📋 Sequence to Sequence with Attention
📌 Seq2Seq Model
- encoder와 decoder로 구성되고 단어의 sequence를 입력으로 받아 단어의 sequence를 출력으로 내뱉는다.
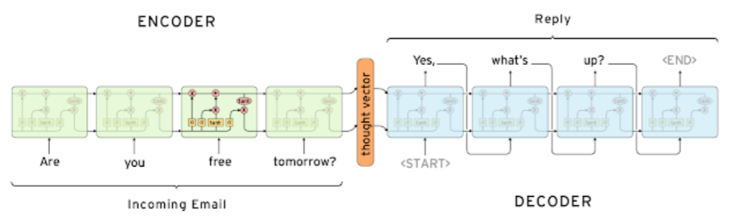
- 단점: sequence의 길이가 길어져도 고정된 크기의 vector에 정보를 담아야 한다 + (Long term dependency)
📌Seq2Seq Model with Attention
- Attention mechanism을 이요해 매 타임 스탭의 decoder가 일부 중요한 source sequence에 집중할 수 있도록한다.
- 이를 통해 bottleneck문제도 해소할 수 있다.
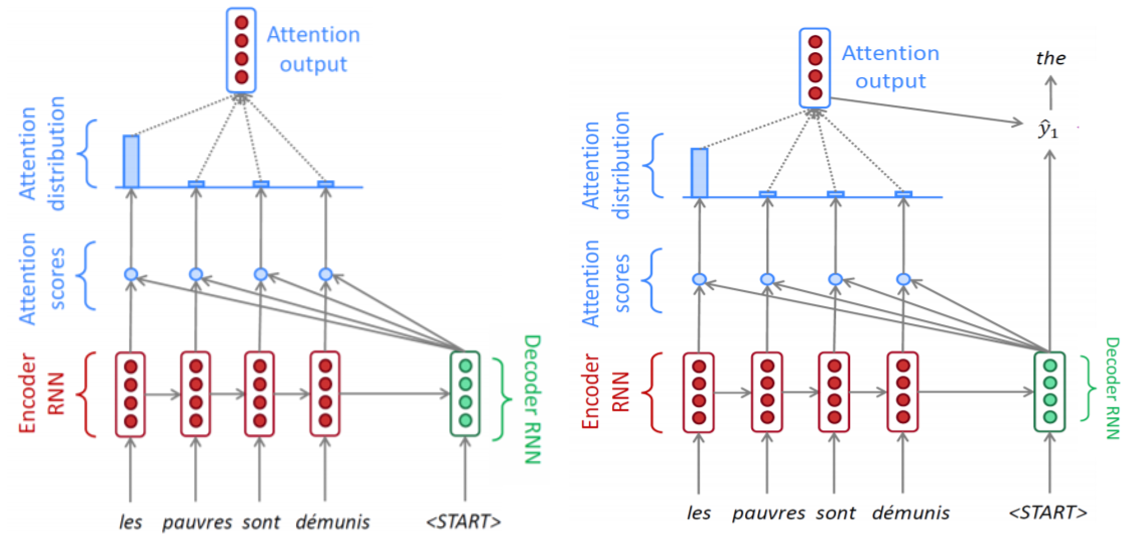
- 각각의encoder hidden state와 decoder hidden state를 내적해서 얻은 확률 분포를 이용한 encoder hidden state 가중합을 구한다.
- 그리고 decoder hidden state와의 concat을 출력값으로 사용한다.
- 이를 통해 loss를 통해 계산되는 gradient가 encoder hidden state로 바로 전달될 수 있게된다.
class DotAttention(nn.Module):
def __init__(self):
super().__init__()
def forward(self, decoder_hidden, encoder_outputs):
query = decoder_hidden.squeeze(0)
key = encoder_outputs.transpose(0, 1)
energy = torch.sum(torch.mul(key, query.unsqueeze(1)), dim=-1)
attn_scores = F.softmax(energy, dim=-1)
attn_values = torch.sum(torch.mul(encoder_outputs.transpose(0, 1), attn_scores.unsqueeze(2)), dim=1)
return attn_values, attn_scores
class Decoder(nn.Module):
def forward(self, batch, encoder_outputs, hidden):
outputs, hidden = self.rnn(batch_emb, hidden)
attn_values, attn_scores = self.attention(hidden, encoder_outputs)
concat_outputs = torch.cat((outputs, attn_values.unsqueeze(0)), dim=-1)
return self.output_linear(concat_outputs).squeeze(0), hidden
📌 Differenct Attention Mechanisms
- 내적이 아닌 추가적인 학습가능한 파라미터 연산을 포함하여 유사도를 측정할 수 있도록하는 Attention Mechanism도 존재한다.
