
Java.util 패키지 - Collection & Map
-
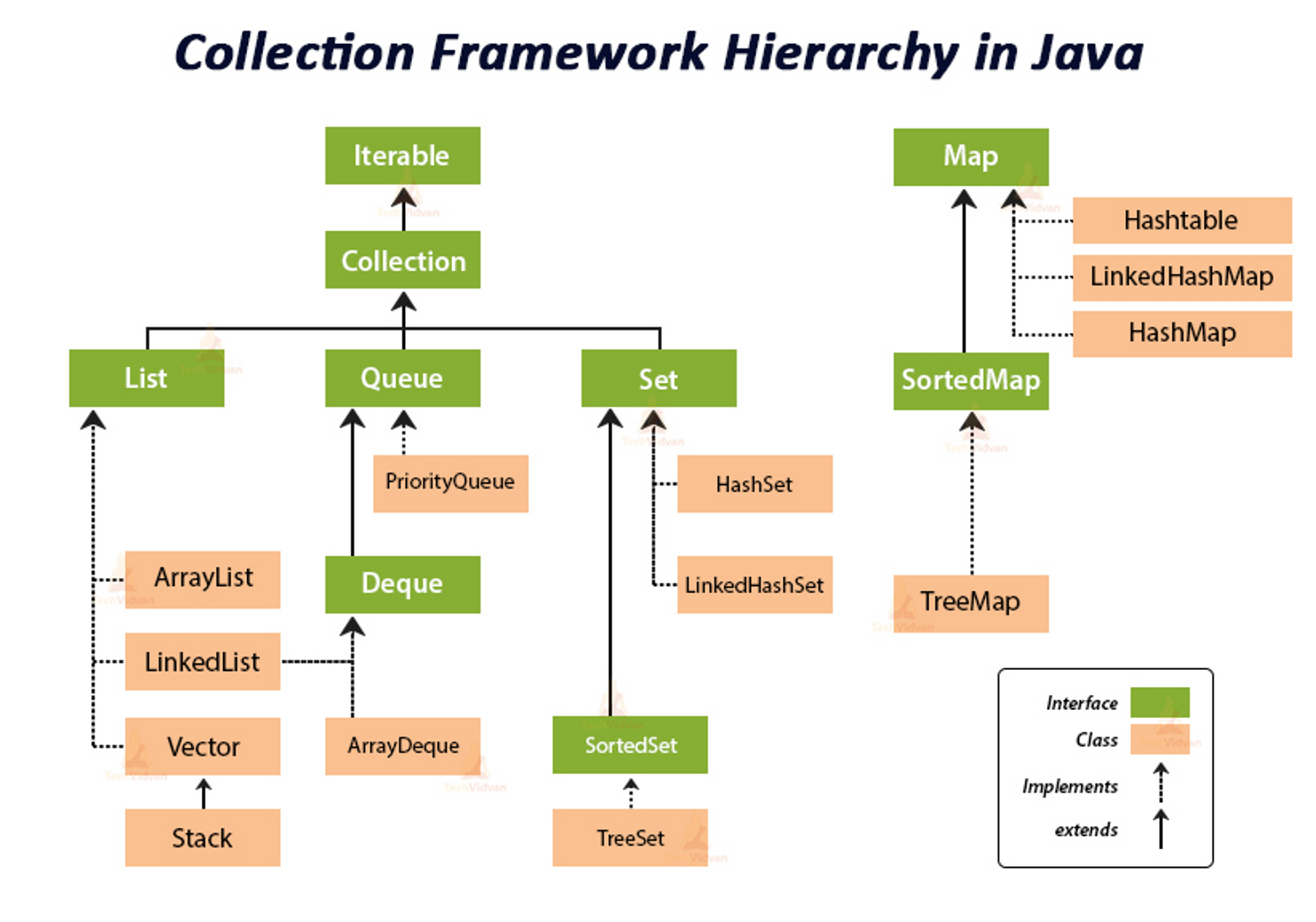
자바의 자료구조는 크게 Collection과 Map으로 나눌 수 있으며, Collection은 List, Set, Queue로 나눌 수 있다.
