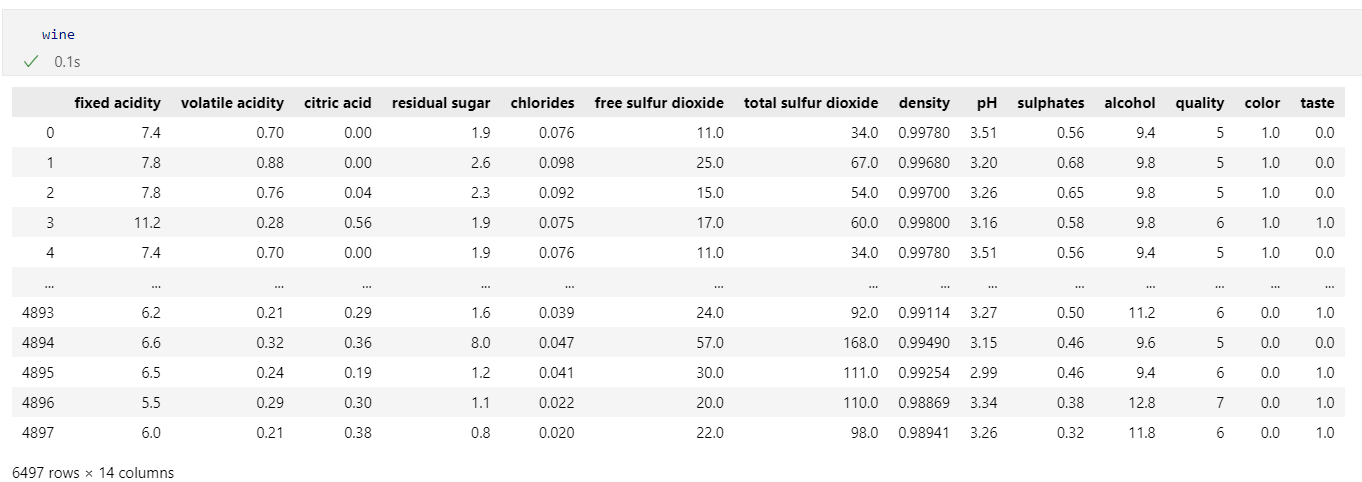
2. 맛 분류 위해 라벨 분리
X = wine.drop(['taste'], axis=1)
y = wine['taste']
3. 학습
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
4. accuracy 확인
from sklearn.metrics import accuracy_score
y_pred_tr = wine_tree.predict(X_train) # train accuracy
y_pred_test = wine_tree.predict(X_test) # test accuracy
print('Train Acc :', accuracy_score(y_train, y_pred_tr))
print('Test Acc :', accuracy_score(y_test, y_pred_test))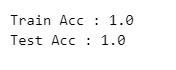
💡머신러닝을 하다가 100%가 나오면 무조건 의심해야한다.
도대체 왜 100%가 나왔지!? 가능한가?
5. 시각화
import matplotlib.pyplot as plt
import sklearn.tree as tree
plt.figure(figsize=(12, 8))
tree.plot_tree(wine_tree, feature_names=X.columns)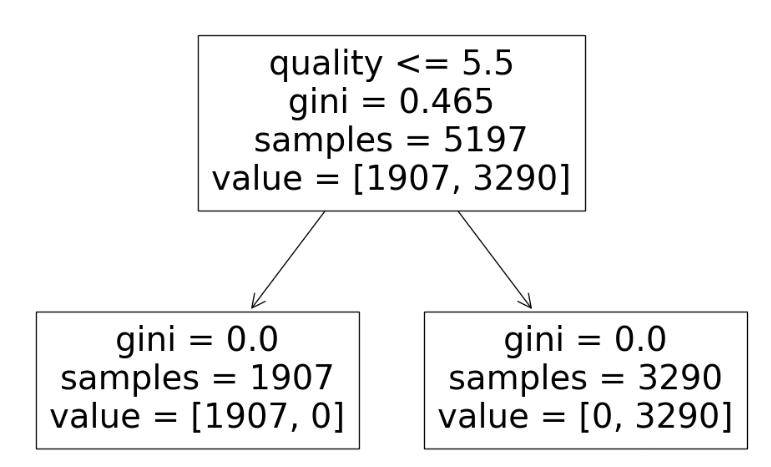

taste 컬럼을 quality 5 기준으로 정해서 2번에서 맛 분류 위해 라벨 분리했다.(taste 컬럼 제거) 하지만 그런 과정에서 quality 컬럼을 지우지 않았다.
그래서 quality 컬럼을 가지고 학습을 한 것이다.
