📌지도 학습
- 학습 대상이 되는 데이터에 정답(label)을 붙여서 학습 시키고
- 모델을 얻어서 완전히 새로운 데이터에 모델을 사용해서 “답”을 얻고자 하는 것

📌 과적합
- 내가 가진 데이터에만 적합(fit)해져 그 외 데이터(일반적인 데이터)에서 제 성능이 나오지 못하는 것
📌 데이터분리
- 내가 데이터를 가질 수 있는 양은 한계가 있는데 accuracy를 높게 가지게 하는 게 잘못된 것인가! 그럼 어떻게 해야하는 것인가!를 해결할 방법
- 과적합을 해결하기 위해 가진 데이터를 나눠서 학습하는 것
- 최소한 테스트 데이터를 분리하는 것
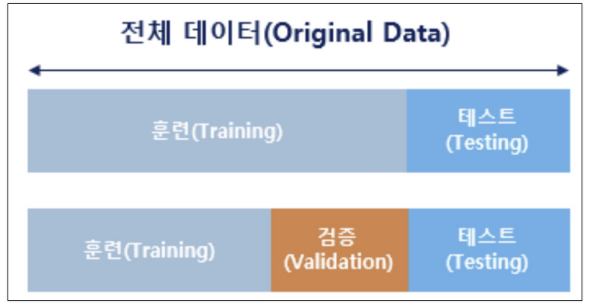
확보한 데이터 중에서 모델 학습에 사용하지 않고 빼둔 데이터를 가지고 모델을 테스트한다
📌Iris
from sklearn.datasets import load_iris # sklearn에서 제공하는 iris 데이터
import pandas as pd
iris = load_iris()- feature 2개
평면에 그리려고 데이터 2개만 사용
from sklearn.model_selection import train_test_split
features = iris.data[:, 2:]
labels = iris.target- train data 80%, test data 20% 추출
# test_size=0.2 -> train data 80%, test data 20%
X_train, X_test , y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=13)X_train.shape, X_test.shape
iris.target_names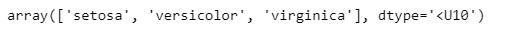
💡꼭 해야할 일
- train, test 데이터의 각각 구성 비율을 확인해야함
iris 데이터로 생각하면 'setosa', 'versicolor', 'virginica'가 각 각 50개씩 있는 150개 데이터라 생각할 때 train 데이터와 test 데이터에 각각 'setosa', 'versicolor', 'virginica' 비율이 어떻게 되는지 확인 해야한다.
import numpy as np- return_counts
각각의 구성비율이 몇개인가
np.unique(y_test, return_counts=True)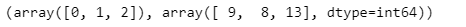
9, 8, 13개로 테스트 데이터가 구성되었다.
테스트 데이터가 각 각 10개 10개 10개 라면 좋을 텐데 9, 8, 13개로 구성되어있다.
이것이 문제인가 생각했을 땐 no! 엔지니어 판단에 달려있다.
But! 일반적으로는 구성 비율을 같게한다. (stratify 사용)
- labels을 기준으로 구성비율을 맞춘다
X_train, X_test , y_train, y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels,
random_state=13)X_train.shape, X_test.shapenp.unique(y_test, return_counts=True)
📍DecisionTree
train 데이터 대상으로 DecisionTree 만들기
- random_state 고정: 학습할 때 마다 일관성을 위해
- max_depth 조정: 모델 단순화 위함 (성능 제한 -> 규제)
- max_depth를 고정하면 성능이 나빠짐(max_depth가 깊을 수록 100%에 가까워지기 때문, 내가 가진 데이터에만 성능이 좋게 만들지 않기 위해 제한)
from sklearn.tree import DecisionTreeClassifieriris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
- DecisionTree 구조