-
List, Set, Queue는 상위 인터페이스인
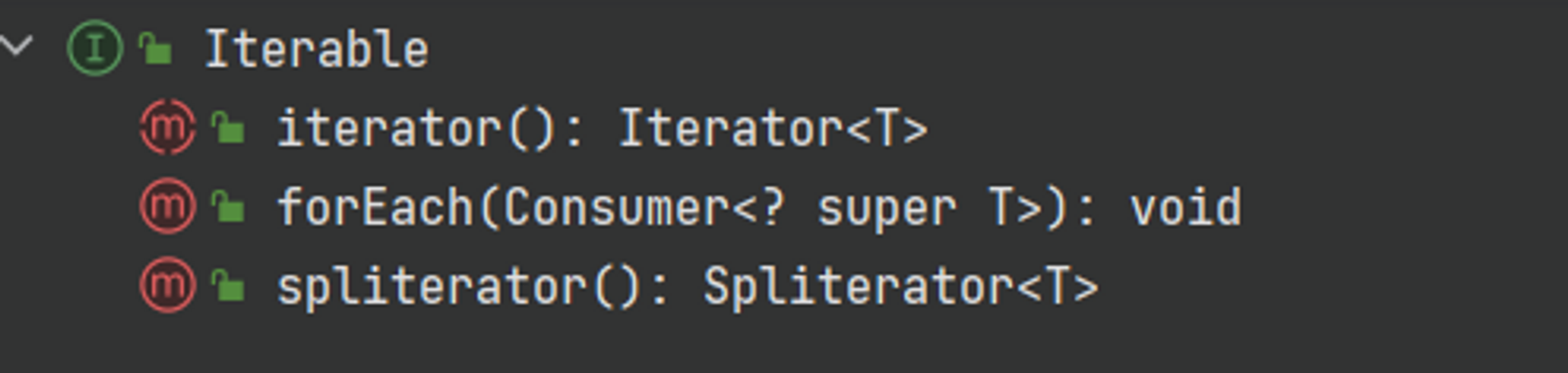
Collection⇒Iterable을 구현하므로 공통적으로 다음과 같은 메서드를 사용할 수 있다.
-
stream() 및 forEach()를 이용할 수 있으며 데이터 추가 및 제거, 형변환 등의 메서드를 제공한다.
Collection 인스턴스에 저장된 데이터 흐름에 대해 람다를 활용해 함수형으로 처리할 수 있다iterator()메소드 호출시 컬랙션 인스턴스의 Iterator객체를 반환하며 Iterator 클래스의 메소드는 다음과 같다.타입 메소드 설명 boolean hasNext() 가져올 객체가 있다면 true를 return, 없다면 false를 return 한다 E next() 하나의 객체를 가져온다 void remove() 객체를 제거한다
Collection 클래스의 구현체
- List :
ArrayList,LinkedList,Vector,Stack - Set :
HashSet,LinkedHashSet,TreeSet - Queue :
priorityQueue,ArrayDeque - Map :
HashMap,LinkedHashMap,Hashtable,TreeMap
1. Collection - List
리스트는 순서를 가지고, 원소의 중복이 허용된다는 특징이 있음


ArrayList
- 배열을 이용하여 만든 리스트
- 기본 크기를 조절할 수 있고, 원소의 갯수가 늘어나 기본크기보다 커지게 되면 더 큰 배열에 옮겨 담는다.