-> taste 컬럼을 quality 컬럼 가지고 만들었으니 quality 컬럼도 삭제했어야했다.
위의 2번 작업부터 다시 해야한다.
2. 맛 분류 위해 라벨 분리
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']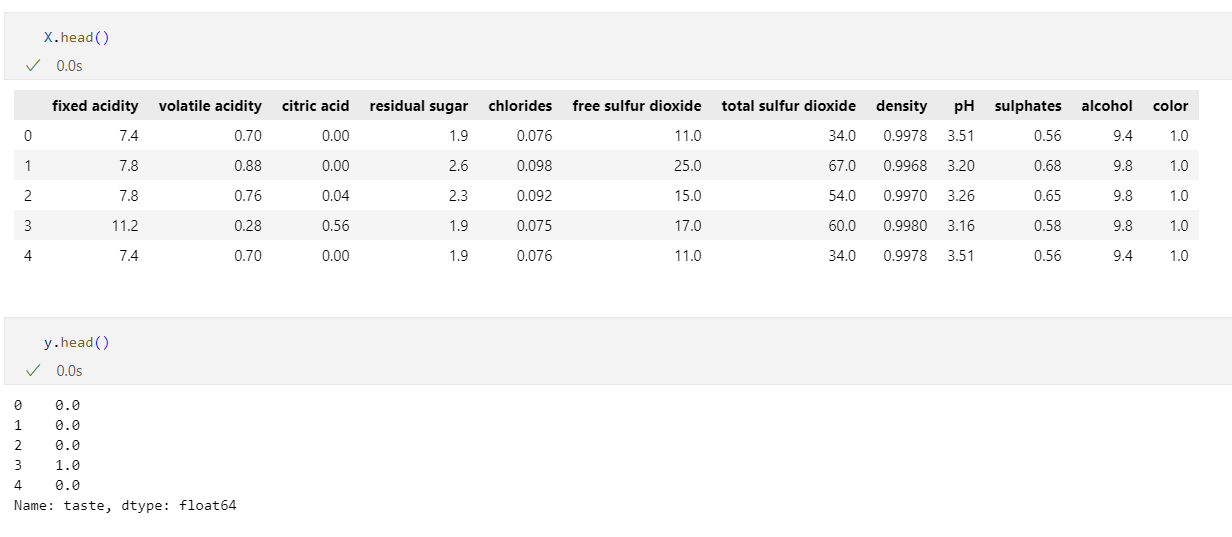
3. 학습
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
4. accuracy 확인
from sklearn.metrics import accuracy_score
y_pred_tr = wine_tree.predict(X_train) # train accuracy
y_pred_test = wine_tree.predict(X_test) # test accuracy
print('Train Acc :', accuracy_score(y_train, y_pred_tr))
print('Test Acc :', accuracy_score(y_test, y_pred_test))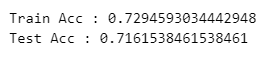
화학 성분을 가지고 맛이 있다 없다 구분하는 것은 이렇구나 알 수 있다.
5. 시각화
plt.figure(figsize=(12, 8))
tree.plot_tree(wine_tree, feature_names=X.columns,
rounded=True,
filled=True
)
plt.show()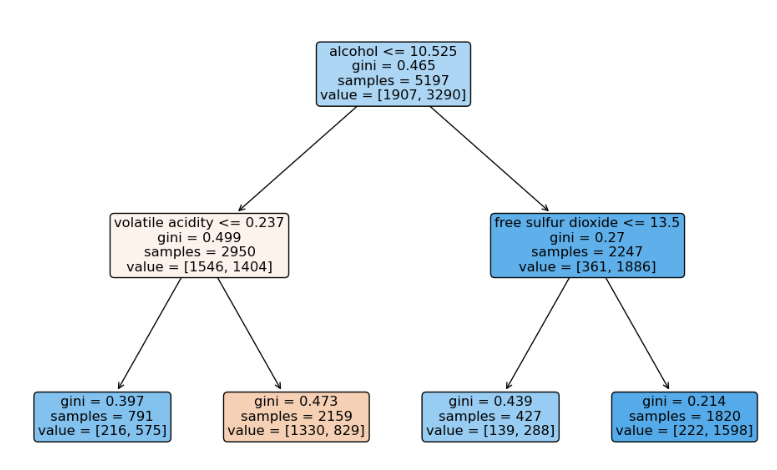
맛있다의 기준을 alcohol을 첫번째 기준으로 잡았다.
alcohol의 높낮이의 기준으로 맛을 결정할 수 있는가? 생각을 해야한다.
"이 글은 제로베이스 데이터 취업 스쿨 강의를 듣고 작성한 내용으로 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
