HashMap의 구조 및 원리
- HashMap은 데이터를 Key - Value의 쌍으로 저장하며 키에 대한 해시 값을 활용하여 내부적으로 배열의 특정 인덱스를 접근하여 O(1)에 해당하는 속도로 데이터를 조회, 추가, 삭제할 수 있는 자료구조이다.
- 실제로는 key값을
(hash(key)& n - 1)으로 계산해서 인덱스로 사용한다. - 즉 HashMap은 내부에 Node<Key, Value>클래스(해쉬 버킷 ⇒
Entry의LinkedList)의 배열인 자료구조이다transient Node<K,V>[] table; static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } ... } - LinkedList를 사용하는 이유 ⇒ 해시 충돌이 났을 경우 next 에 그 값을 넣어주기 위해서
- 자바에서는 데이터에 대한 해쉬 값이
2^32가지의 정수형을 가질 수 있다. - 문제는 데이터의 종류는 사실상 무한하기 때문에 서로다른 데이터가 같은 해쉬 값을 가지는 경우가 생기고 이 경우를 hash Collision(해쉬 충돌)이라고 한다. 일반적으로 해쉬 함수는 해쉬 충돌을 줄일 수 있는 방향을 추구해야한다.
- 자바에서는 데이터에 대한 해쉬 값이
- HashMap 필드값
// 헤쉬 테이블(버킷 어레이) transient Node<K,V>[] table; // 엔트리 셋 transient Set<Map.Entry<K,V>> entrySet; // 저장된 Node의 갯수 transient int size; /** * The number of times this HashMap has been structurally modified * Structural modifications are those that change the number of mappings in * the HashMap or otherwise modify its internal structure (e.g., * rehash). This field is used to make iterators on Collection-views of * the HashMap fail-fast. (See ConcurrentModificationException). */ transient int modCount; //해시 테이블 재구축 기준 int threshold; //해시 테이블 재구축 기준 비율 final float loadFactor; // 기본 테이블 버킷 수 16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 최대 테이블 버킷 수 2^30 static final int MAXIMUM_CAPACITY = 1 << 30; // 기본 load_factor static final float DEFAULT_LOAD_FACTOR = 0.75f; ...
Hash Collision Soultion
Sequence Chaining
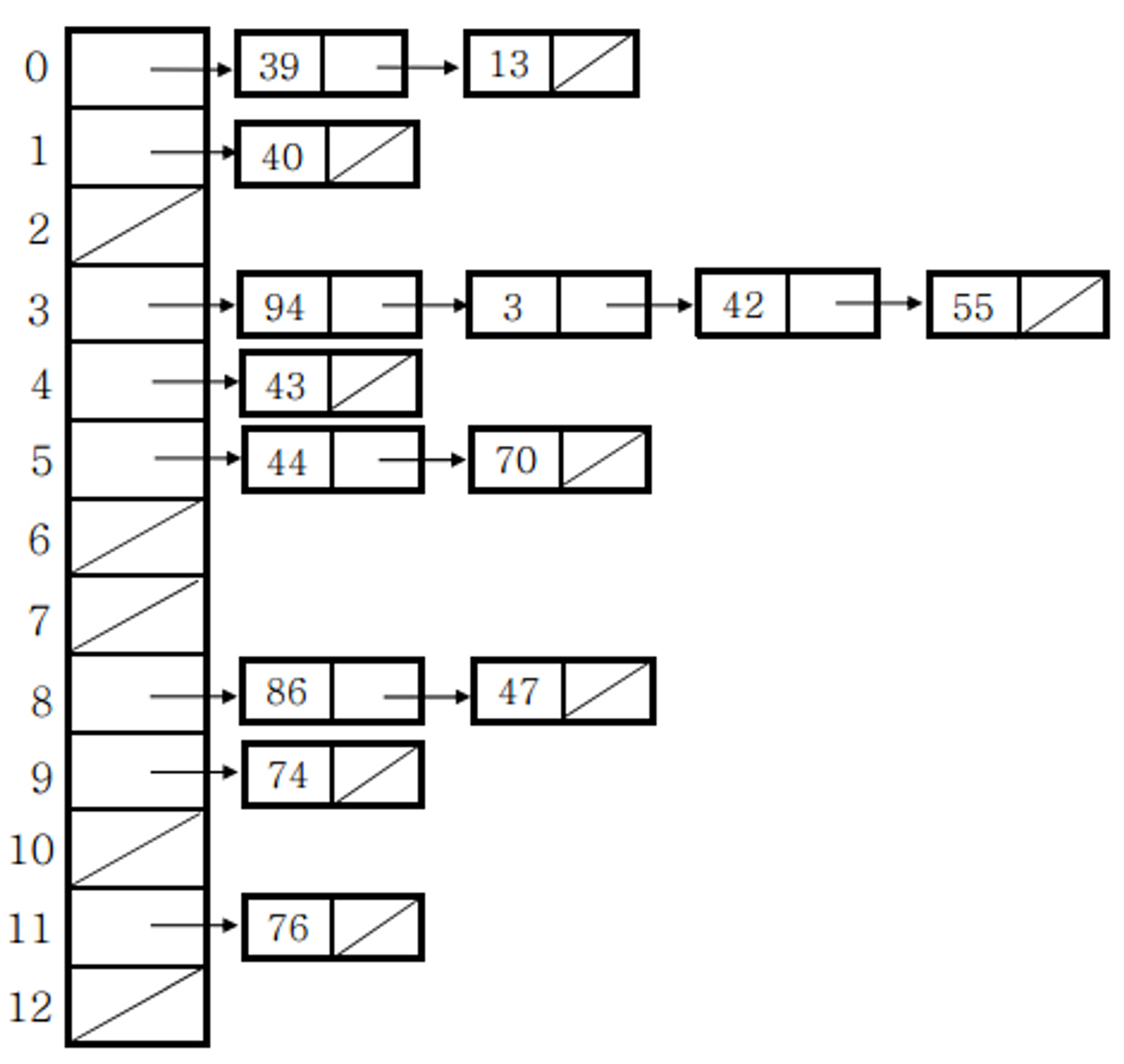
내부에 해쉬 버켓이라는 데이터를 담는 Node<key, value> 배열을 가지고 있다.