- 배열의 특징 때문에 조회가 빠르다는 장점이 있지만, 삽입/삭제가 느리다는 단점이 있다. ⇒ 조회를 많이하는 경우에 사용하는것이 좋다

LinkedList
-
LinkedList 는 노드(Node)와 포인터(Pointer)를 이용하여 만든 리스트
-
양방향 포인터를 가진다


-
포인터로 각각의 노드들을 연결하고 있어서, 삽입/삭제가 빠르다
-
특정 원소를 조회하기 위해서는 첫 노드부터 순회해야하기 때문에 ArrayList에 비해 느리다
Vector
- ArrayList와 동일한 메서드를 제공하지만 Thread-Safe를 보장한다 ⇒ 멀티스레드 환경에서 사용
- 삽입 및 조회 모두 synchronize하기 때문에 하나의 스레드만 접근이 가능하고 이에따라 스레드가 lock이 걸리게 되어 성능은 ArrayList에 비해 떨어진다
참고로 Collections에서 동기화가 되는 컬렉션을 반환하는 정적 메소드 synchronized…()를 지원한다
Collections.synchronizedList(new ArrayList<>());
Collections.synchronizedSet(new HashSet<>());
Collections.synchronizedMap(new HashMap<>());Stack
스택은 Vector의 하위클래스이고 push()와 pop()은 Stack 클래스 내부에 구현한다.
- Stack은
LIFO(Last-In-First-Out) 특성을 가지는 자료구조이다 - 마지막에 들어온 원소가 처음으로 나가는 특징을 가진다.
- 들어올때는
push, 나갈때는pop이라는 용어를 사용한다 - 스택의 가장 최종적으로 쌓여진 데이터를 확인하기 위해서는
peek()메서드를 사용한다

Collection - Set
Set은 집합이라고 부르며, 순서가 없고 원소의 중복을 허용하지 않는다는 특징이 있음
| 클래스 명 | 특징 |
|---|---|
| HashSet | Hashing을 이용해서 구현한 컬렉션이다.데이터를 중복 저장할 수 없고, 순서를 보장하지 않는다.equals()나 hashCode()를 오버라이딩해서,인스턴스가 달라도 동일 객체를 구분해 중복 저장을 막을 수 있다. |
| TreeSet | 이진탐색트리(Red-Black Tree)의 형태로 데이터를 저장한다. 데이터 추가, 삭제에는 시간이 더 걸리지만, 검색과 정렬이 더 뛰어나다 |
| LinkedHashSet | HashSet 클래스를 상속받으며 .삽입된 순서대로 데이터를 관리한다 |
HashSet(Map)의 hashCode()와 equals()
HashSet(Map)은 같은 인스턴스가 아니더라도 동일 객체를 구분하여 중복 저장을 막을 수 있다.
HashSet에 객체를 저장하기 전에, hashCode()를 호출해 해시코드를 얻어내는데, 이미 저장되어 있는 객체들(HashMap Key 객체)의 경우의 해시코드와 비교해서, 만약 동일한 해시코드가 있다면 다시 equals()로 두 객체를 비교해 true가 나오면 동일한 객체로 판단해 중복 저장을 하지 않는 방식이다.
