📌label encoder
대상이 되는 문자로 된 데이터를 숫자로 변환하는 작업
import pandas as pd
df = pd.DataFrame({'A': ['a', 'b', 'c', 'a', 'b'],
'B': [1, 2, 3, 1, 0]
})
df 
여기서 A를 알고리즘 통과하기 위해 문자가 아닌 숫자가 되어야한다.
따라서 'a' > 1, 'b' > 2, 'c' > 로 바꾸고 싶을 때 이러한 작업을 간편해주는 모듈
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['A']) # 'A' 컬럼 기준으로 학습시켜라
le.classes_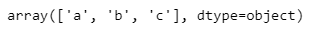
방금 위에서 학습 시킨 le 모델에는 'a', 'b', 'c'라는 class 가 있다.
- transform
le.transform(df['A'])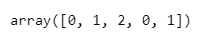
'a', 'b', 'c', 'a', 'b' 가 0, 1, 2, 0, 1로 잘 바뀐 것을 확인 할 수 있다.
- 컬럼에 넣기
df['le_A'] = le.transform(df['A'])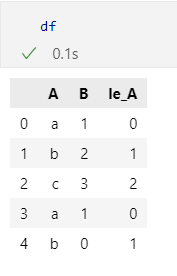
- fit_transform
위에 fit하고 transform한 작업을 한 번에 하는 방법
le.fit_transform(df['A'])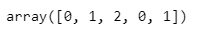
- inverse_transform
fit_transform 작업을 되돌리는 작업(숫자 > 문자)
le.inverse_transform(df['le_A'])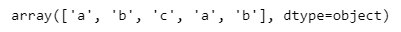
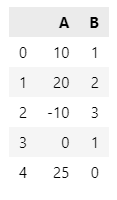
📌min_max scaler
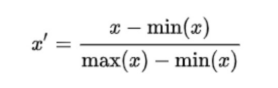
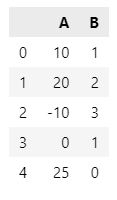
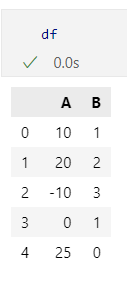
df = pd.DataFrame({'A': [10, 20, -10, 0, 25],
'B': [1, 2, 3, 1, 0]
})
df
- MinMaxScaler fit
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(df)
mms.data_max_, mms.data_min_, mms.data_range_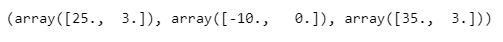
- transform
df_mms = mms.transform(df)
df_mms
- inverse_transform
mms.inverse_transform(df_mms)
📌standard scaler
표준정규분포
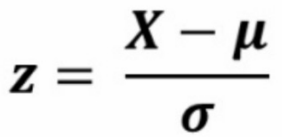
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(df)
- 평균, 표준편차
ss.mean_, ss.scale_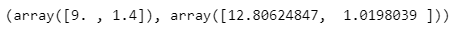
- transform
원래 데이터를 평균은 0, 표준편차는 1인 데이터로 바꾼 것
df_ss = ss.transform(df)
df_ss
📌Robust scaler
평균이 아닌 median을 0로 둔다.