class ConcatAttention(nn.Module):
def __init__(self):
super().__init__()
self.w = nn.Linear(2*hidden_size, hidden_size, bias=False)
self.v = nn.Linear(hidden_size, 1, bias=False)
def forward(self, decoder_hidden, encoder_outputs):
src_max_len = encoder_outputs.shape[0]
decoder_hidden = decoder_hidden.transpose(0, 1).repeat(1, src_max_len, 1)
encoder_outputs = encoder_outputs.transpose(0, 1)
concat_hiddens = torch.cat((decoder_hidden, encoder_outputs), dim=2)
energy = torch.tanh(self.w(concat_hiddens))
attn_scores = F.softmax(self.v(energy), dim=1)
attn_values = torch.sum(torch.mul(encoder_outputs, attn_scores), dim=1)
return attn_values, attn_scores
class Decoder(nn.Module):
def __init__(self, attention):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.attention = attention
self.rnn = nn.GRU(
embedding_size + hidden_size,
hidden_size
)
self.output_linear = nn.Linear(hidden_size, vocab_size)
def forward(self, batch, encoder_outputs, hidden):
batch_emb = self.embedding(batch)
batch_emb = batch_emb.unsqueeze(0)
attn_values, attn_scores = self.attention(hidden, encoder_outputs)
concat_emb = torch.cat((batch_emb, attn_values.unsqueeze(0)), dim=-1)
outputs, hidden = self.rnn(concat_emb, hidden)
return self.output_linear(outputs).squeeze(0), hidden
📋 Beam search
- 이상적으로 translation에서 입력문장이 주어졌을 때 출력 문장 단어들의joint probability가 최대가 되는 선택을 하고싶다.
- 그러나 현재 상태의 최고를 선택하는Greedy한 방법은 최종적으로 좋은 선택이 될 수 없고
- 모든 상황을 고려하는 Exhaustive search의 경우 너무 많은 연산량이 필요로하다.
📌 Beam search
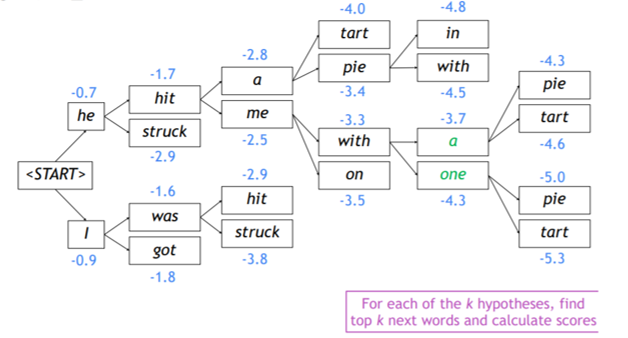
- decoder의 매 time 스탭마다, k개의 가능성있는 일부 translation을 tracking한다.
📋 BLEU score
📌 Precision and Recall
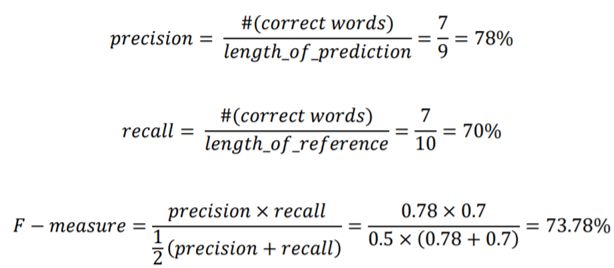
- precision: 예측된 결과가 노출되었을 때 실질적으로 느끼는 정확도
- recall: 실제로 존재하는 정답에 부합하는 정보가 얼마나 빠짐없이 예측되었는지를 나타내는 정확도
- F-measure: precision과 recall의 조화평균에 해당 둘중 작은 값에 조금더 가중치를 매기는 측정방법
- 그러나 이 방법들은 어순에 대한 측정이 불가능함
📌 BiLingual Evaluation Understudy (BLEU)
- N−gram overlap에 대해 측정을 하고
- 4가지 사이즈의 n-gram에 대한 precision측정
- 짧게 예측한 단어가 precision에 대해 유리하기 때문에 brevity penalty 추가