Collection - Queue
Stack과는 다르게 FIFO(First-In-First-Out) 구조를 가진다. 처음 들어온 원소가 처음으로 나간다는 특징이 있음
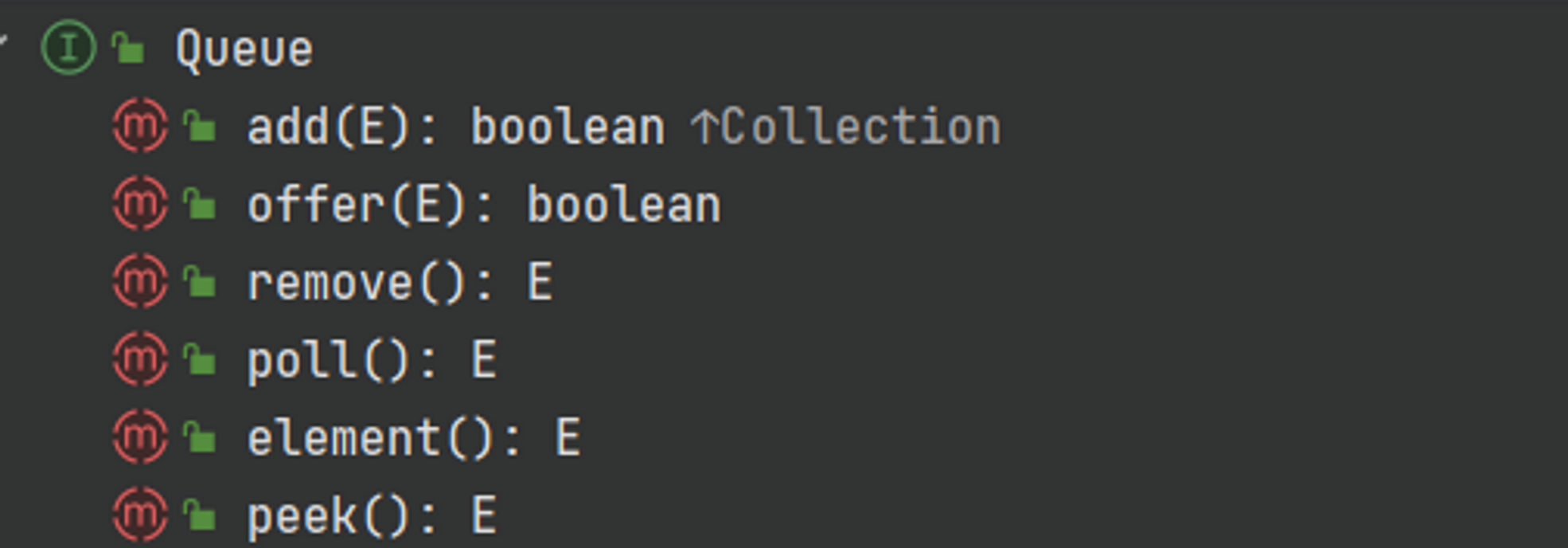
LinkedList
LinkedList의 경우 List뿐만 아니라 Queue, Deque를 함께 구현한다
PriorityQueue
우선순위를 가지는 큐(queue)로 일반적인 큐와는 조금 다르게, 원소에 우선순위를 부여하여 높은 순으로 먼저 반환한다. (이진 트리 구조로 구현되어 있음)
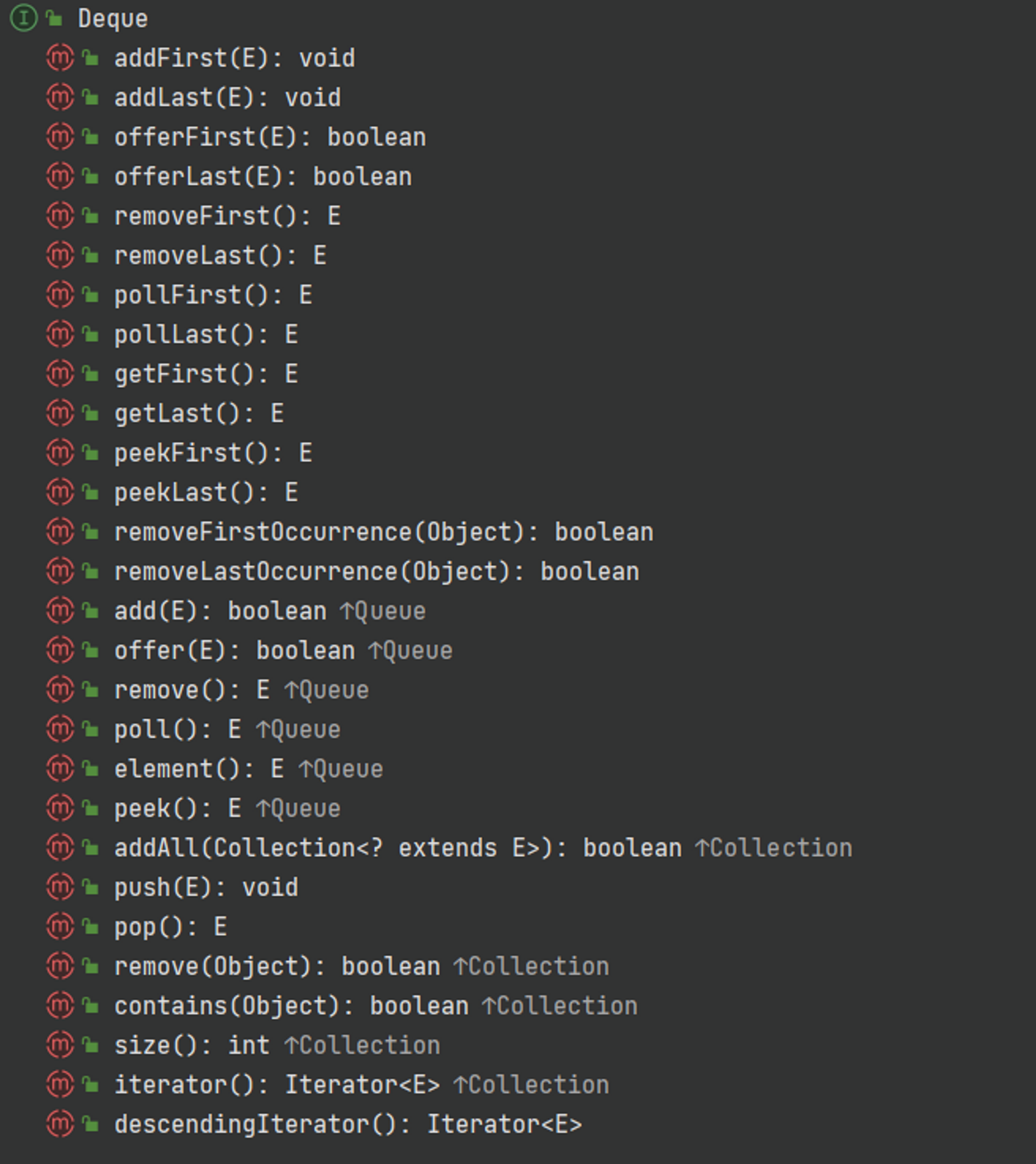
Collection - Deque
Deque는 양쪽으로 넣고 빼는 것이 가능한 큐 자료구조이다.
ArrayDeque, LinkedList ⇒ Deque 인터페이스의 구현체
Map
- Map은 리스트나 배열처럼 순차적으로(sequential) 해당 요소 값을 구하지 않고 key를 통해 value를 얻는다.
- Map은 키와 값으로 구성된 Entry객체를 저장하는 구조를 가지고 있는 자료구조
- 키와 값은 모두 객체이다
- 값은 중복 저장될 수 있지만 키는 중복 저장될 수 없음
- 기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 대치된다(HashTable 제외)
HashMap
- 해시함수를 이용한 Map임
- 삽입 / 삭제 / 조회 연산의 O(1)을 보장하는 아주 빠른 자료구조
- 삽입 데이터의 순서를 보장하지 않음