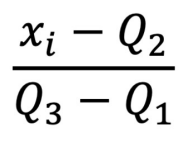
df = pd.DataFrame({'A': [-0.1, 0., 0.1, 0.2, 0.3, 0.4, 1.0, 1.1, 5.0]})
df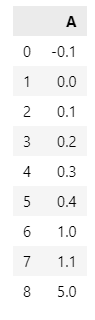
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
mm = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()df_scaler = df.copy()
df_scaler['MinMax'] = mm.fit_transform(df)
df_scaler['Standard'] = ss.fit_transform(df)
df_scaler['Robust'] = rs.fit_transform(df)
df_scaler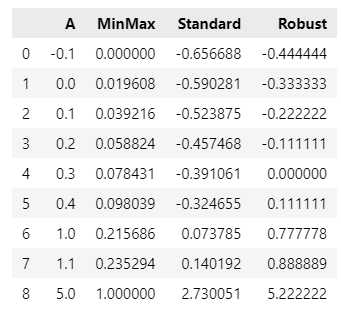
📌 시각화
- boxplot
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style='whitegrid')
plt.figure(figsize=(16, 6))
sns.boxplot(data=df_scaler, orient='h');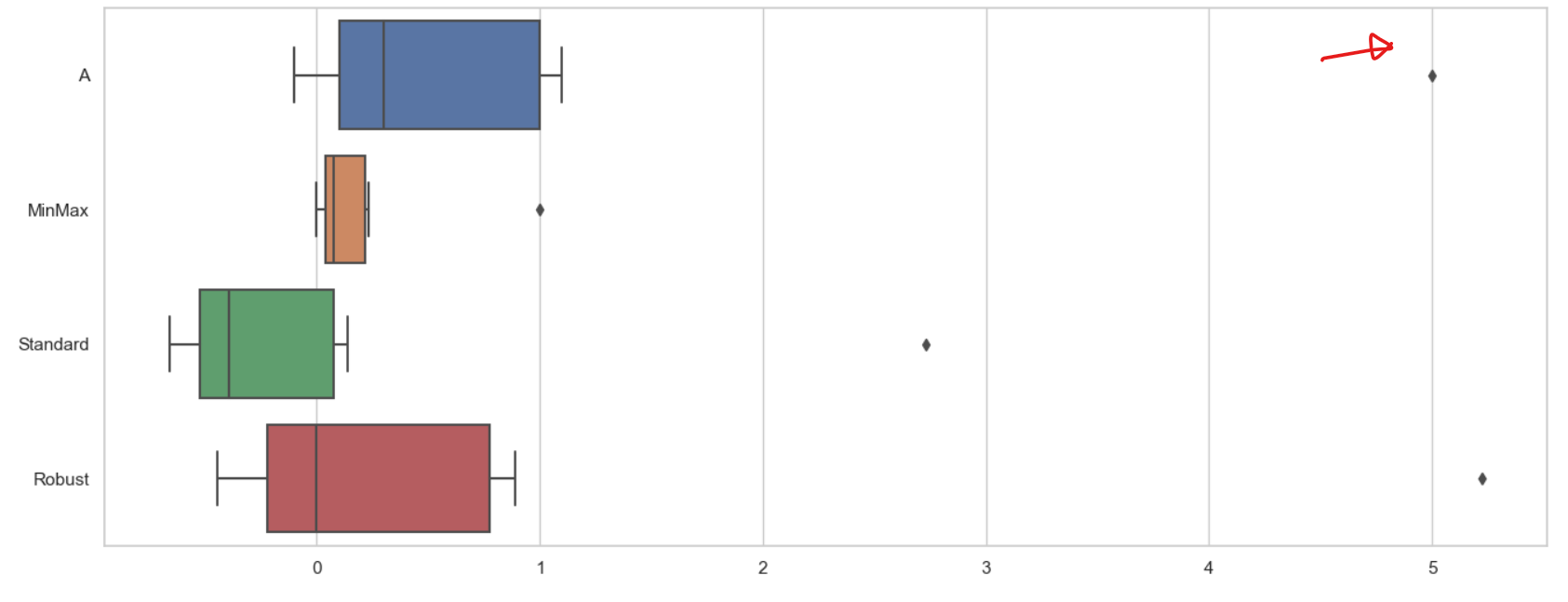
원본 데이터에 outlier가 존재
따라서 5라는 이상치 때문에 MinMax, Standard는 영향을 받아 모양이 이상해졌다.
하지만 Robust는 median을 0으로 두고 길이도 원본 길이에 영향을 받고 있기 때문에 이상치는 그대로 이상치로 남아있다. 그래서 이상치가 Robust에게 영향을 미치지 않았다.
"이 글은 제로베이스 데이터 취업 스쿨 강의를 듣고 작성한 내용으로 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