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# iris_tree -> 학습된 모델
# 학습된 모델의 구조 구현
plot_tree(iris_tree);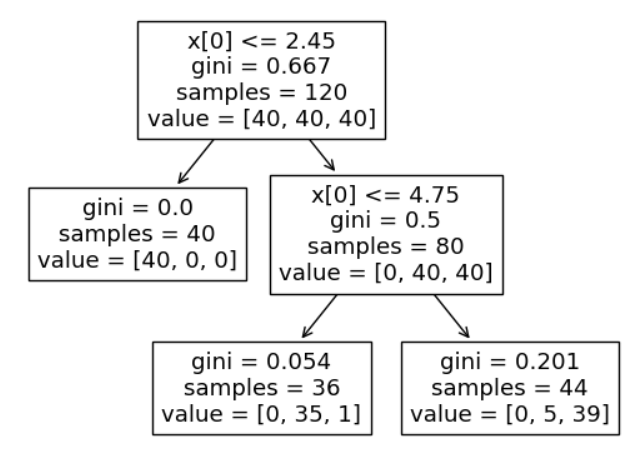
📍accuracy_score 확인
from sklearn.metrics import accuracy_score
# iris_tree -> 학습이 완료된 상태
# iris.data[:, 2:] 데이터를 줄테니 맞춰봐(predict) -> 지금은 정답을 주지 않음
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
# 원래의 참값과, 학습된 결과의 예측값의 정확도
accuracy_score(iris.target, y_pred_tr)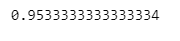
📍결정 경계 확인
train 데이터에 대한 결정 경계 확인
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14, 8))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2)
plt.show()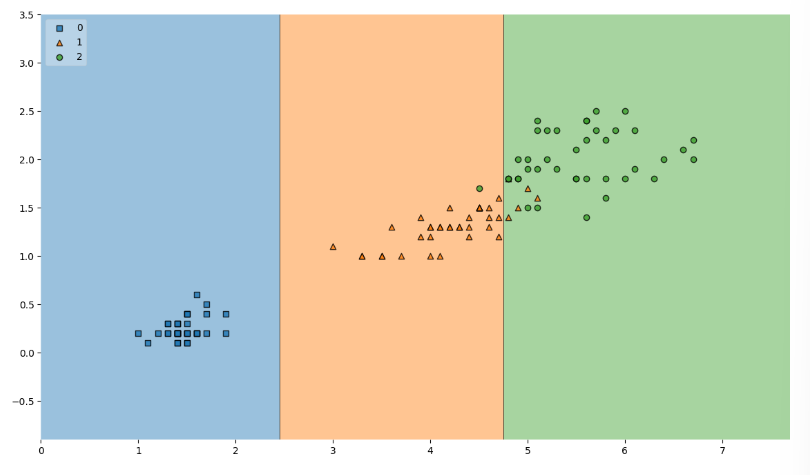
- max_depth를 규제하는 것이 더 많이 틀려 accuracy가 더 낮아졌다. but, 복잡하지 않은 것이 더 좋을 수도 있다.
- max_depth 2가 좋은 것인가 3이 좋은 것인가?도 지금은 알 수 없음
iris는 원래 %가 높게 나옴
지금은 max_depth를 한정하는 것이 좋구나, 데이터를 나누는 것이 좋구나 를 과적합을 막기 위해 생각하는 훈련
⭐중요 작업
내가 가진 train 데이터에서 95%가 나왔으니 test 데이터(일반적인)에서 확인하는 작업 필요
y_pred_test = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_test)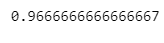
test 데이터 accuracy가 train 데이터 accuracy보다 높아지는 경우는 거의 없다. (iris 데이터라서 test 데이터 accuracy가 높게 나왔다.)
<생각하는 방법>
- 'train accuracy에서 95%가 나왔는데 내가 가진 test accuracy에서 비슷한(근처) %가 나왔으니 일단 과적합은 안일어났구나' 라고 생각
- 아래 그래프에서 한 개가 틀렸다는 중요하지 않다!!
📍시각화
plt.figure(figsize=(14, 8))
plot_decision_regions(X=X_test, y=y_test, clf=iris_tree, legend=2)
plt.show()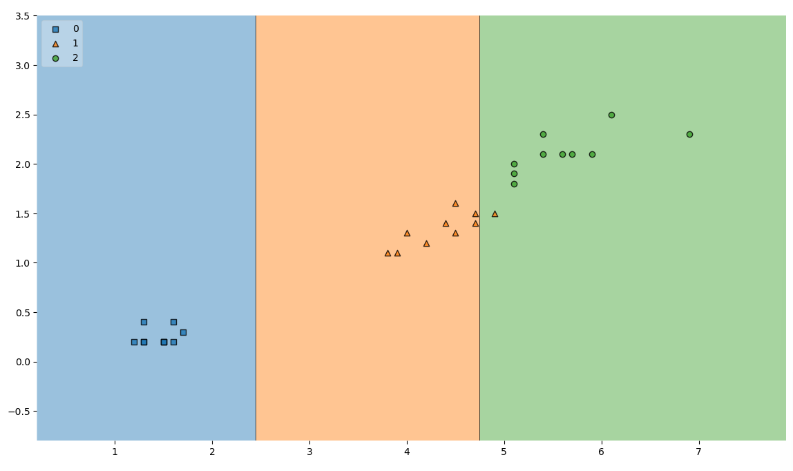
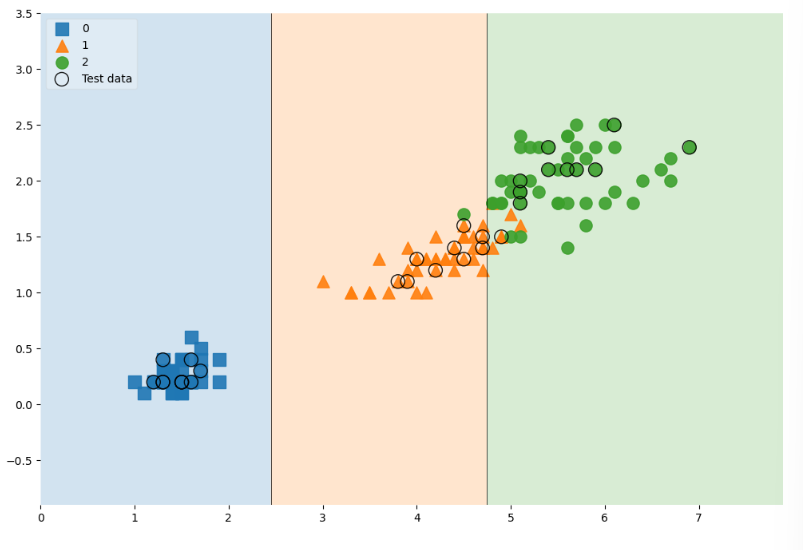
- 150개 데이터 전체를 표기한 다음 train, test 데이터를 분리한 후 강조하고 결정경계까지 넣는 작업
scatter_highlight_kwargs = {'s':150, 'label':'Test data', 'alpha':0.9} # 강조하는 데이터 -> 사이즈, 라벨, 투명도
scatter_kwargs = {'s':120, 'edgecolor':None, 'alpha':0.9} # 일반적 120개 데이터 -> 크기를 작게하고 테두리 선 표시 안함
plt.figure(figsize=(12,8))
plot_decision_regions(X=features, y=labels,
X_highlight=X_test, clf=iris_tree, legend=2,
scatter_highlight_kwargs=scatter_highlight_kwargs,
scatter_kwargs=scatter_kwargs,
contourf_kwargs={'alpha':0.2});
- feature 4개