- 정렬이 불가함
- 주요 메소드
method description. void clear() 해당 맵(map)의 모든 매핑(mapping)을 제거함. boolean containsKey(Object key) 해당 맵이 전달된 키를 포함하고 있는지를 확인함. boolean containsValue(Object value) 해당 맵이 전달된 값에 해당하는 하나 이상의 키를 포함하고 있는지를 확인함. V get(Object key) 해당 맵에서 전달된 키에 대응하는 값을 반환함.만약 해당 맵이 전달된 키를 포함한 매핑을 포함하고 있지 않으면 null을 반환함. boolean isEmpty() 해당 맵이 비어있는지를 확인함. Set keySet() 해당 맵에 포함되어 있는 모든 키로 만들어진 Set 객체를 반환함. V put(K key, V value) 해당 맵에 전달된 키에 대응하는 값으로 특정 값을 매핑함. V remove(Object key) 해당 맵에서 전달된 키에 대응하는 매핑을 제거함. V replace(K key, V value) 해당 맵에서 전달된 키에 대응하는 값을 특정 값으로 대체함. boolean replace(K key, V oldValue, V newValue) 해당 맵에서 특정 값에 대응하는 전달된 키의 값을 새로운 값으로 대체함. int size() 해당 맵의 매핑의 총 개수를 반환함. boolean remove(Object key, Object value) 해당 맵에서 특정 값에 대응하는 특정 키의 매핑을 제거함.