-
먼저, 미리정의된 객체(key)의 HashCode함수와 해쉬 버켓의 크기(N)를 활용하여 key에 대한 해시값을 구한다.
int index = key.hashCode() % N -
index값에 해당하는 배열에 위치에 접근하여 데이터를 추가한다
-
해당위치에 이미 데이터가 있다면 해당위치에 데이터를 추가할 수 없으므로 해당 위치데이터의 링크드리스트를 따라가면서
- 자신의 key값과 같은 데이터가 있다면 덮어씌우고
- 없다면 다음으로 계속 이동하면서 같은 데이터를 발견하지 못했을 경우 마지막에 데이터를 추가한다.
해쉬 버켓 중첩 문제
위에서 설명한 것 처럼 데이터를 추가할 때 최악의 경우 서로 다른 데이터가 같은 index값으로 결정되고 하나의 버켓에 몰려 chain의 길이가 요소의 전체개수에 비례하는 경우가 생길 수 있다 이 경우 검색, 삭제, 삽입 모두에서 O(N)의 시간복잡도가 발생할 수 있다.
- 해시 버킷 동적 확장 ⇒ HashMap은 키-값 쌍 데이터 개수(size)가 threshold(load factor * 현재의 해시 버킷 개수)이상이 되면, 해시 버킷의 개수를 두 배로 늘린 배열을 재할당 한다.
- 보조해쉬 함수 사용 ⇒ 배열의 크기를 2배씩 늘릴 경우 해쉬 버켓의 크기가 2^n 곱을 가지기 때문에 hashCode()의 하위특정 비트만 사용하게 되고 해쉬 충돌이 쉽게 발생할 수 있다. ⇒ 따라서 다음과 같은 보조 해쉬 함수를 활용하여 균등한 분포를 만들어준다.
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
HashMap 구현 분석
put()
// HashMap 의 대표적인 함수인 put() 함수를 호출하면 putVal() 함수가 호출된다.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 이 함수에서 데이터 삽입 로직을 처리한다.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 처음 생성된 해시맵이거나 길이가 0인 해시맵이라면 resize() 한다.
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 해시맵에 이미 존재하는 Key 값인지 해시를 이용해 검색한다.
// 만약 존재 하지 않는 해시값이라면 해시맵 테이블에 Value 를 넣어준다.
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 만약 존재하는 해시 값이라면, 키 값이 같아서 해시 값이 같은건지, 아니면 키 값이 다른데
// 해시 값이 같아서 해시 충돌이 난건지를 아래에서 구분할 것이다.
else {
Node<K,V> e; K k;
// 같은 키 값을 사용한 경우다.
// 테이블에 변화를 줄 필요는 없고 put 함수의 리턴 값으로 중복된 value 를 다시 넘겨준다.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// TreeNode 일 경우. 아직 확인 안 해본 코드.
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 해시 충돌이 난 경우: 다른 키 값을 사용했는데 해시가 겹침.
else {
for (int binCount = 0; ; ++binCount) {
// 해당 키값으로 처음 해시 충돌이 난 경우라면 next 에 그 Value 를 넣어준다.
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 해시 충돌이 나서 이미 해시맵에 들어갔던 Value 라면 Break 해서 코드 탈출
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 값은 키 값을 사용해서 해시가 같았던 경우다. 중복된 value 값을 반환하는 코드.
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 이벤트 콜백성 코드
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
// 이벤트 콜백성 코드
afterNodeInsertion(evict);
return null;
}get()
public V get(Object key) {
Node<K,V> e;
return (e = getNode(key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods.
*
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n, hash; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & (hash = hash(key))]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// next 필드가 존재 한다는 것은 해시 충돌이 났었다는 것이다. 해시 충돌이 난 value 를 반환.
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}resize()
해시맵 버킷 사이즈가 일정 수준으로 차면 배열의 크기를 증가시킨다. 보통 두 배로 확장한다. 확장하는 임계점은 75%이다. 코드에서도 확인 해보면 static final float DEFAULT_LOAD_FACTOR = 0.75f; 와 같이 구현되어 있다. 리사이징은 더 큰 버킷을 가지는 새로운 배열을 만들고 거기에 hash 를 다시 계산해서 복사해준다.
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 이 코드에서 HashMap 의 맥스 사이즈를 체크한다.
// MAXIMUM_CAPACITY = 1 << 30 = 1073741824 를 넘는지 검사해서 넘는다면
// threshold 값을 MAX Integer 로 설정한다.
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// 해시맵 처음 Default 셋팅!
// Default bucket의 수 : 16, loadFactor = 0.75f, threshold = 12
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}