위에서 2개로 해봤으니 4개로 구해보자
features = iris.data
labels = iris.target
X_train, X_test , y_train, y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels, # labels을 기준으로 구성비율을 맞춘다
random_state=13)
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train) 
plot_tree(iris_tree);
- accuracy 확인
y_pred_tr = iris_tree.predict(iris.data)
# 원래의 참값과, 학습된 결과의 예측값의 정확도
accuracy_score(iris.target, y_pred_tr)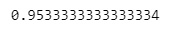
- test 데이터 accuracy
y_pred_test = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_test)
- 모델 사용 방법
- 확률을 아는 방법
test_data가 각 각 'setosa', 'versicolor', 'virginica'일 확률 -> 절대적인건 아님 내가 train시킨 모델에 의한 확률
test_data = [[4.3, 2. , 1.2, 1.0 ]]
iris_tree.predict_proba(test_data)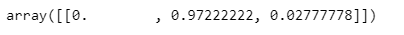
- 예측 결과값을 바로 이름으로 구하기
test_data = [[4.3, 2. , 1.2, 1.0 ]]
iris.target_names[iris_tree.predict(test_data)]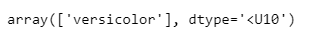
즉 test_data가 versicolor일 확률이 97%이다.
- 주요 특성 확인하기
- featureimportances
데이터를 구분하는데 중요한 특성 확인
maxdepth를 2로 한정한 후 feature_importances 알아보기
iris_tree.feature_importances_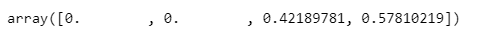
iris_tree = DecisionTreeClassifier(max_depth=5, random_state=13)
iris_tree.fit(X_train, y_train)
iris_tree.feature_importances_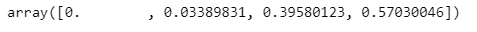
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
# 중요도
dict(zip(iris.feature_names, iris_tree.feature_importances_))
✔️zip
리스트 > 튜플
li1 = ['a', 'b', 'c']
li2 = [1, 2, 3]
pairs = [pair for pair in zip(li1, li2)]
pairs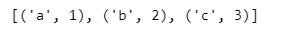
- 튜플 > 딕셔너리
dict(pairs)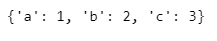
- 리스트 > 튜플 > 딕셔너리
dict(zip(li1, li2))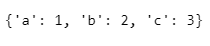
✔️unpacking(*)
위의 작업을 푸는 작업
x, y = zip(*pairs)
print(x)
print(y)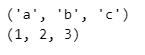
print(list(x))
print(list(y))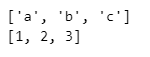
"이 글은 제로베이스 데이터 취업 스쿨 강의를 듣고 작성한 내용으로 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