LinkedHashMap
- 삽입 / 삭제가 HashMap보다 느림
- 삽입 순서를 보장함
- 정렬은 불가함
TreeMap
- 삽입 / 삭제가 굉장히 느림,
- 삽입순서를 보장함
- Map이지만 유일하게 정렬이 가능함
- 주요 메소드
method description NavigableMap<K, V> descendingMap() 모든 맵을 역순으로 반환함. NavigableSet<k, > </k,>descendingKeySet() 모든 키를 역순으로 반환함. K firstKey() 해당 맵에서 현재 가장 작은(첫 번째) 키를 반환함. K lastKey() 해당 맵에서 현재 가장 큰(마지막) 키를 반환함. K higherKey(K key) 해당 맵에서 전달된 키보다 작은 키 중에서 가장 큰 키를 반환함.만약 해당하는 키가 없으면 null을 반환함. K lowerKey(K key) 해당 맵에서 전달된 키보다 큰 키 중에서 가장 작은 키를 반환함.만약 해당하는 키가 없으면 null을 반환함. K ceilingKey(K key) 해당 맵에서 전달된 키와 같거나, 전달된 키보다 큰 키를 반환함. 없으면 null을 반환함. K floorKey(K key) 해당 맵에서 전달된 키와 같거나, 전달된 키보다 작은 키를 반환함. 없으면 null을 반환함. SortedMap<K, V> headMap(K toKey) 해당 맵에서 전달된 키보다 작은 키로 구성된 부분만을 반환함. SortedMap<K, V> subMap(K fromKey, K toKey) 해당 맵에서 fromKey(포함)부터 toKey(미포함)까지로 구성된 부분만을 반환함. SortedMap<K, V> tailMap(K fromKey) 해당 맵에서 fromKey와 같거나, fromKey보다 큰 키로 구성된 부분만을 반환함.
java.util.concurrent 패키지 - 동시성 컬랙션
Synchronized Collection vs Concurrent Collection
공통점
- 스레드 안정성(Thread-safety) 보장
차이점
- 성능(performance)
- 확장성(scalability)
- 스레드 안정성을 확보하는 방법(how they achieve thread-safety)
Synchronized Collection
한 번에 하나의 스레드만 객체에 접근하도록 허용한다.
synchronized object는 여러 스레드에 의해 동시에 조작될 수 없다.
대표 컬렉션
- Vector
- Hashtable
- SynchronizedXXX( HashMap, HashSet, ArrayList, ...)
특징
1. 성능
- Concurrent Collection보다 성능이 낮다.
- Collection 전체 객체(Map이나 List)에 락을 건다.
2. 스레드 안정성 확보 방법
- public 메서드에 synchronized 키워드를 사용하여 내부의 값을 한 스레드만 사용할 수 있도록 제어한다.
- 해시테이블의 사이즈와 상관없이 iteration이나 쓰기 연산 때 전체 컬렉션 인스턴스 전체에 락을 건다.
3. 확장성
- 컬렉션 전반에 거는 하나의 락은 확장성에 장애물이 된다.
- ConcurrentModificationException을 피하기 위한 스레드 대기 시간이 길어진다.
종류
Vector
package java.util;
public class Vector<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
...
public synchronized boolean add(E e) {
modCount++;
add(e, elementData, elementCount);
return true;
}
public synchronized int size() {
return elementCount;
}
...
}Hashtable
package java.util;
public class Hashtable<K,V>extends Dictionary<K,V>implements Map<K,V>, Cloneable, java.io.Serializable {
...
@SuppressWarnings("unchecked")
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
public synchronized int size() {
return count;
}
...
}Collections.synchronizedXXX()
package java.util;
public class Collections {
...
public static <T> List<T> synchronizedList(List<T> list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
public static <T> Set<T> synchronizedSet(Set<T> s) {
return new SynchronizedSet<>(s);
}
static class SynchronizedList<E>extends SynchronizedCollection<E>implements List<E> {
@SuppressWarnings("serial") // Conditionally serializable
final List<E> list;
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
...
}
...
}List<String> list = Collections.synchronizedList(new ArrayList<String>());-
SynchronizedList 내부 클래스를 보면 모든 메서드의 각 synchronized 블록에서 mutex 객체를 공유한다. 한 스레드가 synchronized 블록에 들어가는 순간 다른 메서드의 syncrhonized 블록이 lock에 걸리기 때문에 다른 스레드들은 모두 동기화 메서드를 이용하지 못하고 blocking 상태가 된다.
-
읽기와 쓰기 동작 시 모두 인스턴스 자체에 잠금이 걸린다.
Concurrent Collection
concurrent
- 여러 스레드가 한 객체에 동시에 접근할 수 있다.
대표 컬렉션
- ConcurrentHashMap
- CopyOnWriteArrayList
- CopyOnWriteHashSet, ..
특징
1. 성능
- Synchronized Collection보다 높은 성능
- 절대 전체 Map이나 List에 lock을 걸지 않는다.
- 여러 스레드가 한 번에 접근 가능하기 때문에 스레드 대기 시간을 줄여준다.
- 하나 이상의 스레드가 concurrent하게 read, write 연산을 할 수 있다.
2. 스레드 안정성 확보 방법
- Lock Stripping 같은 정교한 기법
- ConcurrentHashMap
- 전체 Map을 여러 조각으로 나눈다.
- 관련된 부분들에만 락을 건다.
- 해당 컬렉션의 락이 걸리지 않은 다른 조각들에 여러 스레드들이 접근할 수 있다.
- CopyOnWriteArrayList
- read: synchronization 없이 여러 읽기 스레드들이 읽을 수 있다.
- write: 전체 ArrayList를 복사하고 더 최신 컬렉션과 바꾼다.
3. 확장성
- 읽기 연산이 쓰기 연산보다 많이 일어나는 등의 더 필요한 상황에 맞게 concurrent collection 클래스를 골라 사용할 수 있다.
- 더 높은 동시성(concurrency)과 확장성
종류
CopyOnWriteArrayList
- 모든 쓰기 동작 시 원본 배열의 요소를 복사하여 새로운 임시 배열을 만들고, 임시 배열에 쓰기 동작을 수행한 후 원본 배열을 갱신한다.
- 명시적 락 사용
- 읽기 동작은 lock이 걸리지 않는다.
- 비용이 높은 배열 복사 작업이 있기 때문에 쓰기 작업이 많은 경우 성능 이슈가 발생할 수 있다.
ConcurrentHashMap
- 자바 8 이전
- ReentrantLock을 상속받는 Segment를 이용하여 영역을 구분하고 영역별로 잠금
- 자바 8 이후
- 각 테이블 버킷을 독립적으로 잠금
- 빈 버킷에 노드를 삽입할 경우 lock 대신 CAS 알고리즘
- 그 외 변경은 각 버킷의 첫번째 노드를 기준으로 부분적인 잠금(synchronized block)을 획득
- 스레드 경합 최소화
